Die jüngste Einführung und der bevorstehende Start des AMD Die Prozessoren der Ryzen 5000-Serie, die auf der Zen 3-Architektur basieren, wurden zumindest für den Moment, wenn es um die Stromversorgung geht, von der Krone für AMD begleitet. Aber was macht die Zen 3-Architektur so schnell? Welche Elemente haben Sie in der dritten Generation der Zen-Architektur hinzugefügt, um eine bessere Leistung zu erzielen?
Vor dem Start ist zu beachten, dass der Ryzen 5000 sind nicht die direkten Nachfolger des AMD Ryzen 4000 , die monolithische SoCs sind, sondern die Ryzen 3000, da Die Ryzen 5000 sind ebenfalls MCM-Systeme basierend auf Chiplets.

In diesem System haben wir einerseits das IOD wo die Northbridge vom System liegt getauft als Scalable Data Fabric oder SDF von AMD und der Southbridge, die als IO Hub bezeichnet wird von der Gesellschaft der Ryzens und der Radeons. Das IOD hat sich in Bezug auf den Ryzen 3000 nicht geändert, außer in der Tatsache, dass schnellere Speicher unterstützt werden, da die Kerne über das IOD Zugriff auf das haben RAM vom System.

Wir können jedoch nicht sagen, dass sie den E / A-Chip des Ryzen 3000 unverändert genommen und transplantiert haben, sondern dass sie ihn durch ihre Erfahrung bei der Erstellung des Ryzen 4000 für Computer mit geringerem Verbrauch als ein PC-Desktop verbessert haben.
Also wo gab es die wirklich wichtige Änderungen sind im CCD oder Core Complex Die , der kleine Chip, auf dem die verschiedenen Kerne und ihre Cache-Hierarchie gespeichert sind. Hier wurden die wichtigsten Änderungen vorgenommen.
Der neue Core Complex Die der Zen 3-Architektur
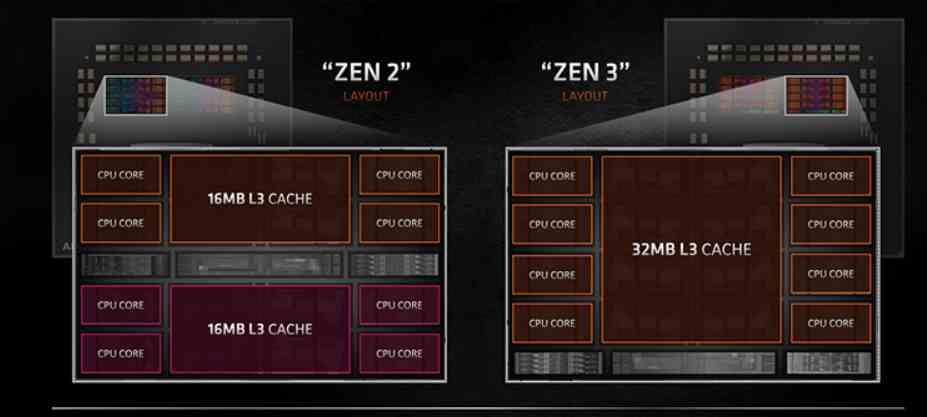
Das CCD im Zen 2 wurde erfunden von zwei CCXs mit jeweils 4 Kernen, mit ihren L3-Cache, der in jedem der CCXs gemeinsam genutzt wird . Dies führt zu einer Reihe von Latenzproblemen, wenn mehrere Kerne innerhalb derselben CCD, jedoch in einer anderen CCX, kommunizieren mussten. Wenn ein Kern mit einem anderen Kern kommunizieren musste, der sich in der anderen CCX befand, musste er den IOD durchlaufen, obwohl er sich auf der gleiche CCD.
Die Änderung, die AMD an der Zen 3-Architektur vorgenommen hat, ist sehr einfach. 8 Kerne teilen sich den L3-Cache anstelle von 4 Kerne gleichzeitig . Wir haben also keine 2 4-Core-CCXs pro CCD mehr bis 1 8-Kern-CCX pro CCD . Dies führt bei Anwendungen, die mit 8 oder weniger Kernen ausgeführt werden sollen, zu einem Leistungsvorteil.
Aber wo A. MD hat Verbesserungen vorgenommen auf der Ebene jedes Kerns befindet sich in der Einheiten laden / speichern sowie in der Frontend oder Steuergerät Verbesserungen, die entscheidend dazu beigetragen haben, eine durchschnittliche Leistung von 19% gegenüber dem Vorgänger Zen 2 zu erzielen.
Der Schlüssel ist die Steuereinheit
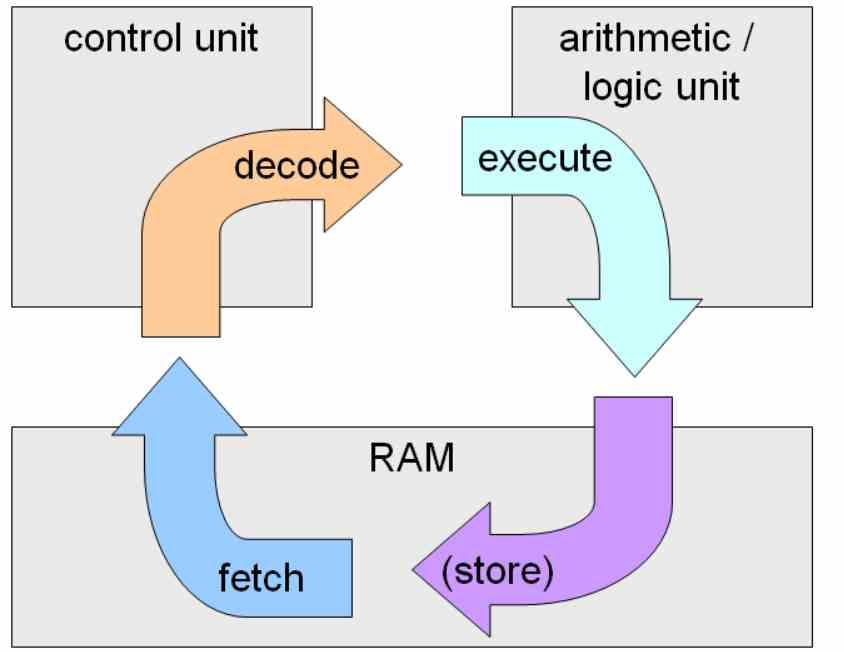
Wenn wir darüber reden Front-End beziehen wir uns auf die Steuereinheit von a CPU, während ALUs das Back-End sind. Innerhalb der Befehlszyklus , fetch-decode-execute, die Die ersten beiden Stufen sind die Arbeit der Steuereinheit , während der zweite Teil die Arbeit der ALUs oder Ausführungseinheiten ist.
Alle zeitgenössisch x86 Prozessoren nicht Führen Sie die Anweisungen unter der ISA aus , aber stattdessen entschlüsseln Sie die Anweisungen in einem internen ISA RISC Hier werden die Anweisungen tatsächlich in den Ausführungseinheiten ausgeführt. Diese interne ISA kann sich sogar zwischen Mitgliedern derselben Architektur ändern und ist der Schlüssel zur Erhöhung des IPC der Prozessoren.
Deshalb AMD hat die Steuereinheit neu gemacht und implementiert a neue, viel effizientere interne ISA Dadurch können Befehle in weniger Taktzyklen pro Befehl (CPI) ausgeführt werden, wodurch sich die durchschnittliche Anzahl von Befehlen pro Zyklus erhöht. .
