
หากมีสิ่งที่ดึงดูดความสนใจของกราฟิกการ์ดนั่นคือความเร็วมหาศาลที่ความทรงจำของพวกเขาพกพาเข้าใจว่าความเร็วของข้อมูลที่ส่งต่อวินาทีนั่นคือสิ่งที่เรียกว่าแบนด์วิดท์ แต่อะไรคือสาเหตุที่ GPU ต้องการแบนด์วิดท์ของ VRAM ถึงมีขนาดใหญ่? เราอธิบายให้คุณทราบ
ต่อไปเราจะอธิบายทฤษฎีที่อยู่เบื้องหลังความจริงที่ว่ากราฟิกการ์ดใช้ความทรงจำพิเศษที่มีความเร็วในการถ่ายโอนสูงแนวคิดบางอย่างหลายคนรู้ล่วงหน้าแล้วในขณะที่คนอื่น ๆ จะไม่ทราบเนื่องจากมักไม่ได้กล่าวถึงในตลาดกราฟิกการ์ด
แบนด์วิดท์ระหว่าง GPU และ VRAM

พื้นที่ GPU ใช้แบนด์วิดท์ที่หลากหลายเพื่อแสดงฉากในรูปแบบ 3 มิติซึ่งเราจะแสดงรายการด้านล่าง:
- บัฟเฟอร์สี (Bc): เป็นส่วนหนึ่งของสิ่งที่เรียกว่า Backbuffer หรือบัฟเฟอร์ด้านหลังซึ่ง GPU จะดึงฉาก ในแต่ละพิกเซลจะมีส่วนประกอบ RGBA หากการแสดงผลล่าช้าจะมีการสร้างบัฟเฟอร์หลายตัวเพื่อสร้าง G-Buffer ใน API ปัจจุบัน GPU รองรับบัฟเฟอร์ประเภทนี้ได้สูงสุด 8 รายการในเวลาเดียวกัน
- บัฟเฟอร์ความลึก (Bz): ยังเป็นที่รู้จัก Z-Buffer มัน เป็นบัฟเฟอร์ที่จัดเก็บตำแหน่งของพิกเซลของวัตถุแต่ละชิ้นที่เกี่ยวข้องกับกล้อง รวมกับ Stencil Buffer ซึ่งแตกต่างจาก Color Buffer ซึ่งจะไม่ถูกสร้างขึ้นในระหว่างขั้นตอนหลังการเท็กซ์เจอร์ แต่ในขั้นตอนก่อนหน้านี้คือการแรสเตอร์
- พื้นผิว (Bt): GPU ใช้แผนที่พื้นผิวขนาดใหญ่จนไม่พอดีกับหน่วยความจำและต้องนำเข้าจาก VRAM ซึ่งเป็นการทำงานแบบอ่านอย่างเดียว ในทางกลับกันเอฟเฟกต์หลังการประมวลผลจะอ่านบัฟเฟอร์รูปภาพราวกับว่าเป็นพื้นผิว
สรุปได้ในแผนภาพต่อไปนี้:
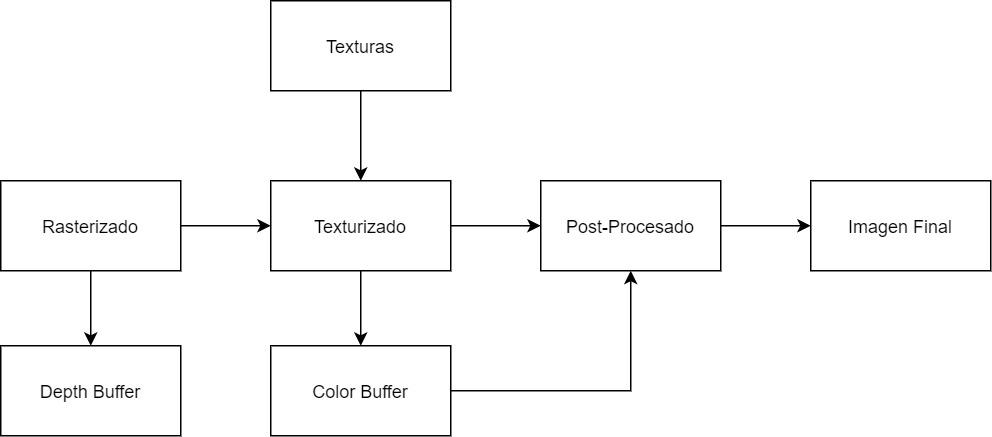
เนื่องจากชิปหน่วยความจำ VRAM เป็น เพล็กซ์เต็มรูปแบบ และส่งทั้งอ่านและเขียนในเวลาเดียวกันแบนด์วิดท์จะเท่ากันทั้งสองทิศทาง ส่วนของไปป์ไลน์กราฟิกที่มีการประมวลผลมากขึ้นอย่างแม่นยำในระหว่างการเท็กซ์เจอร์นั่นคือหนึ่งในคำอธิบายแรก ๆ ว่าทำไม GPU จึงต้องการความกว้างในการเดินสูง
สำหรับข้อมูลที่ใช้ในระหว่างขั้นตอนก่อนการแรสเตอร์การคำนวณรูปทรงเรขาคณิตของฉากนั้นมีค่าต่ำพอที่จะไม่ส่งผลให้มีการใช้หน่วยความจำจำนวนมากและมีผลต่อประเภทของหน่วยความจำที่ใช้เป็น VRAM
ปัญหา Overdraw

อัลกอริทึมที่ใช้ในการเรนเดอร์ฉากคือการแรสเตอร์หรือที่เรียกว่าอัลกอริทึม z-buffer หรืออัลกอริทึมของจิตรกรซึ่งในรูปแบบพื้นฐานมีโครงสร้างดังต่อไปนี้สำหรับแต่ละแบบดั้งเดิมในฉากสำหรับแต่ละพิกเซลที่ครอบคลุมโดยดั้งเดิมให้ทำเครื่องหมายพิกเซล ใกล้กับกล้องมากที่สุดและจัดเก็บไว้ใน z-buffer
สิ่งนี้ทำให้หากวัตถุหลายชิ้นอยู่ในตำแหน่งเดียวกันของแกนพิกัด X และ Y เทียบกับกล้อง แต่อยู่ในตำแหน่งที่ต่างกันตามแกน Z พิกเซลของแต่ละวัตถุจะถูกวาดในภาพสุดท้าย บัฟเฟอร์และเสร็จสิ้นเพื่อประมวลผลหลายครั้ง เอฟเฟกต์นี้เรียกว่า overdraw หรือ overdrawn เนื่องจาก GPU วาดสีและ repaints พิกเซลในตำแหน่งเดียวกัน
ตอนนี้คุณบางคนคิดถูกต้องดังนี้: หากสร้างบัฟเฟอร์ความลึกก่อนการสร้างพื้นผิวพิกเซลจะไม่ถูกทิ้งในขั้นตอนนั้นได้อย่างไร? จริงๆแล้วมีเทคนิคสำหรับสิ่งนั้น แต่ในขั้นตอนนั้นเราไม่ทราบสีของแต่ละพิกเซลและถ้าวัตถุนั้นเป็นแบบกึ่งโปร่งใสหรือไม่ดังนั้น GPU จึงไม่สามารถละทิ้งพิกเซลทั้งหมดในฉากที่มีวัตถุเพียงชิ้นเดียวได้ โปร่งใสตั้งแต่นั้นมาการแสดงจะไม่ถูกต้อง
การเรียงลำดับกลางเทียบกับการเรียงลำดับสุดท้าย
กระบวนการตรวจสอบพิกเซลทีละพิกเซลเพื่อดูว่ามองเห็นได้หรือไม่ต้องใช้วงจรพิเศษใน GPU และกระบวนการแสดงผลจะได้รับผลกระทบ แนวคิดเกี่ยวกับ GPU คือพลังขั้นต้นโดยไม่ต้องคำนึงถึงองค์ประกอบอื่น ๆ หากมีการเพิ่มประสิทธิภาพใด ๆ ที่ต้องทำสิ่งนี้จะเหลืออยู่ในส่วนฮาร์ดแวร์นั่นคือเหตุผลที่การตรวจสอบพิกเซลต้องไปที่บัฟเฟอร์รูปภาพหรือมัน ไม่ได้ทำในตอนท้ายของกระบวนการซึ่งเรียกว่า Last Sort
ในขณะที่ถ้าวัตถุถูกจัดเรียงในช่วงแรสเตอร์โดยใช้ Depth Buffer เป็นข้อมูลอ้างอิงเราจึงเรียกมันว่า Middle Sort เพราะมันเกิดขึ้นตรงกลางของไปป์ไลน์กราฟิก
เทคนิคที่สองหลีกเลี่ยงการวางทับ แต่อย่างที่เราเคยเห็นมาก่อนจะมีปัญหาเมื่อฉากมีความโปร่งใส แล้ว GPU ปัจจุบันใช้ทำอะไร? ทั้งสองอย่างเนื่องจากนักพัฒนาสามารถเลือกประเภทที่จะเลือกได้ ความแตกต่างก็คือใน Middle Sort จะไม่มีการมากเกินไป
แบนด์วิดท์และ VRAM: overdraw
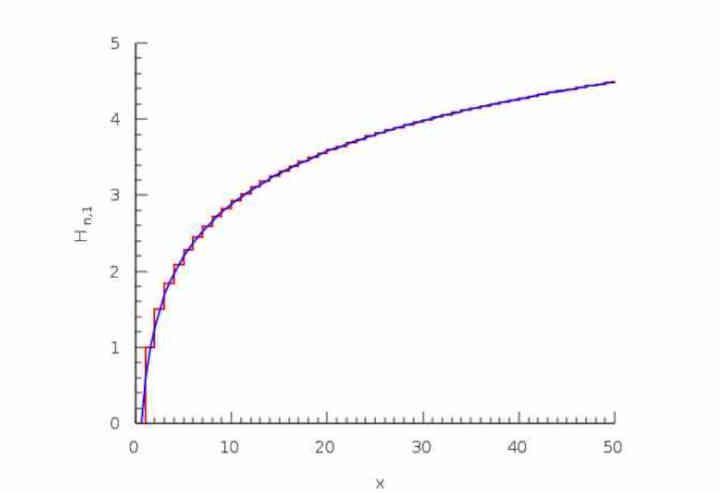
ตรรกะที่อยู่เบื้องหลังการวาดทับคือพิกเซลแรกในตำแหน่ง (x, y) จะถูกวาดในบัฟเฟอร์ภาพใช่หรือใช่พิกเซลที่สองภายใต้ตำแหน่งเดียวกันจะมีโอกาส 50% ที่จะมีค่า Z มากกว่าหรือ 50 % ของโอกาสที่จะมีขนาดเล็กกว่าดังนั้นจึงถูกเขียนในบัฟเฟอร์สุดท้ายส่วนที่สามมีความเป็นไปได้ 1/3 ของความเป็นไปได้ที่มีอยู่หนึ่งในสี่ของ 1/4
สิ่งนี้เรียกว่าอนุกรมฮาร์มอนิก:
เอช (น) = 1 + 1/2 + 1/3 + 1/4 … 1 / น
เหตุใดสิ่งนี้จึงสำคัญ เนื่องจากความจริงที่ว่าแม้ว่าพิกเซลที่ถูกลบออกโดยการ overdraw จะมีขนาดใหญ่มาก แต่ก็ถึงจุดที่การ overdraw จำนวนมากไม่ได้ส่งผลให้มีการดึงพิกเซลจำนวนมากใน Color Buffer เนื่องจากถ้าค่า z ของพิกเซลที่มีพื้นผิวนั้นมีค่ามากกว่าหนึ่งที่พบในบัฟเฟอร์ภาพดังนั้นจึงถูกทิ้งและไม่นับรวมในแบนด์วิดท์ของ Color Buffer แม้ว่าจะมีพื้นผิวมาก่อนแล้วก็ตาม
VRAM Bandwidth: กลไกการบีบอัด

ในช่วงไม่กี่ปีที่ผ่านมาการบีบอัดสีเดลต้าหรือ DCC ได้ปรากฏขึ้นเราขอแนะนำให้คุณค้นหาบทความที่เราทำในเรื่องนี้ เทคนิคเหล่านี้ขึ้นอยู่กับการบีบอัดขนาดของ Color Buffer ในลักษณะที่ใช้พื้นที่น้อยลงมากและสิ่งที่ต้องทำคือบอก GPU ว่าแต่ละพิกเซลมีค่า + n บิตโดยที่ n คือความแตกต่างระหว่าง ภาพปัจจุบันและภาพก่อนหน้า
อีกองค์ประกอบหนึ่งคือการบีบอัดพื้นผิวซึ่งแตกต่างจาก DCC และใช้เมื่อสร้างบัฟเฟอร์สีที่เราต้องการกู้คืนในภายหลังเพื่อแสดงเอฟเฟกต์หลังการประมวลผล ปัญหาคือภาพที่ใช้การบีบอัดพื้นผิวไม่เข้าใจโดยหน่วยที่อ่านภาพสุดท้ายและส่งไปที่หน้าจอ
แบนด์วิดท์และ VRAM: Tile Rendering
ในการเรนเดอร์ไทล์ทั้งบัฟเฟอร์สีและบัฟเฟอร์ความลึกจะถูกประมวลผลภายในชิปดังนั้นแบนด์วิดท์เหล่านั้นจึงไม่ถูกนำมาพิจารณา ดังนั้น GPU ที่ใช้เทคนิคนี้เช่นที่ใช้ในสมาร์ทโฟนจึงไม่ต้องการแบนด์วิดท์มากนักและสามารถทำงานกับความทรงจำที่มีแบนด์วิดท์ต่ำกว่ามาก
อย่างไรก็ตาม Tile Renderers มีชุดของความพ่ายแพ้ที่ทำให้พวกเขามีพลังดิบน้อยกว่า GPUS ที่ไม่ใช้วิธีการแสดงฉากนั้น
สรุป

การคาดเดาแบนด์วิดท์ที่ใช้โดยแต่ละเกมเป็นเรื่องยากดังนั้นจึงมีเครื่องมือเช่น NVIDIANSight และ ไมโครซอฟท์PIX ซึ่งไม่เพียง แต่วัดระดับการคำนวณในแต่ละส่วนของ GPU เท่านั้น แต่ยังรวมถึงปริมาณงานของแบนด์วิดท์อีกด้วยซึ่งช่วยให้นักพัฒนาสามารถเพิ่มประสิทธิภาพในการใช้ VRAM ได้
เหตุผลก็คือในกรณีของฉากที่มีการวาดภาพมากเกินไปพวกเขาไม่สามารถคาดเดาได้ว่าแต่ละพิกเซลในเฟรมจะมีภาระเท่าใด สำหรับทั้งสถาปนิกฮาร์ดแวร์และวิศวกรซอฟต์แวร์ทางที่ดีที่สุดคืออย่าทำให้ชีวิตยุ่งยากและวาง VRAM ที่เร็วที่สุดไว้ในค่าใช้จ่ายที่กำหนด
สิ่งที่นำมาพิจารณาคืออัตราส่วนระหว่างแบนด์วิดท์และอัตราการเติมตามทฤษฎีซึ่งประกอบด้วยการหารแบนด์วิธด้วยความแม่นยำต่อพิกเซลและเปรียบเทียบกับอัตราการเติมตามทฤษฎีของ GPU แต่เป็นปัจจัยที่น้อยลงเรื่อย ๆ โดยเฉพาะอย่างยิ่งเนื่องจาก GPU ไม่ได้วาดพิกเซลที่มีพื้นผิวแล้วลงใน VRAM โดยตรงอีกต่อไป แต่จะเขียนลงในแคช L2 ของ GPU แทนซึ่งจะช่วยลดผลกระทบต่อ VRAM