
グラフィックカードの注目を集めるものがあるとすれば、それは彼らの記憶が運ぶ巨大な速度であり、彼らが毎秒送信するデータの量、つまり帯域幅として知られている速度として理解しています。 しかし、GPUがVRAMの帯域幅を非常に大きくする必要がある理由は何ですか? それらを説明します。
次に、グラフィックカードが高速転送速度の特別なメモリを使用するという事実の背後にある理論を説明します。多くの概念は事前に知っているものもあれば、グラフィックカードのマーケティングでは通常議論されないため不明なものもあります。
GPUとVRAM間の帯域幅

GPU さまざまな帯域幅を使用してシーンを3Dでレンダリングします。これを以下に示します。
- カラーバッファ(Bc): これは、GPUがシーンを描画するいわゆるバックバッファーまたはバックバッファーの一部です。 その中で、各ピクセルにはRGBAコンポーネントがあり、レンダリングが遅れると、Gバッファーを生成するためにいくつかのバッファーが生成されます。 現在のAPIでは、GPUはこのタイプの最大8つのバッファーを同時にサポートします。
- デプスバッファ(Bz): またとして知られています Zバッファ、それ カメラに対する各オブジェクトのピクセルの位置が保存されるバッファです。 ステンシルバッファと組み合わせます。 カラーバッファとは異なり、これはテクスチャリング後の段階では生成されませんが、前の段階ではラスタライズされます。
- テクスチャリング(Bt): GPUは非常に大きなテクスチャマップを使用するため、メモリに収まらず、VRAMからインポートする必要があります。これは読み取り専用の操作です。 一方、後処理エフェクトは、画像バッファをテクスチャであるかのように読み取ります。
これは、次の図に要約されています。
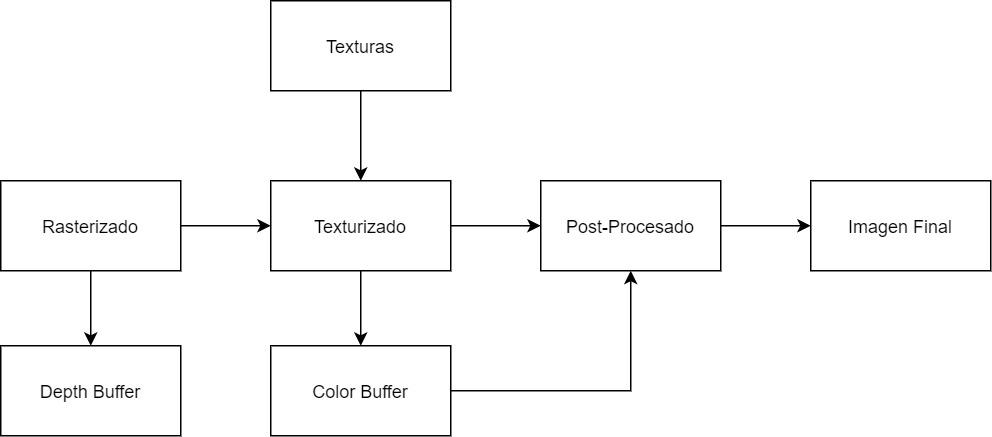
VRAMメモリチップは 全二重 読み取りと書き込みの両方を同時に送信すると、帯域幅は両方向で同じになります。 より多くの処理が行われるグラフィカルパイプラインの正確な部分はテクスチャリング中です。したがって、GPUが広い歩行幅を必要とする理由の最初の説明のXNUMXつです。
事前ラスタライズプロセスで使用されるデータ、つまりシーンのジオメトリの計算に関しては、これらは十分に低く、大量のメモリが使用されることはなく、VRAMとして使用されるメモリのタイプに影響を与えません。
オーバードローの問題

シーンのレンダリングに使用されるアルゴリズムはラスタライズであり、zバッファアルゴリズムまたは画家のアルゴリズムとも呼ばれます。これは、基本形式で次の構造を持っています。シーン内の各プリミティブに対して、プリミティブによってカバーされる各ピクセルに対して、ピクセルをマークします。カメラに最も近く、Zバッファに保存します。
これにより、複数のオブジェクトがカメラに対してX座標軸とY座標軸の同じ位置にあるが、Z軸に対して異なる位置にある場合、それぞれのピクセルが最終画像に描画されます。バッファリングし、複数回処理を終了します。 この効果は、GPUが同じ位置でピクセルをペイントおよび再ペイントするため、オーバードローまたはオーバードローと呼ばれます。
さて、あなた方の何人かは正しく次のことを考えています:テクスチャリングの前に深度バッファが生成された場合、その段階でピクセルが破棄されないのはどうしてですか? 実際にはそのためのテクニックがありますが、その段階では各ピクセルの色を完全に認識しておらず、オブジェクトが半透明であるかどうかに関係なく、GPUはオブジェクトがXNUMXつしかないシーンのすべてのピクセルを破棄することはできません。 それ以降、その表現は正しくありません。
ミドルソートとラストソート
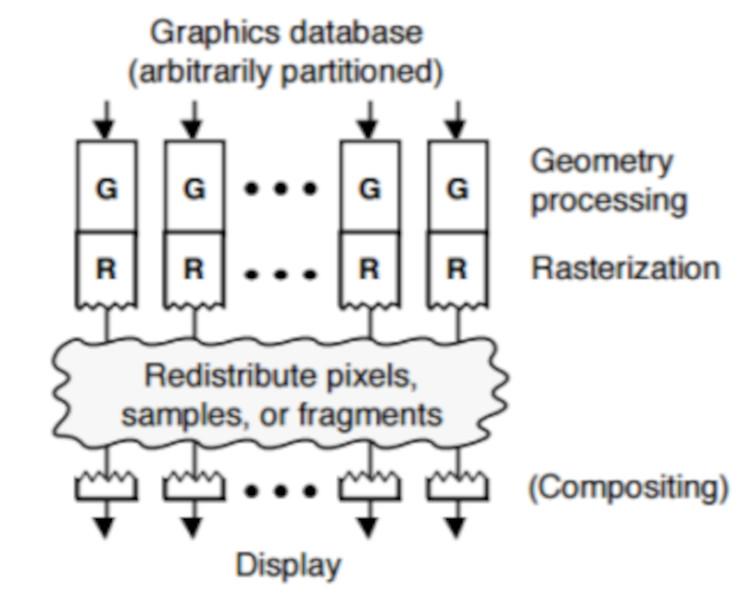
ピクセルをXNUMXつずつチェックして、ピクセルが表示されているかどうかを確認するプロセスでは、GPUに追加の回路が必要であり、レンダリングプロセスがその影響を受けていることを確認します。 GPUのアイデアは、他の要素を考慮しない総電力のアイデアです。実行する最適化がある場合、これはハードウェア部分に任されます。そのため、ピクセルがイメージバッファーまたはそれを移動する必要があることを確認します。ラストソートと呼ばれるプロセスの最後には実行されません。
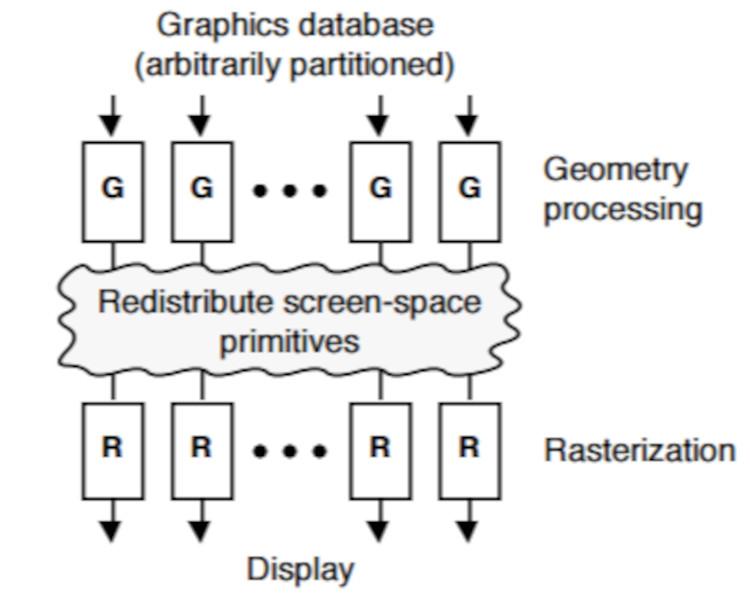
一方、オブジェクトがラスターフェーズ中に、深さバッファーを参照として使用してソートされる場合、グラフィカルパイプラインの真ん中で発生するため、ミドルソートと呼びます。
XNUMX番目の手法はオーバードローを回避しますが、前に見たように、シーンに透明度がある場合は問題があります。 そして、現在のGPUは何を使用していますか? 開発者はどちらのタイプを選択するかを選択できるので、両方です。 違いは、ミドルソートではオーバードローがないことです。
帯域幅とVRAM:オーバードロー
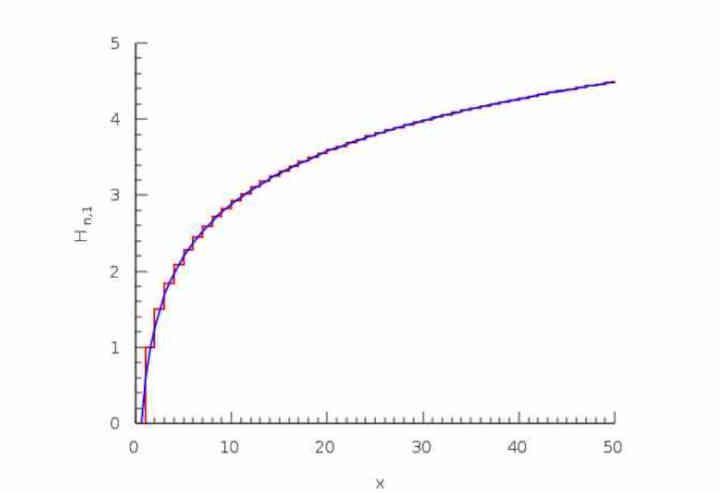
オーバードローの背後にあるロジックは、位置(x、y)の最初のピクセルがイメージバッファーにyesまたはyesで描画され、同じ位置にある50番目のピクセルが50%以上のZ値を持つ可能性があるというものです。 %小さいものを持つ可能性があるため、最終バッファーに書き込まれます。1番目は既存の可能性の3 / 1、4番目はXNUMX/XNUMXです。
これは調和級数と呼ばれます。
H(n) = 1 + 1/2 + 1/3 + 1/4…1 / n
何でこれが大切ですか? ええと、オーバードローによって破棄されるピクセルは非常に大きいのですが、値zの場合、大量のオーバードローによってカラーバッファに大量のピクセルが描画されることはありません。すでにテクスチャリングされたピクセルのうち、画像バッファにあるピクセルよりも大きいため、以前にテクスチャリングされていたとしても、破棄され、カラーバッファの帯域幅にはカウントされません。
VRAM帯域幅:圧縮メカニズム

近年、いわゆるデルタカラーコンプレッションまたはDCCが登場しました。このテーマについて行った記事を探すことをお勧めします。 これらの手法は、占有するカラーバッファのサイズをはるかに少なくするように圧縮することに基づいており、各ピクセルの値が+ nビットであることをGPUに通知します。ここで、nは現在の画像と前の画像。
もうXNUMXつの要素はテクスチャ圧縮です。これはDCCとは異なり、後処理効果を実行するために後で回復するカラーバッファを生成するときに使用されます。 問題は、テクスチャ圧縮を使用する画像が、最終的な画像を読み取って画面に送信するユニットによって理解されないことです。
帯域幅とVRAM:タイルレンダリング
タイルレンダリングでは、カラーバッファとデプスバッファの両方がチップ内で内部的に処理されるため、これらの帯域幅は考慮されません。 したがって、スマートフォンで使用されているようなこの手法を使用するGPUは、それほど多くの帯域幅を必要とせず、はるかに低い帯域幅のメモリで動作できます。
ただし、タイルレンダラーには一連の挫折があり、シーンをレンダリングする方法を使用しないGPUよりも生のパワーが少なくなります。
結論

各ゲームで使用されている帯域幅を推測するのは難しいため、次のようなツールがあります。 NVIDIAのNSightと MicrosoftのPIXは、GPUの各部分の計算負荷のレベルだけでなく、帯域幅のスループットも測定するため、開発者はVRAMの使用を最適化できます。
これは、オーバードローされたシーンの場合、フレーム内の各ピクセルの負荷がどのようになるかを予測できないためです。 ハードウェアアーキテクトとソフトウェアエンジニアの両方にとって、人生を複雑にせず、規定のコスト内に最速のVRAMを配置することが最善です。
考慮されるのは、帯域幅と理論上の充填率の比率です。これは、帯域幅をピクセルあたりの精度で除算し、GPUの理論上の充填率と比較することで構成されますが、これはますます少なくなる要因です。特に、GPUがすでにテクスチャ化されたピクセルをVRAMに直接描画するのではなく、GPU自体のL2キャッシュに書き込むため、VRAMへの影響が軽減されます。
