
Die als X3D bekannte Technologie ist eine der wichtigsten für AMD für die Zukunft, wenn nicht die wichtigste, da hiermit die verschiedenen Elemente ihrer Prozessoren miteinander kommunizieren. Seine Bedeutung liegt in der Tatsache, dass es die Infinity Fabric-Technologie ersetzen wird, und obwohl es sich immer noch an einem Horizont befindet, der weit weg zu sein scheint, haben wir es jeden Tag näher.
Angesichts der Entwicklung des Exascale Heterogenic Processor, der für AMD der Schlüssel zum Gewinn des Bauauftrags für El Capitan war, mussten sie eine neue Art von Schnittstelle schaffen, damit die Kommunikation zwischen dem CPU und für GPU Dies kann in einer Umgebung durchgeführt werden, in der beide denselben Speicher gut gemeinsam nutzen. Dies hat AMD gezwungen, eine neue Art von Kommunikationsschnittstelle zu entwickeln, um ein Problem zu lösen, das AMD bisher nicht lösen konnte.
Warum haben wir noch keine Chiplet-basierte GPU gesehen?

Der Grund, warum wir keine dedizierten GPUs in einem MCM gesehen haben, der den Speicherzugriff mit der CPU teilt, ist, dass die vom IOD bereitgestellte Bandbreite nicht groß genug ist, um eine GPU mit Strom zu versorgen. Im Fall eines MCM mit dem einheitlichen Speichersystem sprechen wir über die Anwendung des Infinity-Cache der GPU als L4 des Systems.
Warum reicht der Infinity Fabric nicht aus? Nun, aufgrund der Tatsache, dass es uns eine Schnittstelle von 32 oder 64 Bytes / Zyklus gibt, abhängig von der Version
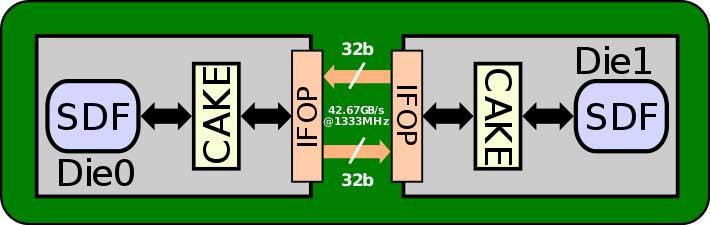
Stellen Sie sich nun vor, wir möchten ein Navi 21 (RX 6800, RX 6800 XT und RX 6900 XT) verbinden. Dabei müssen wir berücksichtigen, dass zwischen dem L2-Cache in der GPU und dem Infinity-Cache 16 Partitionen des L2-Cache mit einer Bandbreite vorhanden sind Jeweils 64 Bytes / Zyklus, das sind insgesamt etwa 1024 Bytes / Zyklus und damit eine 8192-Bit-Schnittstelle, die AMD-Ingenieure dazu zwingt, eine Kommunikationsschnittstelle zu entwickeln, die viel komplexer als die Infinity Fabric ist, um eine GPU über die gleicher Speicherpool.
Das Problem mit dem Infinity Fabric bei der externen Kommunikation mehrerer Chips besteht darin, dass es sich bei einer horizontalen 2D-Verbindung um eine begrenzte Anzahl von Pins handelt, die platziert werden können, ohne den Umfang des Chips stark zu vergrößern. Die andere Option, wenn wir die Bandbreite erhöhen möchten, besteht darin, die Taktrate jedes Pins zu erhöhen. Dies würde jedoch den Energieverbrauch erheblich erhöhen, was dazu führen würde, dass das Budget überschritten wird.
X3D, der Ersatz für das Infinity Fabric
 Das Problem mit dem Infinity Fabric ist, dass es nicht dazu dient, die Chips vertikal zu kommunizieren Daher wird die hervorragende Beziehung zwischen Bandbreite und Energieverbrauch der vertikalen Schnittstellen, die die Pfade durch Silizium verwenden, nicht ausgenutzt, und mit diesem Problem steht AMD ganz oben auf der Tabelle, mit der die Entwicklung für die Zukunft abgeschlossen ist der Infinity Fabric.
Das Problem mit dem Infinity Fabric ist, dass es nicht dazu dient, die Chips vertikal zu kommunizieren Daher wird die hervorragende Beziehung zwischen Bandbreite und Energieverbrauch der vertikalen Schnittstellen, die die Pfade durch Silizium verwenden, nicht ausgenutzt, und mit diesem Problem steht AMD ganz oben auf der Tabelle, mit der die Entwicklung für die Zukunft abgeschlossen ist der Infinity Fabric.
Als AMD den X3D ankündigte, dachten viele, es sei eine Art Verpackung, es ist wirklich nicht so, sondern es wäre eine neue Art der Verbindung wie das Infinity Fabric , nur dass es vertikal auf einem Interposer funktionieren würde, in einer Konfiguration, die der in Chips mit HBM-Speicher verwendeten sehr ähnlich ist.
Die Idee ist, eine Kommunikationsschnittstelle mit einem Energieverbrauch nahe 0.2 pJ / Bit zu haben, die eine zehnmal höhere Bandbreite bei gleichem Energieverbrauch wie das Infinity Fabric ermöglicht.
Tatsächlich bleibt AMD im Vergleich zu Intel zurück
 Die Technologie, die AMD entwickelt, ist eine Antwort darauf Intel Foveros, wo Intel es bereits geschafft hat, eine Art von Verbindung des gleichen Typs unter einem Verbrauch von 0.15 pJ / Bit zu entwickeln Man kann also sagen, dass Lisa Su hinterherhinkt und wie Intel wissen sie, dass die Chips der Zukunft von der Verwendung neuer Arten von Verbindungen abhängen, die das Design der verschiedenen Prozessoren zu einem Paradigmenwechsel führen.
Die Technologie, die AMD entwickelt, ist eine Antwort darauf Intel Foveros, wo Intel es bereits geschafft hat, eine Art von Verbindung des gleichen Typs unter einem Verbrauch von 0.15 pJ / Bit zu entwickeln Man kann also sagen, dass Lisa Su hinterherhinkt und wie Intel wissen sie, dass die Chips der Zukunft von der Verwendung neuer Arten von Verbindungen abhängen, die das Design der verschiedenen Prozessoren zu einem Paradigmenwechsel führen.
Aber Der Grund für diese Technologien liegt in der Entwicklung von Supercomputern mit der Fähigkeit, die Rate von 1 ExaFLOPS zu erreichen Dies ist unter dem Gesichtspunkt der Ausführung der Anweisungen einfach, aber fast unmöglich, wenn wir über die Energiekosten des Speichers sprechen. Dazu müssen wir ein Konzept einführen, das das von ist arithmetische Intensität .
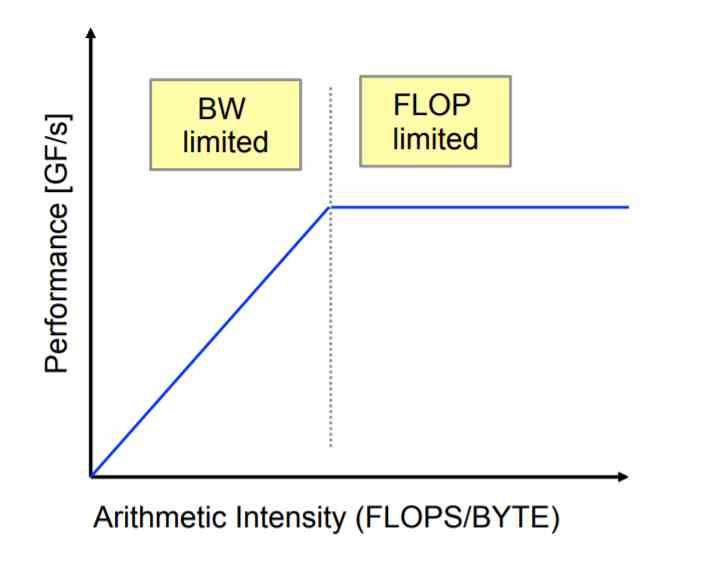
Die Idee ist, dass eine Architektur durch die Anzahl der durchgeführten Operationen so begrenzt sein kann wie durch die Bandbreite, die für diese Operationen benötigt wird . Wenn wir die Verarbeitungskapazität stark erhöhen, müssen wir dies natürlich auch mit dem Speicher tun. Aber ist der Speicher, den wir haben, ausreichend, um bei der Verarbeitung skaliert zu werden?
Die Evolution RAM war jedes Mal, wenn ein neuer Fertigungsknoten erscheint, sehr eintönig, wodurch der Energieverbrauch bei der Datenübertragung gesenkt werden kann. Die Geschwindigkeit, mit der sich RAM entwickelt, ist jedoch nicht schnell genug, um den Herausforderungen zu begegnen, denen sich Prozessorhersteller wie Intel und AMD gegenübersehen sie, um das Problem selbst zu beheben.
Die Notwendigkeit für eine neue Art von RAM
 Wir haben lange auf das HBM Next Gen oder HBM3 gewartet , seine Spezifikation wurde für eine lange Zeit eingefroren und der Grund dafür ist dass jeder der großen Prozessorhersteller (AMD, Intel und NVIDIA) entwickeln ihren eigenen „HBM3“ -Speicher . Im Fall von AMD würden sie die Entwicklung dieses Speichertyps auf die Erstellung eines 3D-DRAM mit einer Kommunikationsschnittstelle basierend auf der X3D-Schnittstelle stützen, die sie zum ersten Mal im El Capitan-Supercomputer anwenden werden.
Wir haben lange auf das HBM Next Gen oder HBM3 gewartet , seine Spezifikation wurde für eine lange Zeit eingefroren und der Grund dafür ist dass jeder der großen Prozessorhersteller (AMD, Intel und NVIDIA) entwickeln ihren eigenen „HBM3“ -Speicher . Im Fall von AMD würden sie die Entwicklung dieses Speichertyps auf die Erstellung eines 3D-DRAM mit einer Kommunikationsschnittstelle basierend auf der X3D-Schnittstelle stützen, die sie zum ersten Mal im El Capitan-Supercomputer anwenden werden.
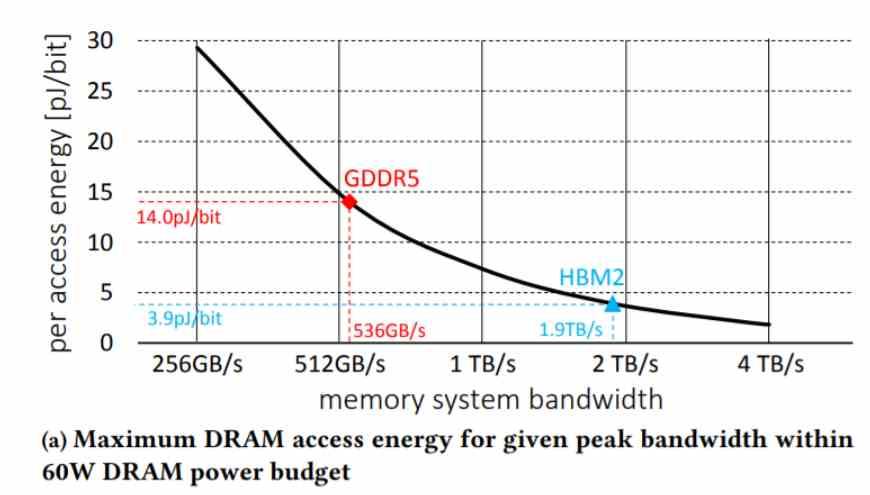
Das Problem ist, dass jedes System eine Bandbreite hat, die durch den dem System zugewiesenen Energieverbrauch begrenzt ist, und unabhängig davon, wie stark wir die Bandbreite erhöhen, erreichen wir den Punkt, an dem wir sie aufgrund des Energieverbrauchs des Speichers nicht mehr erhöhen können ist zu hoch, daher werden kontinuierlich Speicher mit einer immer niedrigeren pJ / Bit-Zahl entwickelt.
Aber was verbraucht am meisten Energie? Die Kommunikationsschnittstellen, die zum Verschieben der Daten verwendet werden, sollen einen Wert von pJ / Bit erreichen, der niedrig genug ist, um nicht nur die GPU-Chiplets problemlos zu kommunizieren, sondern auch Speicher mit hoher Bandbreite zu erstellen, ohne den Verbrauch erheblich zu erhöhen.
X3D DRAM Speicher?

Wenn Sie die Verpackungs-Roadmap von AMD gesehen haben, denken Sie vielleicht von Anfang an, dass der im X3D-Konzept gestapelte Speicher eine Art HBM-Speicher ist, aber das ist es wirklich nicht.
Es ist eine Art Speicher, der als Ersatz für das aktuelle HBM2e erstellt wurde dass AMD intern in der Entwicklung des EHP für die Schaffung des Supercomputers „El Capitan“ entwickelt hat. Die Besonderheiten dieser Art von Erinnerung? Wir wissen sehr wenig, aber das Wenige, das wir wissen, ist das Folgende:
- Es verwendet die X3D-Schnittstelle für die externe Kommunikation. Dadurch muss AMD keine Konvertierungsteile von einem Schnittstellentyp zu einem anderen hinzufügen.
- AMD würde mit der Verwendung von Kühlsystemen wie Peltier-Zellen über diesem Speicher experimentieren, um höhere Taktraten zu erreichen.
- AMD erwägt die Einbeziehung von Beschleunigern oder Coprozessoren in die Logik dieses Speichertyps.
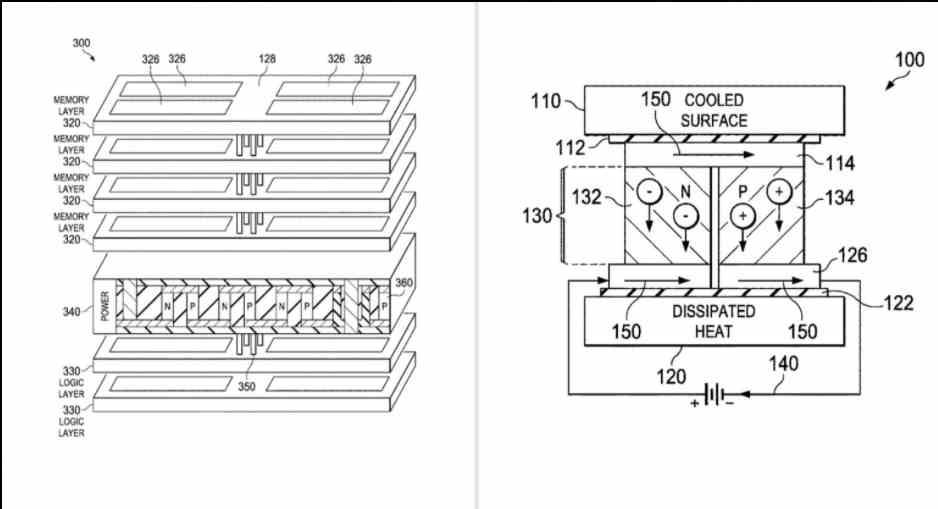
Wir wissen nicht, ob AMD dies in Zukunft auf dem Heimatmarkt verkaufen wird, aber wir werden höchstwahrscheinlich eine reduzierte Version dieser Technologie sehen. Werden wir MCMs der Marke AMD sehen, in denen CPU + Speicher + GPU + Beschleuniger Teil eines Ganzen sind? Wer weiß, aber es besteht kein Zweifel, dass AMD diese Technologie auch im Inland für die Herstellung neuer Chips nutzen wird.
Werden wir endlich sehen, dass High-End-CPUs und GPUs in einem MCM zusammenarbeiten? Sehr wahrscheinlich, da AMD genau das anstrebt.
