
เทคโนโลยีที่เรียกว่า X3D เป็นหนึ่งในเทคโนโลยีที่สำคัญที่สุด เอเอ็มดี สำหรับอนาคตหากไม่ใช่สิ่งที่สำคัญที่สุดเนื่องจากเป็นสิ่งที่องค์ประกอบต่าง ๆ ของโปรเซสเซอร์จะสื่อสารกัน ความสำคัญอยู่ที่ความจริงที่ว่าเทคโนโลยี Infinity Fabric กำลังจะเข้ามาแทนที่และแม้ว่ามันจะยังคงอยู่บนขอบฟ้าที่ดูเหมือนห่างไกล แต่เราก็ยิ่งใกล้เข้ามาทุกวัน
เมื่อเผชิญกับการพัฒนา Exascale Heterogenous Processor ซึ่งเป็นกุญแจสำคัญสำหรับ AMD ในการชนะสัญญาการก่อสร้าง El Capitan พวกเขาจึงต้องสร้างอินเทอร์เฟซรูปแบบใหม่เพื่อให้การสื่อสารระหว่าง ซีพียู และ GPU สามารถทำได้ในสภาพแวดล้อมที่ทั้งสองใช้หน่วยความจำเดียวกันได้ดีสิ่งนี้ได้บังคับให้ AMD พัฒนาอินเทอร์เฟซการสื่อสารรูปแบบใหม่ซึ่งมาเพื่อแก้ปัญหาที่จนถึงตอนนี้ AMD ยังไม่สามารถแก้ไขได้
ทำไมเราถึงยังไม่เห็น GPU ที่ใช้ชิปเล็ต?

สาเหตุที่เราไม่เห็น GPU เฉพาะใน MCM ที่แชร์การเข้าถึงหน่วยความจำกับซีพียูเป็นเพราะแบนด์วิดท์ที่ให้มาโดย IOD ไม่มากพอที่จะจ่ายไฟให้กับ GPU ในกรณีของ MCM ที่มีระบบหน่วยความจำแบบรวมเรากำลังพูดถึงการใช้ไฟล์ อินฟินิตี้แคช ของ GPU เป็น L4 ของระบบ
ทำไม Infinity Fabric จึงไม่เพียงพอ? เนื่องจากมันทำให้เรามีอินเทอร์เฟซ 32 หรือ 64 ไบต์ / รอบขึ้นอยู่กับเวอร์ชัน
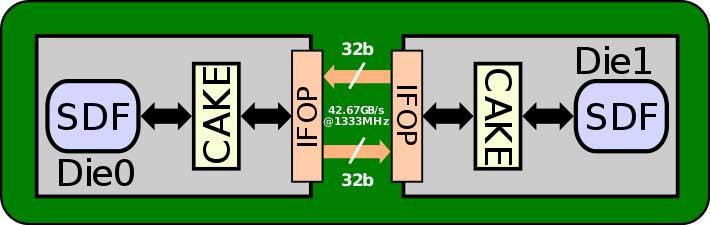
ตอนนี้จินตนาการว่าเราต้องการเชื่อมต่อ Navi 21 (RX 6800, RX 6800 XT และ RX 6900 XT) เราต้องจำไว้ว่าระหว่างแคช L2 ภายใน GPU และ Infinity Cache เรามี 16 พาร์ติชันของ L2 Cache พร้อมแบนด์วิดท์ 64 ไบต์ / รอบแต่ละอันมีขนาดประมาณ 1024 ไบต์ / รอบดังนั้นจึงเป็นอินเทอร์เฟซ 8192 บิตซึ่งบังคับให้วิศวกรของ AMD พัฒนาอินเทอร์เฟซการสื่อสารที่ซับซ้อนกว่า Infinity Fabric มากเพื่อให้สามารถสื่อสาร GPU โดยใช้ พูลหน่วยความจำเดียวกัน
ปัญหาเกี่ยวกับ Infinity Fabric เมื่อต้องสื่อสารกับชิปหลายตัวกับภายนอกคือการเชื่อมต่อ 2D แนวนอนมันมีพินจำนวน จำกัด ที่เราสามารถวางได้โดยไม่ต้องเพิ่มขอบเขตของชิปมากนัก อีกทางเลือกหนึ่งหากเราต้องการเพิ่มแบนด์วิดท์คือการเพิ่มความเร็วสัญญาณนาฬิกาของแต่ละพิน แต่จะเป็นการเพิ่มการใช้พลังงานอย่างมากซึ่งจะทำให้งบประมาณหมดไป
X3D แทนที่เป็น Infinity Fabric
 ปัญหาของ Infinity Fabric คือไม่สามารถสื่อสารกับชิปในแนวตั้งได้ ดังนั้นจึงไม่ได้ใช้ประโยชน์จากความสัมพันธ์ที่ยอดเยี่ยมระหว่างแบนด์วิดท์และการใช้พลังงานของอินเทอร์เฟซแนวตั้งที่ใช้เส้นทางผ่านซิลิกอนและมีปัญหานี้อยู่ด้านบนของตารางซึ่ง AMD ได้พัฒนาเสร็จสิ้นในอนาคตเพื่อแทนที่อย่างสมบูรณ์ของ ผ้าอินฟินิตี้
ปัญหาของ Infinity Fabric คือไม่สามารถสื่อสารกับชิปในแนวตั้งได้ ดังนั้นจึงไม่ได้ใช้ประโยชน์จากความสัมพันธ์ที่ยอดเยี่ยมระหว่างแบนด์วิดท์และการใช้พลังงานของอินเทอร์เฟซแนวตั้งที่ใช้เส้นทางผ่านซิลิกอนและมีปัญหานี้อยู่ด้านบนของตารางซึ่ง AMD ได้พัฒนาเสร็จสิ้นในอนาคตเพื่อแทนที่อย่างสมบูรณ์ของ ผ้าอินฟินิตี้
เมื่อ AMD ประกาศ X3D หลายคนคิดว่ามันเป็นบรรจุภัณฑ์ประเภทหนึ่งจริงๆแล้วมันไม่ได้เป็นแบบนั้น แต่มันจะเป็นการเชื่อมต่อแบบใหม่เช่น Infinity Fabric เฉพาะที่มันจะทำงานในแนวตั้งบนตัวประสานในการกำหนดค่าที่คล้ายกับที่ใช้ในชิปที่มาพร้อมกับหน่วยความจำ HBM
แนวคิดคือการมีอินเทอร์เฟซการสื่อสารที่มีการใช้พลังงานใกล้เคียงกับ 0.2 pJ / bit ซึ่งช่วยให้แบนด์วิดท์สูงขึ้นสิบเท่าภายใต้การใช้พลังงานเช่นเดียวกับ Infinity Fabric
จริงๆแล้ว AMD นั้นล้าหลังเมื่อเทียบกับ Intel
 เทคโนโลยีที่ AMD กำลังพัฒนานั้นเป็นการตอบสนอง อินเทล Foveros ซึ่ง Intel ได้จัดการพัฒนาประเภทของการเชื่อมต่อโครงข่ายประเภทเดียวกันภายใต้การบริโภค 0.15 pJ / bit ดังนั้นจึงอาจกล่าวได้ว่า Lisa Su ล้าหลังและเช่นเดียวกับ Intel พวกเขาตระหนักดีว่าชิปแห่งอนาคตขึ้นอยู่กับการใช้การเชื่อมต่อระหว่างกันประเภทใหม่ซึ่งทำให้การออกแบบโปรเซสเซอร์ที่แตกต่างกันส่งผลให้เกิดการเปลี่ยนกระบวนทัศน์
เทคโนโลยีที่ AMD กำลังพัฒนานั้นเป็นการตอบสนอง อินเทล Foveros ซึ่ง Intel ได้จัดการพัฒนาประเภทของการเชื่อมต่อโครงข่ายประเภทเดียวกันภายใต้การบริโภค 0.15 pJ / bit ดังนั้นจึงอาจกล่าวได้ว่า Lisa Su ล้าหลังและเช่นเดียวกับ Intel พวกเขาตระหนักดีว่าชิปแห่งอนาคตขึ้นอยู่กับการใช้การเชื่อมต่อระหว่างกันประเภทใหม่ซึ่งทำให้การออกแบบโปรเซสเซอร์ที่แตกต่างกันส่งผลให้เกิดการเปลี่ยนกระบวนทัศน์
แต่ เหตุผลเบื้องหลังเทคโนโลยีเหล่านี้คือการพัฒนาซูเปอร์คอมพิวเตอร์ที่มีความสามารถในการเข้าถึงอัตรา 1 ExaFLOPS ซึ่งเป็นเรื่องง่ายจากมุมมองของการดำเนินการตามคำสั่ง แต่แทบจะเป็นไปไม่ได้เลยถ้าเราพูดถึงต้นทุนพลังงานของหน่วยความจำ สำหรับสิ่งนี้เราต้องแนะนำแนวคิดซึ่งก็คือ ความเข้มทางคณิตศาสตร์ .
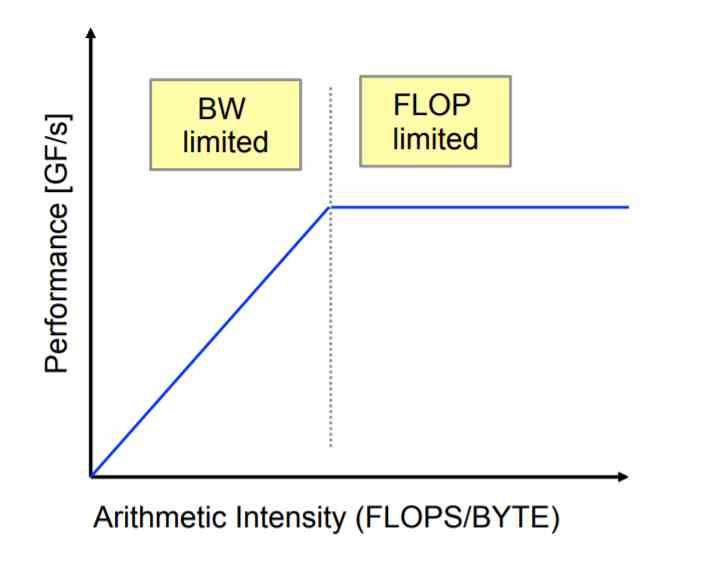
แนวคิดคือสถาปัตยกรรมสามารถถูก จำกัด ได้ด้วยจำนวนการดำเนินการที่ดำเนินการ ตามแบนด์วิดท์ที่จำเป็นสำหรับการดำเนินการเหล่านั้น . แน่นอนว่าถ้าเราเพิ่มความสามารถในการประมวลผลอย่างมากเราก็ต้องใช้หน่วยความจำด้วย แต่หน่วยความจำที่เรามีเพียงพอที่จะปรับขนาดในการประมวลผลหรือไม่?
วิวัฒนาการของ แรม ซ้ำซากจำเจทุกครั้งที่มีโหนดการผลิตใหม่ปรากฏขึ้นซึ่งช่วยลดการใช้พลังงานในการถ่ายโอนข้อมูล แต่ความเร็วในการพัฒนา RAM ไม่เร็วพอที่จะเผชิญกับความท้าทายที่ผู้ผลิตโปรเซสเซอร์เช่น Intel และ AMD ต้องเผชิญ เพื่อแก้ไขปัญหาด้วยตนเอง
ความต้องการแรมชนิดใหม่
 เรารอ HBM Next Gen หรือ HBM3 มานานแล้ว สเปคของมันถูกแช่แข็งมาเป็นเวลานานและเหตุผลก็คือ ผู้ผลิตโปรเซสเซอร์รายใหญ่แต่ละราย (AMD, Intel และ NVIDIA) กำลังพัฒนาหน่วยความจำ“ HBM3” ของตัวเอง . ในกรณีของ AMD พวกเขาจะใช้การพัฒนาหน่วยความจำประเภทนี้จากการสร้าง 3D DRAM ที่มีอินเทอร์เฟซการสื่อสารตามอินเทอร์เฟซ X3D ซึ่งจะใช้เป็นครั้งแรกในซูเปอร์คอมพิวเตอร์ El Capitan
เรารอ HBM Next Gen หรือ HBM3 มานานแล้ว สเปคของมันถูกแช่แข็งมาเป็นเวลานานและเหตุผลก็คือ ผู้ผลิตโปรเซสเซอร์รายใหญ่แต่ละราย (AMD, Intel และ NVIDIA) กำลังพัฒนาหน่วยความจำ“ HBM3” ของตัวเอง . ในกรณีของ AMD พวกเขาจะใช้การพัฒนาหน่วยความจำประเภทนี้จากการสร้าง 3D DRAM ที่มีอินเทอร์เฟซการสื่อสารตามอินเทอร์เฟซ X3D ซึ่งจะใช้เป็นครั้งแรกในซูเปอร์คอมพิวเตอร์ El Capitan
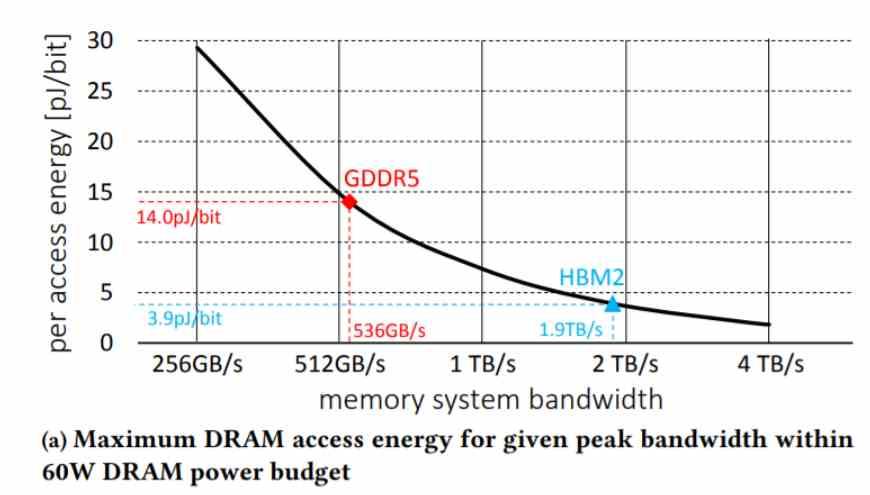
ปัญหาคือทุกระบบมีแบนด์วิดท์ที่ จำกัด โดยการใช้พลังงานที่กำหนดให้กับระบบและไม่ว่าเราจะเพิ่มแบนด์วิดท์มากแค่ไหนเราก็ไปถึงจุดที่เราไม่สามารถเพิ่มได้มากขึ้นเนื่องจากการใช้พลังงานของหน่วยความจำ สูงเกินไปดังนั้นความทรงจำที่มีจำนวน pJ / bit ที่ต่ำกว่าและต่ำกว่าจึงได้รับการพัฒนาอย่างต่อเนื่อง
แต่อะไรล่ะที่กินไฟมากที่สุด? อินเทอร์เฟซการสื่อสารที่ใช้ในการเคลื่อนย้ายข้อมูลแนวคิดคือการเข้าถึงตัวเลข pJ / bit ที่ต่ำพอที่จะสื่อสารกับชิปเล็ต GPU ได้โดยไม่มีปัญหา แต่ยังสามารถสร้างความทรงจำด้วยแบนด์วิดท์สูงโดยไม่ต้องเพิ่มปริมาณการใช้มากขึ้น
หน่วยความจำ X3D DRAM?

หากคุณเคยเห็นแผนงานบรรจุภัณฑ์ของ AMD คุณอาจคิดตั้งแต่แรกว่าหน่วยความจำที่ซ้อนกันในแนวคิด X3D เป็นหน่วยความจำ HBM ประเภทหนึ่ง แต่จริงๆแล้วไม่ใช่
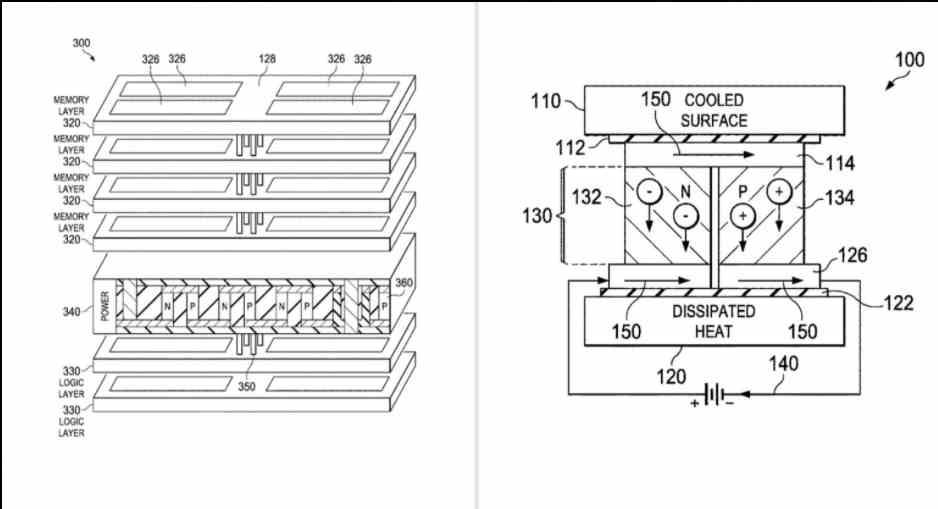
เป็นหน่วยความจำประเภทหนึ่งที่สร้างขึ้นเพื่อทดแทน HBM2e ปัจจุบัน ที่ AMD ได้พัฒนาเป็นการภายในในการพัฒนา EHP สำหรับการสร้างซูเปอร์คอมพิวเตอร์“ El Capitan” ลักษณะเฉพาะของหน่วยความจำประเภทนี้? เรารู้น้อยมาก แต่เรารู้น้อยมากมีดังต่อไปนี้:
- ใช้อินเทอร์เฟซ X3D เพื่อสื่อสารกับภายนอกซึ่งช่วยประหยัด AMD ที่ต้องเพิ่มส่วนการแปลงจากอินเทอร์เฟซประเภทหนึ่งไปยังอีกประเภทหนึ่ง
- AMD จะทำการทดลองโดยใช้ระบบระบายความร้อนเช่นเซลล์ peltier ที่อยู่ด้านบนของหน่วยความจำนี้เพื่อให้ได้ความเร็วสัญญาณนาฬิกาที่สูงขึ้น
- AMD กำลังพิจารณาการรวมตัวเร่งความเร็วหรือตัวประมวลผลร่วมในตรรกะของหน่วยความจำประเภทนี้
เราไม่ทราบว่า AMD จะขายสิ่งนี้ในตลาดบ้านเกิดในอนาคตหรือไม่ แต่เรามักจะได้เห็นเทคโนโลยีรุ่นนี้ลดลง เราจะได้เห็น MCM ของแบรนด์ AMD ที่ CPU + Memory + GPU + Accelerator เป็นส่วนหนึ่งของทั้งหมดหรือไม่? ใครจะรู้ แต่ไม่ต้องสงสัยเลยว่า AMD จะใช้เทคโนโลยีนี้ในระดับภายในประเทศเพื่อการสร้างชิปใหม่
ในที่สุดเราจะได้เห็น CPU และ GPU ระดับไฮเอนด์ที่ทำงานร่วมกันใน MCM หรือไม่? เป็นไปได้มากเนื่องจากนั่นคือสิ่งที่ AMD ตั้งเป้าไว้
