Während seiner Präsentation im Jahr 2019 über die Zukunft von Intel In der Xe-Architektur erwähnte Raja Koduri einen Speichertyp, den Intel „Rambo Cache“ getauft hat und der eines der Schlüsselelemente für Intel Xe ist. Aber was genau ist der Rambo-Cache und wozu dient er? Wir erklären es Ihnen.
Wie machen wir eine große Anzahl von GPU Chiplets kommunizieren effizient miteinander? Wir brauchen einen Speicher, um die Intercom-Arbeit zu erledigen, und hier kommt der Rambo-Cache ins Spiel. Wir erklären, wie er funktioniert und welche Funktion er hat.

Rambo-Cache als Unterschied zwischen Xe-HP und Xe-HPC

Wie auf der Intel-Folie zu sehen ist, ist der Rambo-Cache selbst ein Chip, der einen Speicher enthält, der ausschließlich im Intel Xe-HPC für die Kommunikation zwischen den verschiedenen Kacheln / Chiplets verwendet wird. . Während der Intel Xe-HP bis zu 4 verschiedene Kacheln unterstützt, verarbeitet der Intel Xe-HPC eine viel höhere Datenmenge, weshalb dieser zusätzliche Speicherchip als Kommunikationsbrücke für äußerst komplexe Konfigurationen hinsichtlich der Datenmenge erforderlich ist. GPU-Chiplets oder Kacheln, wie Intel sie nennt.

Der Rambo-Cache wird zwischen mehreren Intel Xe-HPC-Rechenkacheln platziert, um die Kommunikation zwischen ihnen zu erleichtern. Compute Tiles sind nichts anderes als Intel Xe-GPUs, sondern auf Hochleistungsrechnen spezialisiert. Daher werden die klassischen Einheiten mit festen Funktionen in GPUs nicht im Intel Xe-HPC enthalten sein, da sie nicht im Hochleistungsrechnen verwendet werden.
Der Rambo-Cache wird jedoch im Rest des Intel Xe beispiellos sein, insbesondere in solchen, die nicht auf mehreren Chips wie Intel Xe-LP und Intel Xe-HPG basieren. Im speziellen Fall des Intel Xe-HP scheint der Rambo-Cache bei 4 Chiplets nicht erforderlich zu sein, da Interposer genügend Bandbreite bietet, um die verschiedenen darauf montierten Chiplets zu kommunizieren.
Ziel ist es, den ExaFLOP zu erreichen

Wir wissen, dass die Grenze für die Anzahl der Chiplets auf einem Interposer 4 GPUs beträgt, von einer höheren Anzahl jedoch, wenn die auf einem EMIB-Interposer basierende Verbindung nicht mehr genügend Bandbreite für die Kommunikation bietet, was bedeutet, dass ein Element erforderlich ist, das die verbindet Zugriff auf den Speicher und hier würde der Rambo-Cache ins Spiel kommen, da Intel damit eine komplexere GPU herstellen könnte als die maximal 4 Chiplets, die mit der EMIB erstellt werden können.
Das Ziel? In der Lage zu sein, eine Hardware zu erstellen, die auf kombinierte Weise 1 PetaFLOP Gewalt oder mit anderen Worten 1000 TFLOPS erreichen kann. Eine Leistung, die viel höher ist als die GPUs, die wir in PCs haben, aber wir sprechen nicht von einer GPU für PCs, sondern von einer Hardware für Supercomputer mit dem Ziel, den ExaFLOP-Meilenstein zu erreichen, der 1000 PetaFLOPS und damit 1 Million beträgt TeraFLOPS.
Das große Anliegen der Hardwarearchitekten, dies zu erreichen, ist der Energieverbrauch, insbesondere bei der Datenübertragung, mehr Berechnungen, mehr Daten und mehr Daten bewegen mehr Energie. Aus diesem Grund ist es wichtig, die Daten so nah wie möglich an den Prozessoren zu halten. Hier kommt der Rambo-Cache ins Spiel.
Der Rambo-Cache als Cache der obersten Ebene
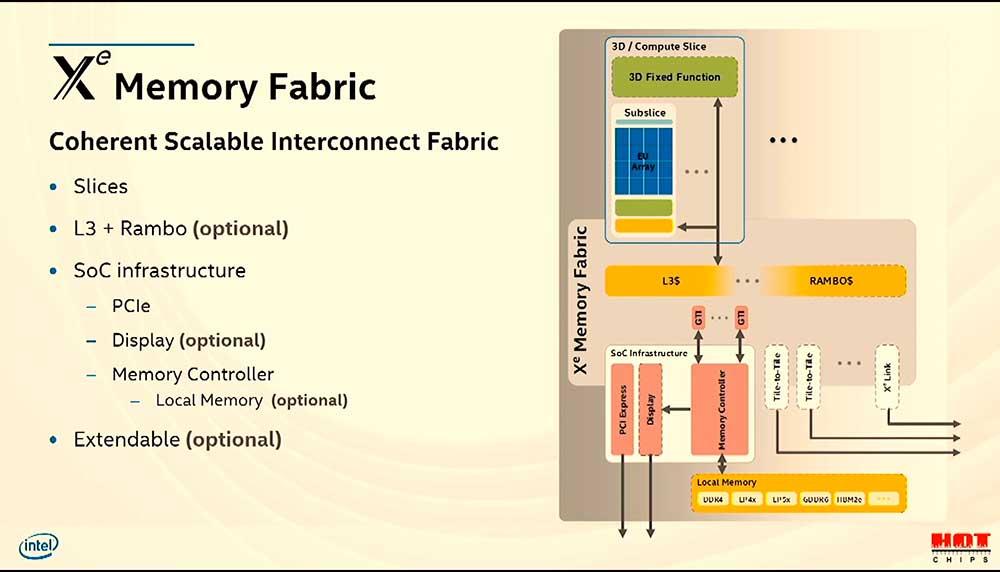
Wenn wir mehrere Kerne haben, ob es sich um einen handelt CPU oder eine GPU, und wir möchten, dass alle sowohl auf der Adressierungs- als auch auf der physischen Ebene gut auf denselben Speicher zugreifen. Dann wird ein Cache der letzten Ebene benötigt. Die „geografische“ Position innerhalb der GPU befindet sich direkt vor dem Speichercontroller, jedoch nach den privaten Caches jedes Kernels.
GPUs haben heute mindestens zwei Cache-Ebenen, die erste Ebene enthält keine Shader-Einheiten und ist normalerweise mit Textur-Einheiten verbunden. Die zweite Ebene wird stattdessen von allen Elementen einer GPU gemeinsam genutzt. In diesem Fall sind sie Ihr Verbindungspfad, um zu kommunizieren, auf die neuesten Daten zuzugreifen und all dies, um den VRAM-Controller nicht mit Anfragen an ihn zu überfüllen.
Es gibt jedoch eine zusätzliche Ebene: Wenn mehrere vollständige GPUs unter demselben Speicher miteinander verbunden sind, wird eine zusätzliche Cache-Ebene benötigt, die die Zugriffe auf alle Speicher gruppiert. Intels Rambo Cache ist Intels Lösung, um den Zugriff aller GPUs zu vereinheitlichen, aus denen Ponte Vecchio besteht.
