Obwohl das BIG Navi mit RDNA2-Architektur und seine Navi 2x-Chips als solches noch nicht auf den Markt gekommen sind, ist die Wahrheit, dass AMD (und in geringerem Maße NVIDIA) arbeiten bereits an der Umsetzung des Nachfolgers (der nicht HBM2E sein wird): HBM3 . Obwohl wir heute nicht zu viel darüber wissen, ist eine Reihe von Vergleichsdaten durchgesickert HBM2 Das ist sehr interessant und kann das Leistungsgleichgewicht zwischen den beiden Unternehmen beeinflussen. Wie hoch ist die Verbesserung?
Wie wir wissen, HBM2 und HBM2E sind zwei Arten von VRAM mit einer Reihe wichtiger Einschränkungen bei der Implementierung und Entwicklung für GPU Chips. Sie haben viele Vorteile in Bezug auf Leistung und Verbrauch, sie sind die Gegenwart aus der Notwendigkeit heraus, aber sie werden nicht die Zukunft als solche sein.
Dafür kommt HBM3, das innerhalb der wenigen, die wir darüber wissen, die Probleme seiner beiden vorherigen Versionen beenden wird. Bis heute kannten wir die Leistung nicht und vor allem, über welche Verbesserungen wir im Vergleich zu der ersetzten Version sprechen können.

HBM2 vs HBM3: Die ersten Vergleiche und Leistungssimulationen kommen an
Wie wir bereits sagten, sind die ersten Daten bereits vorhanden, mit der Ausnahme, dass sie, wie in diesen Fällen üblich, nicht über Bandbreite, FPS oder eine andere im Spielesektor übliche Metrik angeboten werden.
Als leistungsstarker TOP-Speicher ist die Geschäftswelt daran interessiert, mehr über Verbesserungen gegenüber HBM2 in einem zu erfahren Exaskala Serverumgebung, die letztendlich die Weltherrscher für ihre enorme Leistung sind. Daher spiegeln die Daten, die wir sehen werden, diese Situation wider und konzentrieren sich darauf, Schlussfolgerungen für Organisation, Bandbreite, Latenz, Kapazität und Leistung zu ziehen.
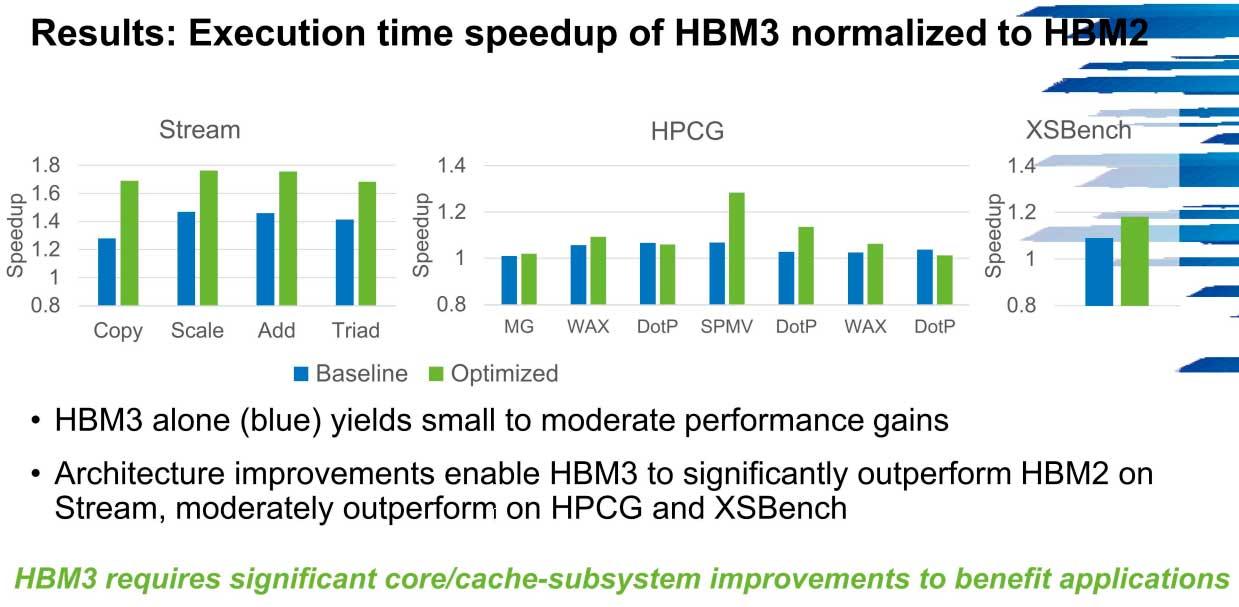
Die Frage ist klar und entscheidend: Inwieweit werden zukünftige PCs von HBM3 gegenüber HBM2 profitieren? Die Daten sind ziemlich klar.
Wie wir sehen können, wird die Optimierung des HBM3 eine mehr als wichtige Säule in Exascale-Systemen sein, und das heißt, es ist möglich, bis zu a zu erreichen 1.7-fache Geschwindigkeitssteigerung in Systemen über HBM2 mit wenig mehr als der Anzahl der Kerne und Subsystem-Caches.
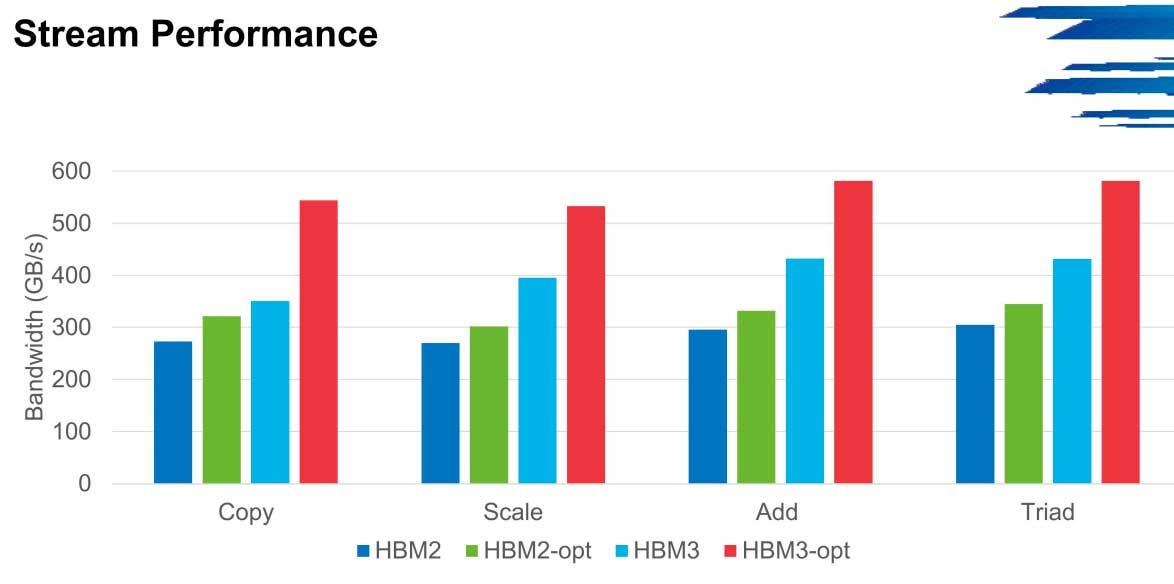
In HPCG kann die Bandbreitenleistung in diesen Umgebungen bis zu 600 GB / s von den 300 GB / s erreichen, ab denen die ersten Versionen mit niedriger Geschwindigkeit starten. Dieses Szenario wird beispielsweise in Stream wiederholt.
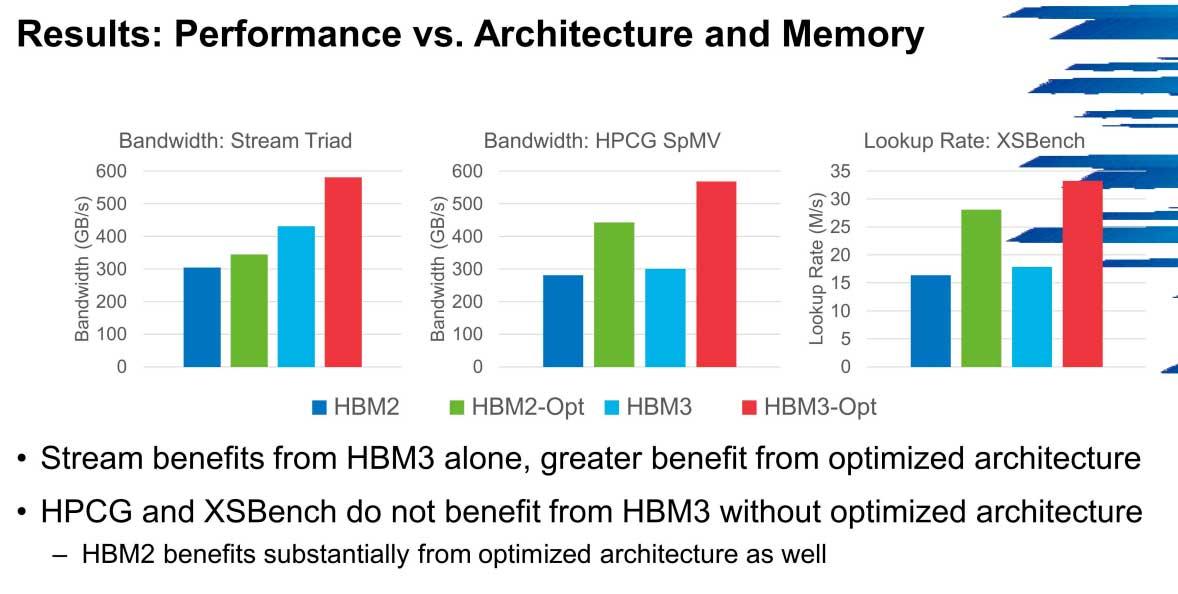
Das Hauptproblem, das HBM3 ziehen wird, sind genau die NoC-Netzwerke, bei denen die Bandbreite ein Engpass ist. Die Cluster werden sich in diesen Fällen leicht verbessern, solange es keinen solchen Engpass gibt, aber es ist kein Speichertyp, der für Systeme, die nicht genau optimiert sind, zu optimal zu sein scheint.
Die Anzahl der Threads, Typen und Größen des Caches sowie der Verzeichnisse sind entscheidend
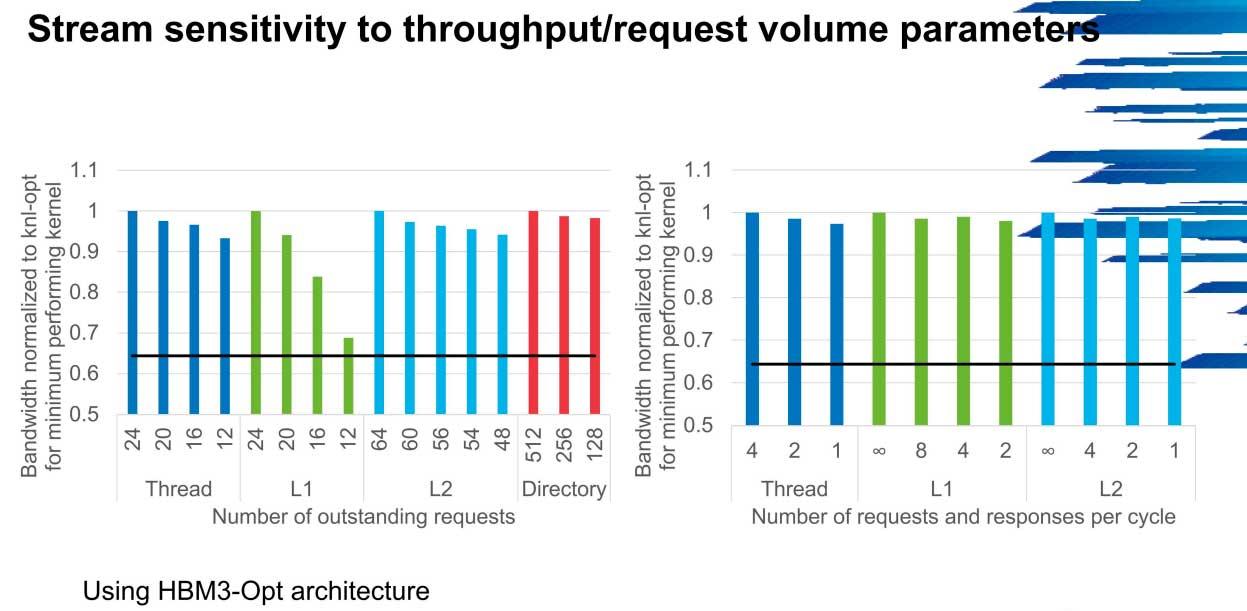
Die Frequenz und Anzahl der Kerne haben ebenfalls viel zu sagen, da die Erhöhung der Bandbreite von 1 auf 2 GHz in 300 GB / s auf 600 GB / s geht, wenn die Netzwerkfrequenz 5 GHz beträgt, was derzeit unerreichbar ist von fast allen Servern der Welt.
Das realistischste Szenario ist eine 4-GHz-Frequenz, bei der die Betriebsbandbreite leicht abnimmt, insbesondere bei Skalierung und Kopie, dies ist jedoch angesichts der aktuellen Leistung akzeptabel.
Die Anzahl der Threads, die Größe der L1- und L2-Caches sowie die Anzahl der Verzeichnisse sind auch wichtig, insbesondere im L1-Cache. Die Skalierbarkeit beträgt fast 80%, wenn von 12 auf 24 gewechselt wird. Dies spiegelt sich nicht in den anderen Parametern wider, zeigt jedoch die Bedeutung, die zukünftige Architekturen zu diesem Zeitpunkt haben werden, woran AMD seit einiger Zeit arbeitet Intel nahm sich vor etwas mehr als einem Jahr ernst.
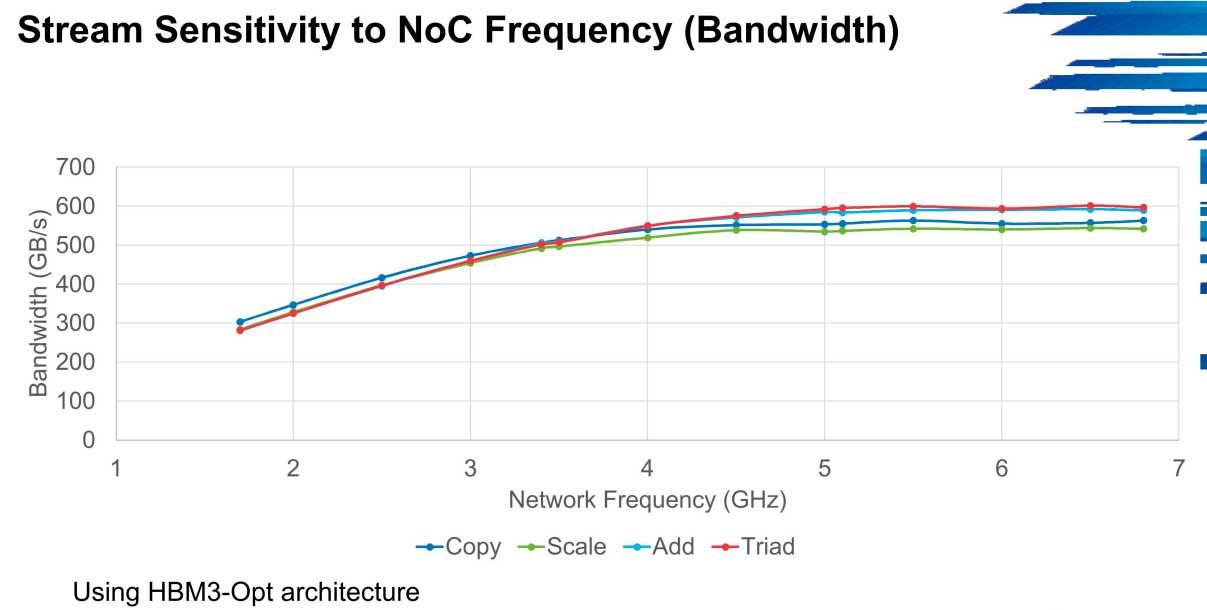
Zusamenfassend, HBM3 Da Server enorm von NoC-Ressourcen abhängig sind, ist eine maximale Optimierung erforderlich, um die Bandbreite voll auszunutzen (viel mehr, wenn sie ihre Endgeschwindigkeit im JEDEC erhöhen). Letztendlich handelt es sich um einen Arbeitsspeicher, der stark von Skalierbarkeit und Skalierbarkeit abhängt Ressourcen.
Beim Spielen wird es wieder ein sehr teurer Speicher ohne Vorteile sein, wo es bereits mehrfach war, der bei hohen Auflösungen und Hertz keinen Nutzen bringt. Es wird jedoch sicherlich von AMD in seiner High-End-GPU verwendet, wenn der Verbrauch in die Höhe schnellen und GDDR6 ist Keine Option aufgrund seiner Spannung, wo wir nur die Hoffnung haben, dass RDNA 2 wird Seien Sie effizienter und vermeiden Sie so die Implementierung und die Kosten für die Ausrüstung von Lisa Su.
Auf der anderen Seite hat NVIDIA keine Obertöne der Verwendung von Ihrer GPU Tesla und wird sich auf die konzentrieren GDDR6 Erinnerungen 18 Gbps um die Bandbreite zu erhöhen und gleichzeitig den Gesamtverbrauch ihrer Karten aufrechtzuerhalten, insbesondere um neue Knoten zu nutzen 7 nm und 8 nm von TSMC und Samsung.