GPU ที่ใช้ชิปเล็ตมีมานานแล้วโดยเฉพาะอย่างยิ่งเมื่อเกิดปัญหาทั้งสองอย่าง NVIDIA และ เอเอ็มดี ในช่วงไม่กี่ปีที่ผ่านมากำลังปรับขนาด GPU เกินขีด จำกัด ทางกายภาพ . พวกเขาจะเป็นอย่างไรและอะไรคือแรงจูงใจในการออกแบบ GPU แบบใหม่นี้
หากเราสังเกต GPU ที่เปิดตัวในช่วงไม่กี่ปีที่ผ่านมาโดย AMD แต่โดยเฉพาะอย่างยิ่งโดย NVIDIA เราจะเห็นว่าพื้นที่ที่พวกเขาครอบครองนั้นเพิ่มขึ้นและหากไม่กี่ปีที่ผ่านมา GPU มากกว่า 400 mm2 ถูกมองว่ามีขนาดใหญ่ตอนนี้เรามีมากกว่า 600 mm2

แนวโน้มนี้หมายความว่ามีอันตรายที่จะถึงขีด จำกัด ของกริดในช่วงเวลาหนึ่งขีด จำกัด ดังกล่าวคือพื้นที่ จำกัด ที่ชิปสามารถมีได้ในโหนดการผลิตที่กำหนดและในลักษณะที่เป็นอันตรายและสิ่งต่างๆจะซับซ้อนหากเราไม่เลือกปฏิบัติ เพิ่มจำนวนคอร์ที่ประกอบเป็น GPU
การจำลองสถานีและรถไฟ

สมมติว่าเรามีเครือข่ายรถไฟที่มีสถานีรถไฟหลายแห่งแต่ละสถานีเป็นตัวประมวลผลและรถไฟคือแพ็กเก็ตข้อมูลที่ส่ง
เห็นได้ชัดว่าหากเครือข่ายรถไฟของเรามีจำนวนสถานีเพิ่มขึ้นเราก็จะต้องมีรางเพิ่มขึ้นเรื่อย ๆ และโครงสร้างพื้นฐานที่ซับซ้อนมากขึ้น ในกรณีของโปรเซสเซอร์จะเหมือนกันเนื่องจากการเพิ่มจำนวนองค์ประกอบหมายถึงการเพิ่มจำนวนช่องทางการสื่อสารระหว่างองค์ประกอบต่างๆ
ปัญหาคือรางรถไฟเพิ่มเติมเหล่านี้จะเพิ่มการใช้พลังงานด้วยดังนั้นใครก็ตามที่ทุ่มเทให้กับการออกแบบเครือข่ายรถไฟไม่เพียง แต่ต้องคำนึงถึงจำนวนรางที่สามารถวางในโครงสร้างพื้นฐานได้ แต่ยังต้องใช้พลังงานอีกด้วย
กฎของมัวร์ไม่ได้ขยายขนาดเท่าที่คุณคิด
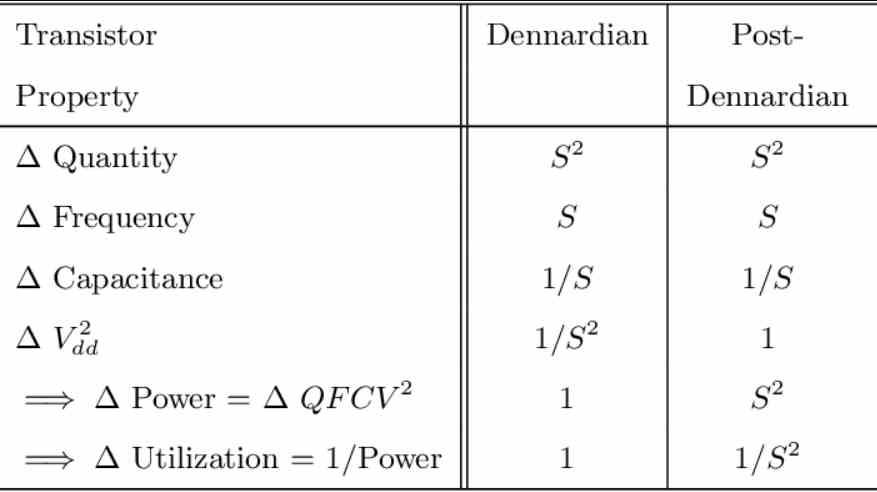
ตามกฎของมัวร์ความหนาแน่นของจำนวนทรานซิสเตอร์ต่อพื้นที่เพิ่มขึ้นเป็นสองเท่าทุกครั้งที่ x เป็นประจำซึ่งมาพร้อมกับสเกลเดนนาร์ดซึ่งบอกเราว่าความเร็วสัญญาณนาฬิกาที่สามารถปรับขนาดได้กับโหนดการผลิตใหม่แต่ละโหนด สเกล Dennard เดิมเปลี่ยนเมตริกจากโหนด 65 นาโนเมตรเป็นต้นไป
ปัญหาเกิดขึ้นเมื่อเราเพิ่มจำนวนองค์ประกอบ / รถไฟและเส้นทางการสื่อสารเราสามารถวางองค์ประกอบได้มากเป็นสองเท่า แต่สิ่งที่เราไม่สามารถทำได้คือตรวจสอบให้แน่ใจว่าเรามีแบนด์วิดท์ที่จำเป็นในการสื่อสารองค์ประกอบเหล่านั้นทั้งหมดในเวลาเดียวกันภายใต้การบริโภคเดียวกัน กำหนดซึ่งเป็นไปไม่ได้และจะ จำกัด จำนวนคอร์ในกรณีของ GPU จำนวนหน่วยคำนวณ

ทางออกที่ยึดถือมาโดยตลอด? แทนที่จะเพิ่มองค์ประกอบมากขึ้นสิ่งที่ทำคือการทำให้สิ่งเหล่านี้ซับซ้อนขึ้นเรื่อย ๆ เช่นในกรณีของ GPU ซึ่งเป็นเส้นทางที่ NVIDIA ใช้มาจาก Turing แทนที่จะเพิ่มจำนวน SM เมื่อเทียบกับ Pascal สิ่งที่เขาทำคือเพิ่มองค์ประกอบต่างๆเช่น RT Cores, Tensor Cores และทำการเปลี่ยนแปลงอย่างลึกซึ้งในหน่วยเนื่องจากการเพิ่มจำนวนคอร์หมายถึงการเพิ่มจำนวนการเชื่อมต่อระหว่างกัน
ดังนั้นเราจึงพบว่าตัวเองมีปัญหาเรื่องต้นทุนพลังงานในการส่งข้อมูล / รถไฟโดยแต่ละโหนดการผลิตใหม่เราสามารถเพิ่มจำนวนองค์ประกอบบนชิปได้ แต่เราพบว่าความเร็วในการถ่ายโอนที่เราต้องการนั้นสูงมากขึ้นเรื่อย ๆ ซึ่งจะเพิ่มการใช้พลังงาน ทำให้พลังงานส่วนใหญ่ที่เรามอบให้กับโปรเซสเซอร์เปลี่ยนไปเป็นการถ่ายโอนข้อมูลแทนการประมวลผลข้อมูล
การสร้าง GPU ด้วยชิปเล็ตจากที่รู้จัก
แนวคิดในการสร้าง GPU โดยชิปเล็ตคือการสร้าง GPU ที่ไม่สามารถผลิตจากโครงสร้างเสาหินได้ดังนั้นจึงต้องใช้ชิปตัวเดียวดังนั้นพื้นที่ของ GPU ที่สร้างด้วยชิปเล็ตจะต้องมีขนาดใหญ่ขึ้นซึ่งจะ อนุญาตให้มีขีด จำกัด ของเส้นเล็งเนื่องจาก GPU ประเภทนี้จะไม่สมเหตุสมผล
ซึ่งหมายความว่า GPU ที่ประกอบด้วยชิปเล็ตจะถูกสงวนไว้เฉพาะสำหรับช่วงสูงสุดและเป็นไปได้ว่าในตอนแรกเราจะเห็นเฉพาะในตลาด GPU สำหรับการประมวลผลประสิทธิภาพสูง HPC ในขณะที่ในบ้านเราอีกไม่กี่ปี ด้วย GPU ที่ง่ายกว่ามากในการกำหนดค่าจึงเป็นเสาหิน
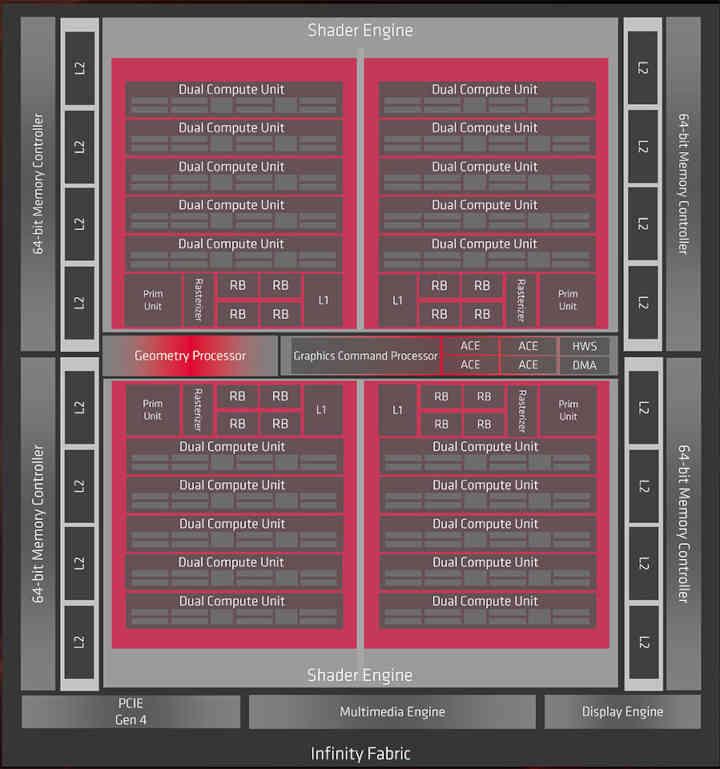
อย่างไรก็ตามเราได้ตัดสินใจที่จะใช้ชิป Navi 10 ซึ่งมีสถาปัตยกรรม RDNA รุ่นแรกเป็นตัวอย่างในการแยกโครงสร้างและสร้าง GPU ของเราที่ประกอบด้วยชิปเล็ตส่วนใหญ่เป็นเพราะเป็น GPU รุ่นล่าสุดที่เรามีข้อมูลมากที่สุดใน ตาราง. GPU ที่ AMD และ / หรือ NVIDIA สร้างจะมีความซับซ้อนมากกว่าตัวอย่างนี้มากซึ่งบ่งบอกได้เพื่อให้คุณมีภาพจิตที่จะสร้าง GPU ประเภทนี้
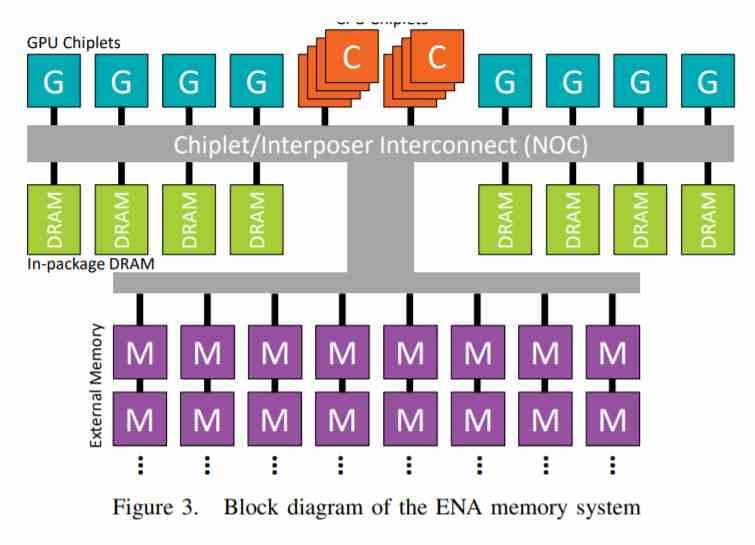
แนวคิดแรกคือชิปเล็ตแต่ละตัวคือ Shader Array ซึ่งเป็นชุดขององค์ประกอบที่อยู่ในกล่องสีชมพูซึ่งเชื่อมต่อกับแคช L1 ในขณะที่เราจะทิ้ง L2 Cache ไว้ในชิปกลางที่แยกจากกัน
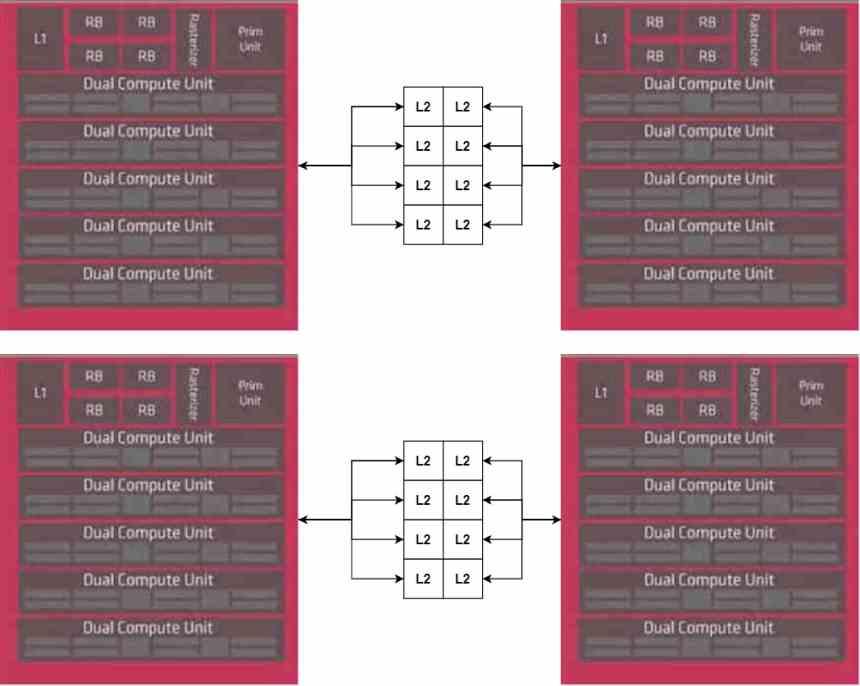
แต่เราไม่มี GPU ที่สมบูรณ์เนื่องจากเราขาดส่วนกลางซึ่งเป็นหน่วยประมวลผลคำสั่งซึ่งเป็นส่วนเดียวเราจะไม่ทำซ้ำดังนั้นเราจะวางไว้ในส่วนกลางของ MCM
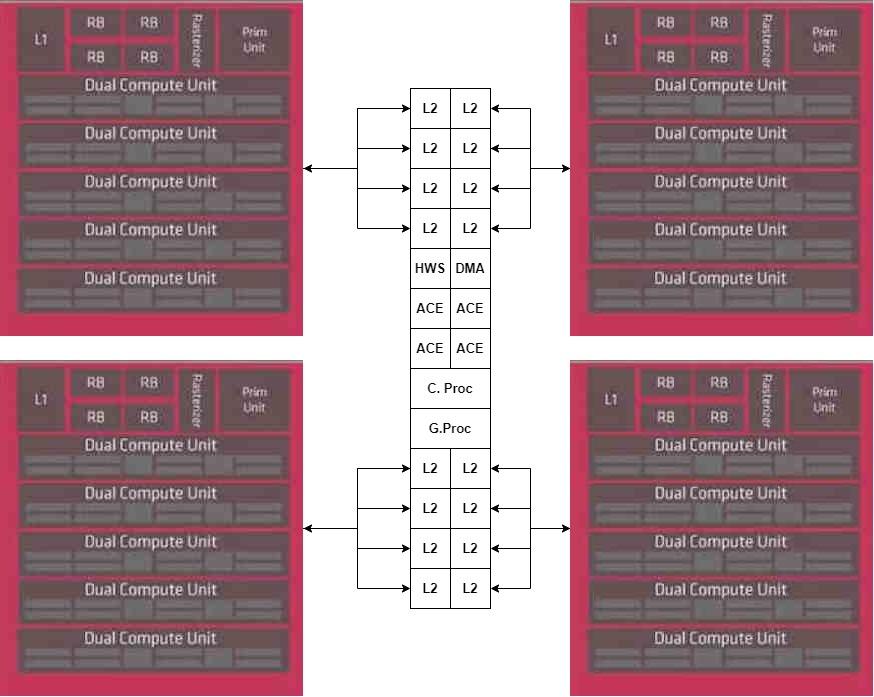
สำหรับตัวเร่งความเร็วเราจะวางไว้ในชิปเล็ตอื่นซึ่งเชื่อมต่อโดยตรงกับหน่วย DMA ของชิปเล็ตกลาง
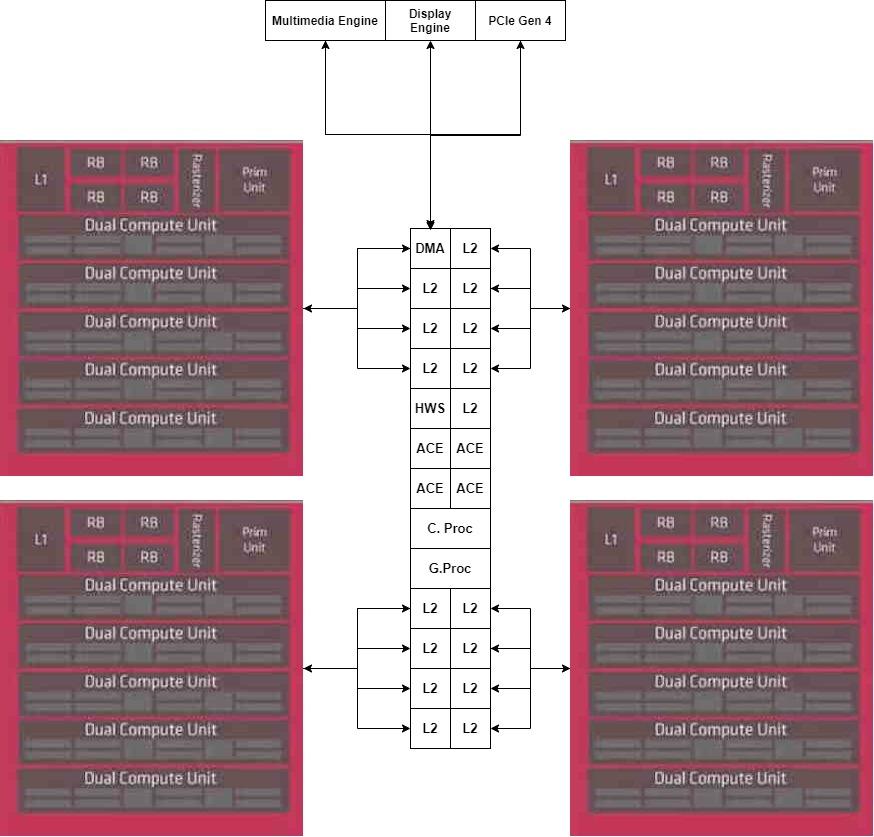
เมื่อเราแยก GPU ออกเป็นหลายส่วนแล้วสิ่งที่เราสนใจในตอนนี้คือการสื่อสารกับหน่วยความจำภายนอกสิ่งนี้จะดำเนินการโดย Interposer ซึ่งจะมีตัวควบคุมหน่วยความจำรวมอยู่ภายใน เนื่องจาก Navi 10 ใช้อินเทอร์เฟซ GDDR256 แบบ 8 บิต 6 ชิปเราจึงตัดสินใจเก็บการกำหนดค่านั้นไว้ในตัวอย่างของเรา
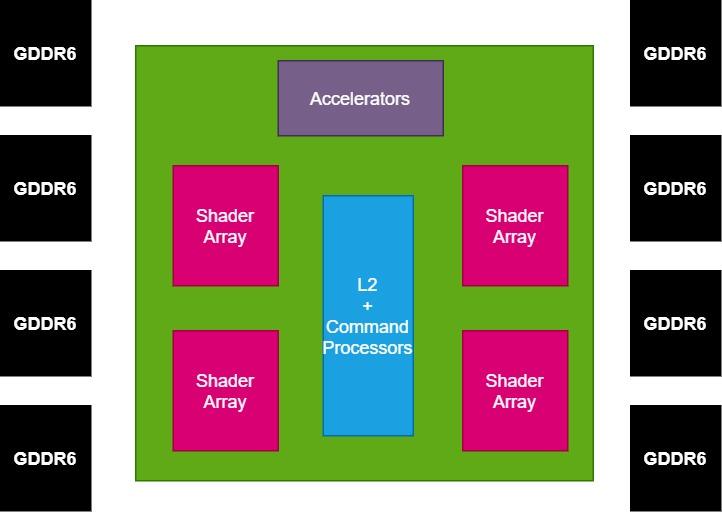
GPU ขึ้นอยู่กับชิปเล็ตและการใช้พลังงาน
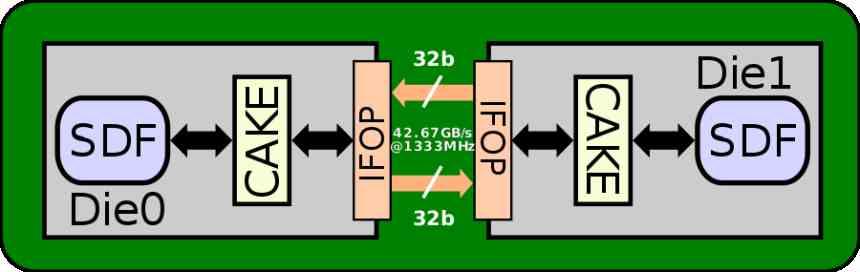
อินเทอร์เฟซที่ใช้ในการสื่อสารองค์ประกอบของชิปเล็ตที่แตกต่างกันคือ AMD MCM เป็นอินเทอร์เฟซ IFOP ซึ่งมีการใช้พลังงาน 2 pJ / bit หากเราดูข้อกำหนดทางเทคนิคเราจะเห็นว่าแคช L2 มีแบนด์วิดท์ 1.95 TB / ความเร็ว 1905 MHz ซึ่งมีขนาดประมาณ 1024 ไบต์ซึ่งทำงานได้กับ 16 อินเทอร์เฟซ 64 ไบต์ / รอบ 32B / รอบต่อที่อยู่
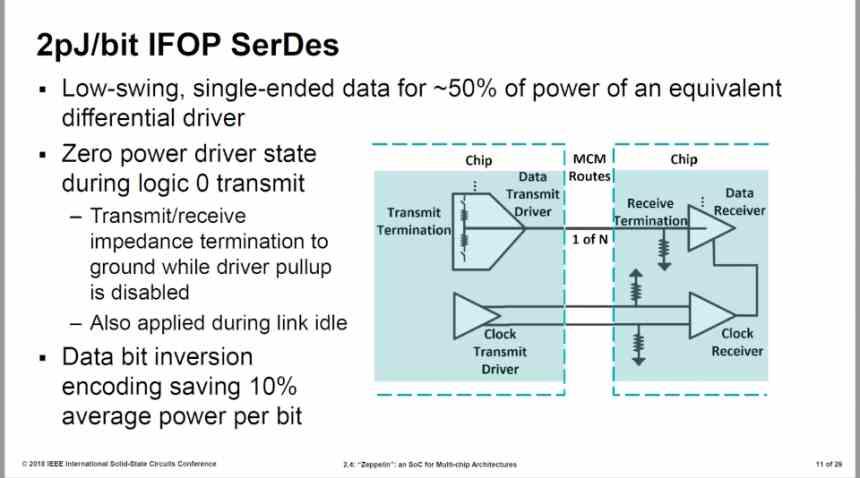
Infinity Fabric รุ่นแรกใช้อินเทอร์เฟซ 32B / รอบโดยใช้ความเร็ว 2 pJ / bit แต่ AMD ปรับปรุงขึ้น 27%
อินเทอร์เฟซ IFOP มีการใช้พลังงาน 1.47 pJ / bit ที่ความเร็ว 1333 MHz หากอินเทอร์เฟซอยู่ที่ 1905 MHz การใช้พลังงานจะสูงขึ้นมากเนื่องจากไม่เพียงเพิ่มความเร็วสัญญาณนาฬิกาเท่านั้น แต่ยังรวมถึงแรงดันไฟฟ้าด้วย แต่สมมติว่า Navi 10 รุ่น chiplet ของเราทำงานที่ความเร็ว 1333 MHz
(1.33 * 10 ^ 12) * 8 บิตต่อไบต์ * 1.47 pJ ต่อบิต = 1.56 * 10 ^ 13 pJ = 15.6 W
แม้ว่า 15.6 W อาจดูเป็นตัวเลขที่ต่ำสำหรับเรา แต่โปรดทราบว่านี่เป็นเพียงการใช้งานในการส่งข้อมูลของชิปเพล็ตต่อพ่วงด้วยชิปเล็ตกลางที่ความเร็ว 1333 MHz และการใช้พลังงานจะเพิ่มขึ้นเป็นสี่เท่าด้วยความเร็วสัญญาณนาฬิกา . และแรงดันไฟฟ้าก็เพิ่มขึ้นด้วย
ซึ่งหมายความว่าส่วนที่ดีของการใช้พลังงานจะไปที่การใช้พลังงานของการสื่อสารระหว่างชิปเล็ตโดยตรงซึ่งหมายความว่าทั้ง AMD และ NVIDIA ต้องแก้ปัญหานี้ก่อนที่จะติดตั้ง GPU ที่ใช้ชิปเล็ต
EHP ของ AMD เป็นตัวอย่างของ GPU ที่ใช้ชิปเล็ต
ไม่กี่ปีที่ผ่านมา AMD ได้เปิดตัวบทความที่อธิบายถึงโปรเซสเซอร์ที่ใช้ชิปเล็ตซึ่งมี GPU ที่ซับซ้อนมากซึ่งพวกเขาได้พูดถึงการกำหนดค่าเช่น 320 Compute Units ใน 8 ชิปเล็ตซึ่งแปลเป็นหน่วยประมวลผล 40 หน่วยต่อชิปเล็ตซึ่งเทียบเท่ากัน เป็น Navi เต็ม 10
กล่าวอีกนัยหนึ่งเรากำลังพูดถึงการกำหนดค่าที่ซับซ้อนกว่า 8 เท่าดังนั้นลองนึกภาพการกำหนดค่าที่มีชิปเล็ต 8 ตัวซึ่งแต่ละตัวจะเหมือน Navi 10 / RDNA และทำงานด้วยความเร็วสูงกว่า 2 GHz และใช้พลังงานมหาศาล

นี่คือเหตุผลที่ AMD และ NVIDIA ได้พัฒนาเทคโนโลยีเช่น X3D และ GRS ซึ่งเป็นอินเทอร์เฟซการสื่อสารที่มีการใช้พลังงานต่อบิตที่ส่งสัญญาณต่ำกว่า Infinity Fabric หรือ NVLink ในปัจจุบันถึง 10 เท่าเนื่องจากไม่มีอินเทอร์เฟซการสื่อสารแบบนั้น ชนิดเป็นไปไม่ได้ในอนาคตของ GPU ที่ใช้ชิปเล็ต
