เรย์ติดตาม เป็นอัลกอริทึมสำหรับการเรนเดอร์ฉากที่ใช้กันอย่างแพร่หลายในโลกของแอนิเมชั่นออฟไลน์ แต่ในสภาพแวดล้อมแบบเรียลไทม์เช่น วิดีโอเกม ตอนนี้เป็นตอนที่มันเริ่มเกิดขึ้น ในบทความนี้เราจะพูดถึงวิวัฒนาการในอดีตปัจจุบันและอนาคตของ ฮาร์ดแวร์ เกี่ยวกับ การติดตามรังสี เพื่อให้คุณได้ทราบถึงสิ่งที่เราคาดหวัง
เช่นเดียวกับการแรสเตอร์ซึ่งในตอนแรกสามารถทำได้เฉพาะในซูเปอร์คอมพิวเตอร์จากนั้นในเวิร์กสเตชันและต่อมาในคอมพิวเตอร์ที่บ้านด้วยการ์ด 3 มิติการติดตามเรย์หรือที่รู้จักกันในชื่อภาษาอังกฤษว่า "Ray Tracing" มีวิวัฒนาการเช่นเดียวกันและเมื่อหลายปีก่อนเป็นไปได้เฉพาะกับ ระบบที่มีประสิทธิภาพและราคาแพงมากขึ้นสำหรับทุกคน

วิวัฒนาการของฮาร์ดแวร์ที่เกี่ยวข้องกับ Ray Tracing

นั่นคือเหตุผลที่เราตัดสินใจดำเนินการย้อนหลังเพื่อแสดงให้คุณเห็นถึงวิวัฒนาการของฮาร์ดแวร์เท่าที่ Ray Tracing เกี่ยวข้อง เราได้แบ่งวิวัฒนาการนี้ออกเป็นห้าขั้นตอนที่แตกต่างกันและในนั้นเราจะไม่เพียง แต่พูดถึงวิธีการในอดีต แต่ยังรวมถึงวิธีการที่เรากำลังจะได้เห็นในอนาคตอันใกล้นี้และจะถูกนำไปใช้ใน GPU รุ่นต่อ ๆ ไป ที่จะติดตั้งพีซีของเรา
ขั้นตอนที่ 1: การแสดงผลผ่าน CPU

ต้องคำนึงว่า GPU เป็นเวลานานที่เชื่อมโยงกับอัลกอริทึมการแรสเตอร์ดังนั้นจึงไม่เหมาะสำหรับการเรนเดอร์ฉากที่ใช้ Ray Tracing ซึ่งใช้อัลกอริทึมอื่น
วิธีแก้ปัญหาที่มีอยู่เมื่อคุณต้องการแสดงฉากผ่านการติดตามเรย์? การดึงซีพียูแบบมัลติคอร์และแม้ว่านี่จะเป็นส่วนหนึ่งของประวัติศาสตร์ไปแล้ว แต่ก็เป็นแนวทางที่ อินเทล ต้องการดำเนินการกับ Larrabee ที่ถูกยกเลิกและล้มเหลวเมื่อกว่าทศวรรษที่แล้วซึ่งไม่มีอะไรมากไปกว่าแกน x86 หลายตัวในการกำหนดค่าที่คล้ายกับ a GPU.

โซลูชันนี้กลายเป็นวิธีที่ไม่มีประสิทธิภาพมากที่สุดเนื่องจากซีพียูเป็นระบบสเกลาร์ที่ออกแบบมาเพื่อทำงานกับงานเดียวต่อเธรดการดำเนินการและเมื่อเทียบกับ GPU แล้วพวกเขามีเธรดน้อยมากที่ทำงานพร้อมกันทำให้จำเป็นต้องสร้างซูเปอร์คอมพิวเตอร์จำนวนมากหากไม่มี ซีพียูหลายร้อยตัวสำหรับการแสดงผล
ขั้นตอนที่ 2: Ray Tracing บน GPU ผ่าน Compute Shaders
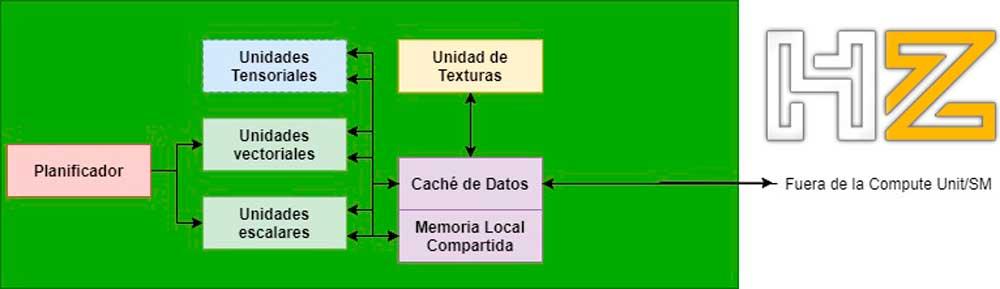
เริ่มต้นด้วย DirectX ในเวอร์ชัน 11 และ OpenGL ในเวอร์ชัน 4 โปรแกรม shader ประเภทใหม่สำหรับ GPU ที่เรียกว่า Compute Shaders ปรากฏขึ้นซึ่งไม่เกี่ยวข้องกับขั้นตอนของไปป์ไลน์กราฟิก
ต้องขอบคุณพวกเขา GPU จึงสามารถมุ่งเน้นไปที่พลังทั้งหมดหรือบางส่วนในการแก้ปัญหานอกเหนือจากการแรสเตอร์และในจำนวนนั้นมันเป็นไปได้ที่จะใช้การติดตามเรย์ใน GPU ไม่ใช่ด้วยความเร็วที่เพียงพอที่จะให้การแสดงผลแบบเรียลไทม์ แต่ใช่ตามลำดับ เพื่อดำเนินการตามขั้นตอนต่อเนื่องผ่าน Compute Shaders
แต่ก็ยังไม่ถึง DirectX 12 ที่จะเริ่มมีความเป็นไปได้ที่จะเสนอไปป์ไลน์การเรนเดอร์ที่สมบูรณ์สำหรับ Ray Tracing โดยที่แต่ละขั้นตอนเฉพาะคือ Compute Shader ที่ทำหนึ่งในขั้นตอนเหล่านี้
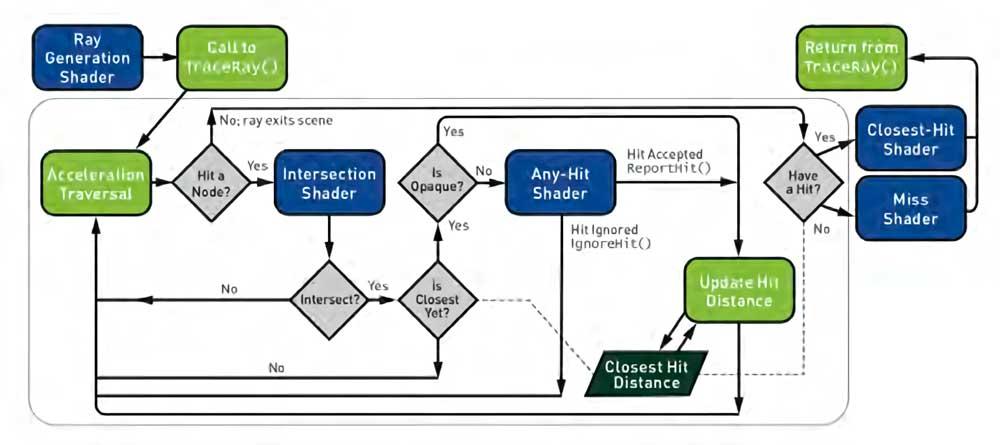
ไปป์ไลน์นี้เป็นท่อที่ได้รับการกำหนดมาตรฐานในปี 2018 โดยเป็นพื้นฐานสำหรับ DirectX Ray Tracing และต่อมาได้รับการรับรองโดย Vulkan อย่างไรก็ตามการใช้ GPU ในช่วงแรกนี้สำหรับการติดตามเรย์แบบเรียลไทม์นั้นไม่ดีพอในแง่ของประสิทธิภาพและจำเป็นต้องมีการเปลี่ยนแปลงกับ Compute Unit / SM แบบคลาสสิก
ขั้นตอนที่ 3: หน่วยของจุดตัด
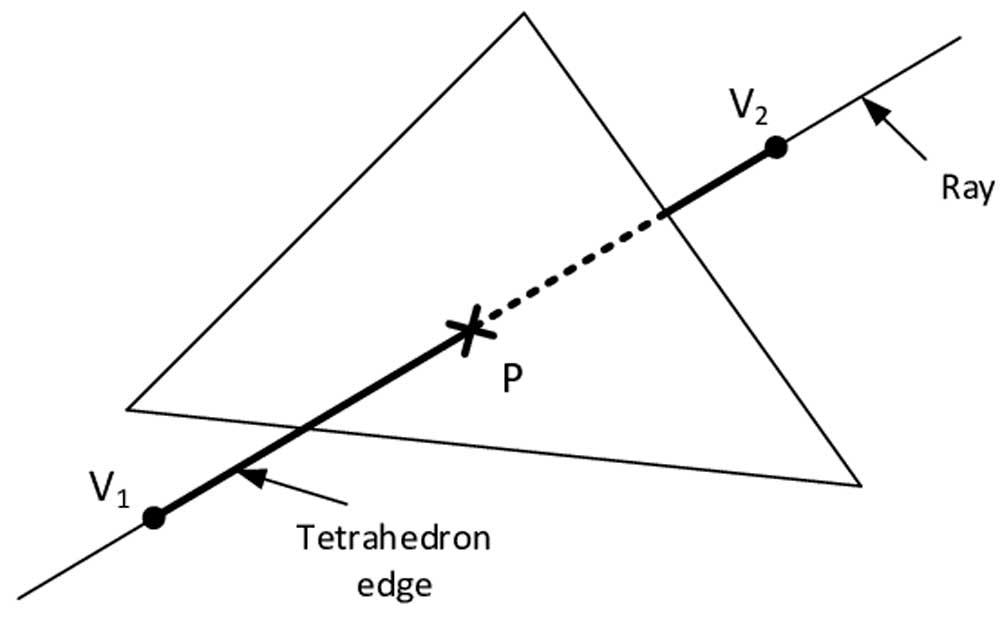
สิ่งที่พบได้ทั่วไปในการออกแบบฮาร์ดแวร์คือการสร้างตัวเร่งความเร็วเพื่อทำงานที่ซ้ำซากจำเจโดยมีต้นทุนในพื้นที่และพลังงานต่ำกว่าโปรเซสเซอร์แบบเต็มมากแนวคิดคือการยกเลิกการโหลดงานเหล่านี้บนโปรเซสเซอร์เฉพาะ
ยูนิตประเภทนี้มีอยู่ทั่วไปใน GPU ตัวอย่างเช่นเมื่อพูดถึงการแรสเตอร์เราจะพบหน่วยที่มีฟังก์ชันคงที่ซึ่งดำเนินการเช่นการแรสเตอร์รูปสามเหลี่ยมการกรองพื้นผิวเป็นต้นหน่วยเหล่านี้มีสายและทำหน้าที่จากข้อมูลอินพุตที่กำหนดให้เสมอและนั่นคือ เหตุใดจึงเรียกว่าฟังก์ชันคงที่เนื่องจากเราไม่สามารถเปลี่ยนฟังก์ชันได้นั่นคือไม่สามารถตั้งโปรแกรมได้ ข้อดีของหน่วยประเภทนี้คือช่วยให้เราทำการคำนวณเฉพาะเหล่านั้นโดยใช้หน่วยขนาดเล็กมากโดยมีปริมาณการใช้น้อยมากและทำงานควบคู่กันไป
ในการติดตามเรย์รังสีแต่ละตัวที่สร้างขึ้นในระหว่างฉากจะกระทบกับวัตถุหนึ่งชิ้นหรือมากกว่านั้นในฉากดังนั้นจึงจำเป็นต้องทำการคำนวณนี้อย่างต่อเนื่องซ้ำแล้วซ้ำเล่าซึ่งเราเรียกว่าจุดตัดกันดังนั้นจึงเป็นกระบวนการที่เหมาะสำหรับประเภทที่สิ้นสุดใน รูปแบบของหน่วยงานเฉพาะที่ทำงานควบคู่กัน
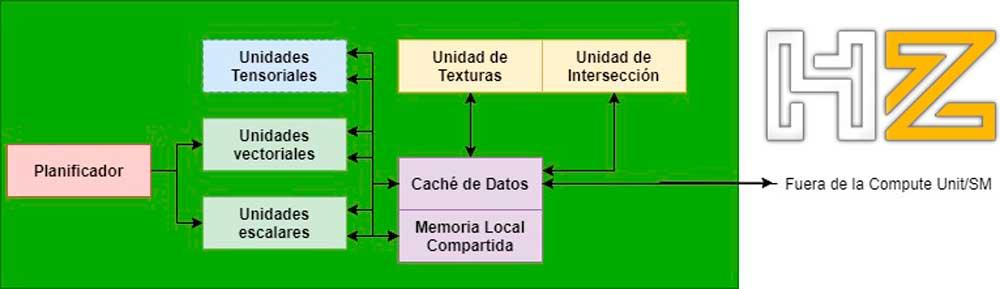
ในกรณีของหน่วยตัดกันภายใน GPU จะพบได้ในหน่วยคำนวณ / SM ในไฟล์ เอเอ็มดี / NVIDIA หน่วยกราฟิก (ในกรณีใด ๆ เรากำลังพูดถึงหน่วยประเภทเดียวกันในทั้งสองกรณี แต่ใช้ชื่อที่แตกต่างกัน) และพวกเขาสื่อสารกับ ALU ที่รับผิดชอบในการเรียกใช้เฉดสีผ่านแคชข้อมูลภายในหน่วยเดียวกัน
ขั้นตอนที่ 4: หน่วยเดินทางของต้นไม้ BVH
BVH เป็นโครงสร้างข้อมูลเชิงพื้นที่ที่จัดเก็บรูปทรงเรขาคณิตของฉากอย่างเป็นระเบียบ เพื่อให้กระบวนการคำนวณจุดตัดเร็วขึ้นสิ่งที่ทำได้คือทำสิ่งนี้บนต้นไม้ BVH แทนที่จะทำทีละพิกเซล
หากไม่มีหน่วยที่รับผิดชอบในการข้ามต้นไม้ BVH จำเป็นต้องทำด้วยโปรแกรม compute shader แต่ด้วยหน่วยงานเหล่านี้ที่นำไปใช้ในระดับฮาร์ดแวร์เราลืมที่จะต้องดำเนินการตามกระบวนการ
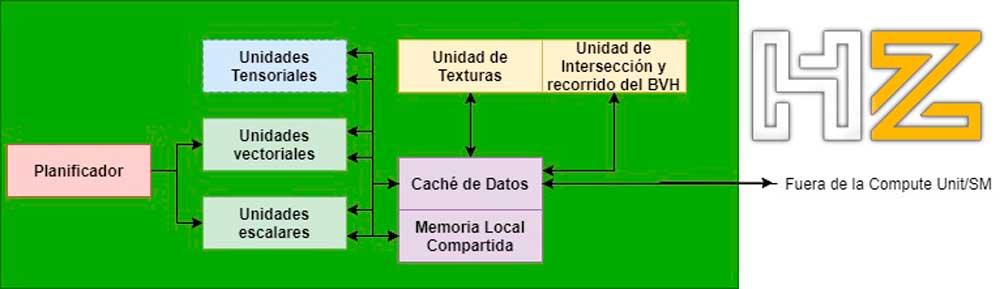
กล่าวอีกนัยหนึ่งหน่วยเส้นทางจะสร้างรังสีทั้งหมดและเส้นทางผ่านต้นไม้ BVH โดยอัตโนมัติโดยไม่ต้องมีส่วนร่วมของโปรแกรม shader และจะโต้ตอบกับหน่วยตัดกัน ทั้งในตอนท้ายของกระบวนการจะส่งผลลัพธ์กลับมา
ต้องคำนึงว่าใน DirectX 12 Ultimate เวอร์ชันปัจจุบันนี้ไม่ได้เป็นส่วนหนึ่งของข้อกำหนดขั้นต่ำและจำเป็นต้องควบคุมการสร้างรังสีใหม่จากจุดตัดของวัตถุอื่นกับวัตถุผ่าน Ray Generation Shader ดังนั้นการใช้หน่วยนี้จึงมี จำกัด เนื่องจากเป็นที่ต้องการให้ผู้พัฒนาเกมมีอำนาจในขณะนี้เกี่ยวกับความหนาแน่นของสายฟ้าในฉาก
ขั้นที่ 5: การติดตามเรย์ที่สอดคล้องกัน
ขั้นตอนต่อไปของวิวัฒนาการของ GPU สำหรับ Ray Tracing คือการเพิ่มหน่วยเชื่อมโยงกันใน GPU แต่ก่อนอื่นเราต้องเข้าใจว่าเราหมายถึงอะไรด้วยการเชื่อมโยงกันของหน่วยความจำจากมุมมองของโปรเซสเซอร์ใด ๆ ซึ่งเป็นสิ่งที่ วิสัยทัศน์ของหน่วยความจำของโปรเซสเซอร์แต่ละตัวจะเหมือนกันโดยเฉพาะ GPU ร่วมสมัย
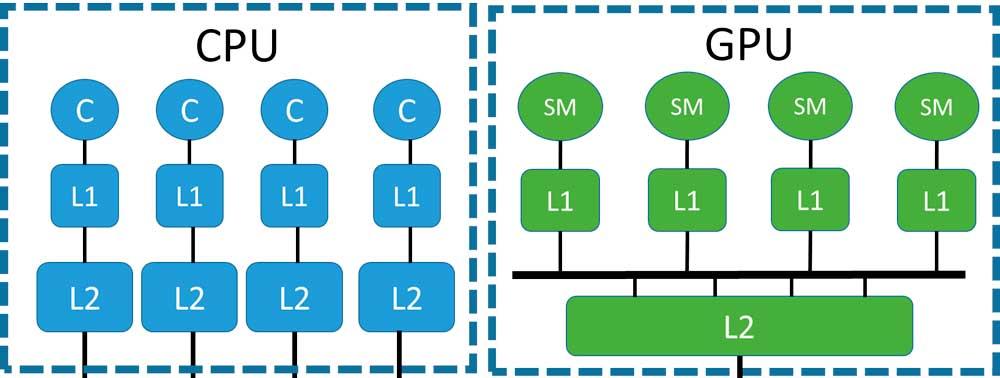
หากเราต้องการเข้าใจปัญหาเกี่ยวกับการเชื่อมโยงกันของหน่วยความจำเราต้องเข้าใจว่ากลไกการแคชของระบบมัลติโปรเซสเซอร์ทำงานอย่างไรไม่ว่าเราจะพูดถึง ซีพียู หรือ GPU
- แคชไม่ใช่ RAM แต่จะจัดเก็บบางส่วนของ RAM หรือระดับแคชที่สูงกว่า
- แคชระดับล่างและใกล้เคียงที่สุดกับโปรเซสเซอร์จะมีสำเนาบางส่วนของข้อมูลจากแคชระดับที่สูงกว่า
ดังนั้นหากเราต้องการสร้างระบบที่เชื่อมโยงกันจะต้องมีการสร้างกลไกที่เมื่อแกนหรือหน่วยอื่น ๆ ของ GPU เปลี่ยนค่าของข้อมูลสำเนาทั้งหมดที่อ้างถึงข้อมูลนั้นในแคชทั้งหมดก็จะเปลี่ยนไปด้วยเช่นกัน วิธีการพร้อมกันและใน VRAM
GPU กำลังเผชิญปัญหาอะไรอยู่ตอนนี้? ก่อนหน้านี้เราได้ให้ความเห็นว่าจุดตัดและหน่วยการเคลื่อนที่ของ BVH สามารถเข้าถึงแคชข้อมูลของ Compute Unit / SM ได้ แต่เนื่องจากไม่มีกลไกที่สอดคล้องกันเมื่อมีการเปลี่ยนแปลงข้อมูลใน Compute Unit / SM แล้ว ส่วนที่เหลือของหน่วยไม่ทราบและสิ่งนี้นำไปสู่ส่วนที่ดีของจุดตัดและการคำนวณระยะทางที่ถูกทำซ้ำแม้ว่าหน่วยอื่นจะดำเนินการไปแล้วก็ตาม
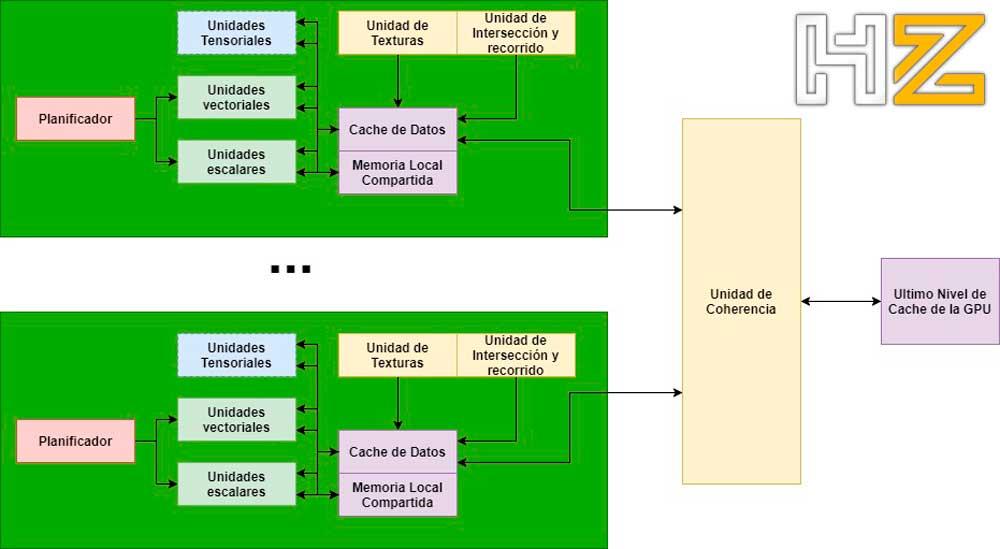
หน่วยเชื่อมโยงเป็นหน่วยฮาร์ดแวร์อย่างน้อยหนึ่งหน่วยที่รับผิดชอบในการแจ้งการเปลี่ยนแปลงของหน่วยประมวลผล / SM ทั้งหมดในเนื้อหาของแคชดังนั้นจึงเป็นเรื่องยากที่จะนำฮาร์ดแวร์ไปใช้เนื่องจากจำนวนการสื่อสารระหว่างกันที่ต้องการ
ในซีพียูการเชื่อมโยงกันสามารถทำได้อย่างง่ายดายเนื่องจากเรามีคอร์น้อยมากภายใน แต่ใน GPU จำนวนคอร์ที่มากขึ้นทำให้ระบบเชื่อมโยงกันใช้งานได้ยาก โปรดทราบว่าจำนวนเส้นทางข้อมูลที่ต้องดำเนินการคือ n 2 โดยที่ n คือจำนวนองค์ประกอบที่เชื่อมต่อกัน
เนื่องจาก GPU กำลังจะถูกแบ่งออกเป็นชิปเล็ตจึงมีความเป็นไปได้ค่อนข้างมากที่หน่วยการเชื่อมโยงนี้จะกลายเป็นชิปเล็ตเองหรืออยู่ในส่วนศูนย์กลางในการสื่อสารส่วนต่างๆซึ่งกันและกัน ไม่ว่าในกรณีใดเรายังไม่ถึงจุดนี้และเนื่องจากการเปลี่ยนแปลงในระดับของสถาปัตยกรรมกำลังเกิดขึ้นในช่วง 2 ถึง 5 ปีเรายังคงต้องรออีกเล็กน้อย
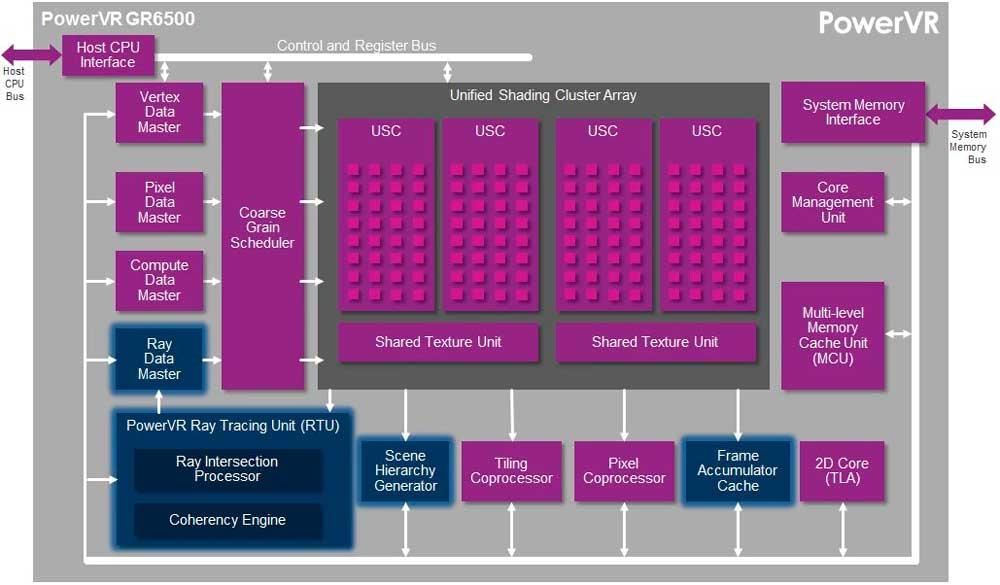
จุดที่ Coherency Engine ถูกนำไปใช้นั้นอยู่ในสถาปัตยกรรม PowerVR Wizard ของ Imagination เนื่องจากมีการใช้งานในฮาร์ดแวร์นั้นมาหลายปีแล้ว แต่ NVIDIA และ AMD ยังไม่ได้นำมาใช้ใน GPU ของพวกเขาและต้องคำนึงว่าพวกเขาเข้าใกล้ "เล็กน้อย ” แตกต่างจากจินตนาการ; ไม่ว่าในกรณีใดมันเป็นวิวัฒนาการต่อไปสำหรับ Ray Tracing
