AVX-512-Anweisungen sind eines der einzigartigen Elemente von Intelx86 CPU Architekturen. Aber wie lauten diese Anweisungen, da sie auf Intel-CPUs implementiert sind? Lesen Sie weiter, um zu verstehen, warum diese Anweisungen vorhanden sind, welche Varianten sie haben und warum sie nicht verwendet werden AMD in seinen CPUs.
AVX-Anweisungen wurden zuerst in Intel-CPUs implementiert und ersetzten die alten SSE-Anweisungen. Seitdem sind sie die Standard-SIMD-Anweisungen für x86-CPUs in ihren beiden Varianten 128-Bit und 256-Bit, die ebenfalls von AMD übernommen werden. Wenn wir dagegen über die AVX-512-Anweisungen sprechen, ist die Situation anders und sie werden nur in Intel-CPUs verwendet.

Was ist eine SIMD-Einheit?
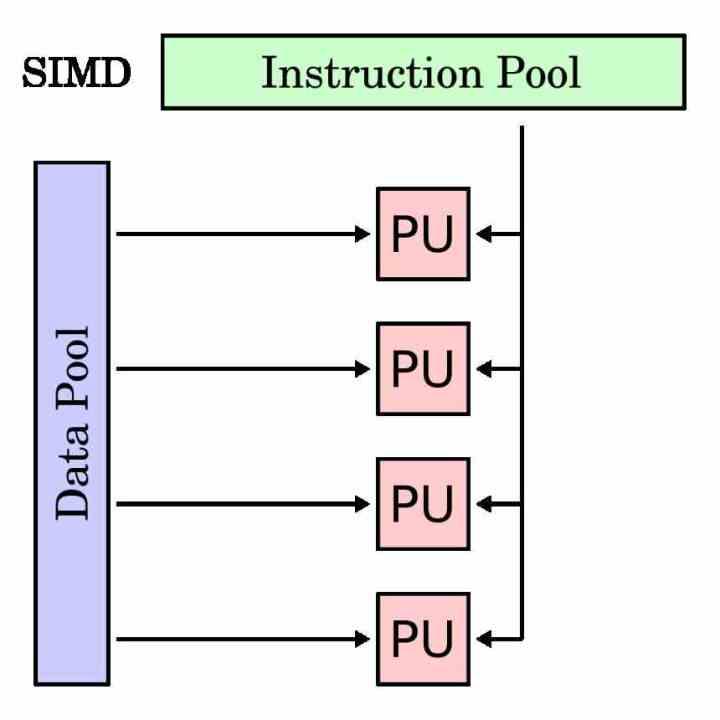
Eine SIMD-Einheit ist eine Art Ausführungseinheit, die denselben Befehl für mehrere Daten gleichzeitig ausführen soll. Daher ist sein Akkumulatorregister länger als ein herkömmlicher Befehl, da er die verschiedenen Daten gruppieren muss, die er mit demselben Befehl arbeiten muss.
SIMD-Einheiten werden traditionell verwendet, um sogenannte Multimedia-Prozesse zu beschleunigen, bei denen verschiedene Daten unter denselben Anweisungen bearbeitet werden müssen. Die SIMD-Einheiten ermöglichen es, die Ausführung des Programms in diesen Teilen zu parallelisieren und die Ausführungszeit zu beschleunigen.
Um die SIMD-Ausführungseinheiten von den herkömmlichen zu trennen, haben sie in jedem Prozessor eine eigene Teilmenge von Befehlen, die normalerweise ein Spiegel der skalaren Befehle oder mit einem einzelnen Operanden ist. Es gibt zwar Fälle, die mit einer Skalareinheit nicht möglich sind und nur für SIMD-Einheiten gelten.
Die Geschichte des AVX-512

Die AVX-Anweisungen, Advanced Vector eXtensions, befinden sich seit Jahren in Intel-Prozessoren, aber der Ursprung der AVX-512-Anweisungen unterscheidet sich von den anderen. Der Grund? Sein Ursprung ist das Intel Larrabee-Projekt, ein Versuch von Intel Ende der 2000er Jahre, ein GPU das wurde schließlich die Xeon Phi Beschleuniger. Eine Reihe von Prozessoren für Hochleistungsrechner, die Intel vor einigen Jahren herausgebracht hat.
Die Xeon Phi / Larrabee-Architektur enthielt eine spezielle Version der AVX-Anweisungen mit einer Größe in ihrem Akkumulatorregister von 512 Bit, was bedeutet, dass sie mit bis zu 16 32-Bit-Daten arbeiten können. Der Grund für diesen Betrag hat mit der Tatsache zu tun, dass das typische Verhältnis von Operationen pro Texel für eine GPU normalerweise 16: 1 beträgt. Vergessen wir nicht, dass die AVX-512-Anweisungen aus dem fehlgeschlagenen Larrabee-Projekt stammen und von dort nach gebracht wurden der Xeon Phi.
Bis heute gibt es das Xeon Phi nicht mehr. Der Grund dafür ist, dass dies auch über eine herkömmliche GPU für Computer möglich ist. Dies veranlasste Intel, diese Anweisungen auf seine Haupt-CPU-Linie zu übertragen.
Der Kauderwelsch, der AVX-512 Anweisungen ist
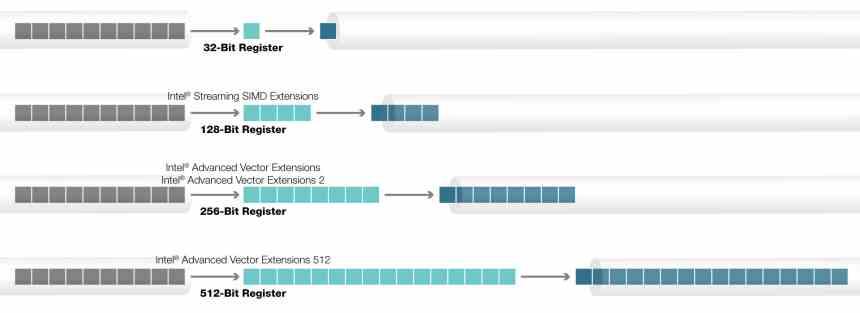
Die AVX-512-Anweisungen sind kein homogener Block, der zu 100% implementiert ist, sondern haben verschiedene Erweiterungen, die je nach Prozessortyp hinzugefügt wurden oder nicht. Alle CPUs heißen AVX512F, es gibt jedoch zusätzliche Anweisungen, die nicht Teil des ursprünglichen Befehlssatzes sind und die Intel im Laufe der Zeit hinzugefügt hat.
Die AVX512-Erweiterungen lauten wie folgt:
- AVX-512-CD: Die Konflikterkennung ermöglicht die Vektorisierung von Schleifen und damit die Vektorisierung. Sie wurden zuerst in Skylake-X oder Skylake-SP hinzugefügt.
- AVX-512-ER: Reziproke und exponentielle Anweisungen, die für die Implementierung transzendentaler Operationen ausgelegt sind. Sie wurden in einer Xeon Phi-Reihe namens Knights Landing hinzugefügt.
- AVX-512-PF: Eine weitere Aufnahme in Knights Landing, diesmal, um die Vorsorge- oder Prefetech-Fähigkeiten der Anweisungen zu verbessern.
- AVX-512-BW: Anweisungen auf Byte-Ebene (8 Bit) und Wortebene (16 Bit). Mit dieser Erweiterung können Sie mit 8-Bit- und 16-Bit-Daten arbeiten.
- AVX-512-DQ: Fügen Sie neue Anweisungen mit 32-Bit- und 64-Bit-Daten hinzu.
- AVX-512-VL : Ermöglicht es AVX-Anweisungen, mit XMM- (128-Bit) und YMM- (256-Bit) Akkumulatorregistern zu arbeiten
- AVX-512-IFMA: Fused Multiply Add, umgangssprachlich ein A * (B + C) -Befehl mit 52-Bit-Ganzzahlgenauigkeit.
- AVX-512-VBMI: Anweisungen zur Vektormanipulation auf Byte-Ebene sind eine Erweiterung des AVX-512-BW.
- AVX-512-VNNI: Die Anweisungen für das Vektor-Neuronale Netzwerk sind eine Reihe von Anweisungen zur Beschleunigung von Deep-Learning-Algorithmen, die in Anwendungen im Zusammenhang mit künstlicher Intelligenz verwendet werden.
Warum hat AMD es noch nicht auf ihren CPUs implementiert?

Der Grund dafür ist sehr einfach: AMD setzt sich für die kombinierte Verwendung von CPU und GPU ein, wenn bestimmte Arten von Anwendungen beschleunigt werden. Vergessen wir nicht den Ursprung des AVX-512 in einer ausgefallenen GPU von Intel und AMD. Dank ihrer Radeon-GPUs benötigen sie keine AVX-512-Anweisungen.
Aus diesem Grund sind die AVX-512-Anweisungen exklusiv für Intel-Prozessoren, nicht aus Gründen der vollständigen Exklusivität, sondern weil AMD kein Interesse daran hat, diese Art von Anweisungen in seinen CPUs zu verwenden, da beabsichtigt wird, seine GPUs, insbesondere den neu eingeführten AMD Instinct, zu verkaufen Hochleistungsrechnen mit CDNA-Architektur.
Haben die AVX-512-Anweisungen eine Zukunft?

Nun, wir wissen nicht, es hängt vom Erfolg des Intel Xe ab, insbesondere des Xe-HPC, der Intel eine GPU-Architektur auf AMD- und AMD-Ebene verleiht NVIDIA. Dies bedeutet einen Konflikt zwischen den Anweisungen von Intel Xe und AVX-512, um dieselben Probleme zu lösen.
Das Problem beim AVX-512 besteht darin, dass die Aktivierung des Teils der CPU, der sie verwendet, die Taktrate der CPU beeinflusst und in einem Programm, das diese Anweisungen für bestimmte Momente verwendet, um etwa 25% reduziert wird. Darüber hinaus sind seine Anweisungen für Hochleistungs-Computing- und KI-Anwendungen gedacht, die für eine Heim-CPU nicht wichtig sind, und das Erscheinungsbild spezialisierter Einheiten macht sie zu einer Verschwendung von Transistoren und Platz.
In der Realität ersetzen Beschleuniger oder domänenspezifische Prozessoren SIMD-Einheiten in CPUs langsam, da sie dasselbe tun können, während sie weniger Platz beanspruchen und im Vergleich dazu einen geringen Stromverbrauch haben.
