
S'il y a quelque chose qui attire l'attention des cartes graphiques, c'est l'énorme vitesse que transportent leurs mémoires, comprenant comme vitesse la quantité de données qu'elles transmettent par seconde, c'est-à-dire ce qu'on appelle la bande passante. Mais quelles sont les raisons pour lesquelles les GPU ont besoin de la bande passante de la VRAM pour être si grande? Nous vous les expliquons.
Ensuite, nous allons expliquer la théorie derrière le fait que les cartes graphiques utilisent des mémoires spéciales avec une vitesse de transfert élevée, certains concepts que beaucoup connaîtront déjà à l'avance, tandis que d'autres seront inconnus car ils ne sont généralement pas abordés dans le marketing des cartes graphiques.
Les bandes passantes entre le GPU et la VRAM

Les GPU utilise différentes bandes passantes pour rendre une scène en 3D, que nous énumérerons ci-dessous:
- Tampon de couleur (Bc): Il fait partie du soi-disant Backbuffer ou back buffer sur lequel le GPU dessine la scène. Dans celui-ci, chaque pixel a des composants RGBA, si le rendu est retardé, plusieurs tampons sont générés pour générer le G-Buffer. Dans les API actuelles, les GPU prennent en charge jusqu'à 8 tampons de ce type en même temps.
- Tampon de profondeur (Bz): Aussi connu sous le nom Z-Buffer, il est le tampon dans lequel la position des pixels de chaque objet par rapport à la caméra est stockée. se combine avec le tampon de pochoir. Contrairement au tampon de couleur, celui-ci n'est pas généré pendant la phase de post-texturation, mais dans la précédente, la pixellisation.
- Texturation (Bt): Les GPU utilisent des cartes de texture si grandes qu'elles ne tiennent pas dans la mémoire et doivent être importées depuis la VRAM, c'est une opération en lecture seule. D'autre part, les effets de post-traitement lisent le tampon d'image comme s'il s'agissait de textures.
Ceci est résumé dans le diagramme suivant:
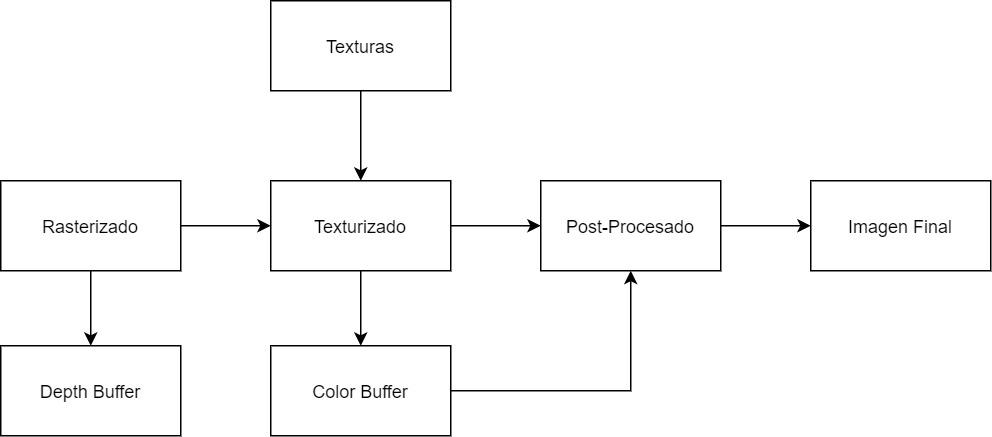
Puisque les puces de mémoire VRAM sont Full Duplex et transmettre à la fois lecture et écriture en même temps, la bande passante est la même dans les deux sens. La partie du pipeline graphique dans laquelle le plus de traitement est effectué est précisément pendant la texturation, c'est donc l'une des premières explications pour lesquelles les GPU nécessitent une grande largeur de marche.
Quant aux données utilisées lors du processus de pré-rastérisation, le calcul de la géométrie de la scène, elles sont suffisamment faibles pour ne pas entraîner une énorme quantité de mémoire utilisée et influencer le type de mémoire utilisé comme VRAM.
Le problème des overdraw

L'algorithme utilisé pour rendre une scène est la rastérisation, également appelée algorithme z-buffer ou algorithme du peintre, qui dans sa forme de base a la structure suivante: pour chaque primitive de la scène, pour chaque pixel couvert par la primitive, marque le pixel le plus proche de l'appareil photo et le stocke dans le z-buffer.
Cela fait que, si plusieurs objets sont dans la même position de l'axe de coordonnées X et Y par rapport à la caméra, mais dans une position différente par rapport à l'axe Z, alors les pixels de chacun d'eux sont dessinés dans l'image finale tampon et terminer à être traité plusieurs fois. Cet effet est appelé overdraw ou overdrawn en raison du fait que le GPU peint et repeint les pixels dans la même position.
Maintenant, certains d'entre vous pensent à juste titre ce qui suit: si le tampon de profondeur est généré avant la texturation, comment se fait-il que les pixels ne soient pas supprimés à ce stade? En fait, il existe des techniques pour cela, mais à ce stade, nous ignorons complètement la couleur de chaque pixel et si un objet est semi-transparent ou non, les GPU ne peuvent donc pas supprimer tous les pixels d'une scène où il n'y a qu'un seul objet. transparent, car sa représentation serait incorrecte.
Tri intermédiaire vs dernier tri
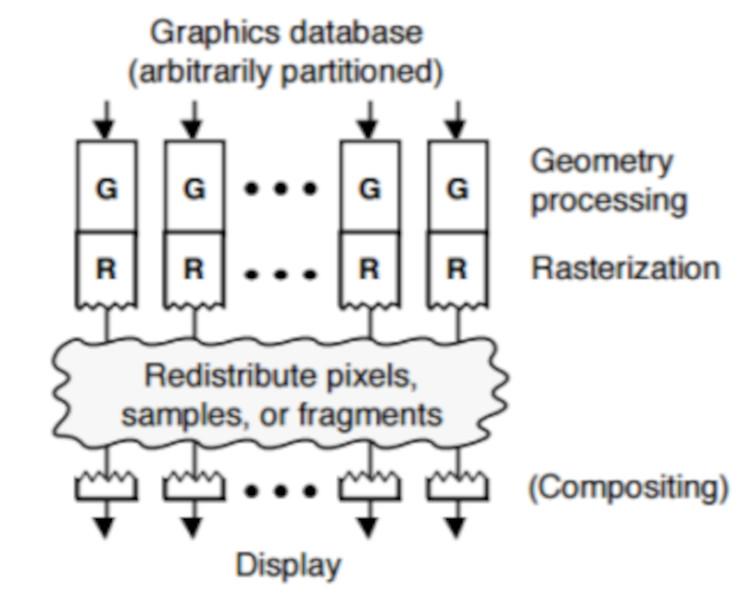
Le processus de vérification des pixels un par un pour voir s'ils sont visibles ou non nécessite des circuits supplémentaires dans les GPU et que le processus de rendu en est affecté. L'idée avec un GPU est celle de la puissance brute sans prendre en compte d'autres éléments, s'il y a une optimisation à faire cela est laissé à la partie matérielle, c'est pourquoi la vérification qu'un pixel doit aller dans le tampon d'image ou il n'est pas fait à la fin du processus, qui est appelé Dernier tri.
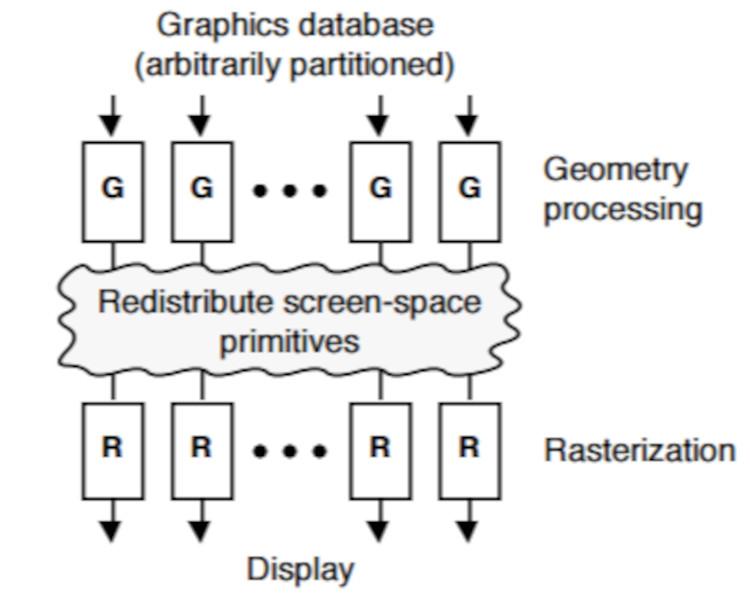
Alors que, si les objets sont triés pendant la phase raster, en utilisant le tampon de profondeur comme référence, nous l'appelons Tri intermédiaire car il se produit en plein milieu du pipeline graphique.
La deuxième technique évite le surdimensionnement, mais comme nous l'avons vu auparavant, il y a des problèmes lorsqu'une scène a de la transparence. Et qu'utilisent les GPU actuels? Eh bien, les deux, puisque les développeurs peuvent choisir le type à choisir. La différence est que dans Middle Sort, il n'y a pas de découvert.
Bande passante et VRAM: l'overdraw
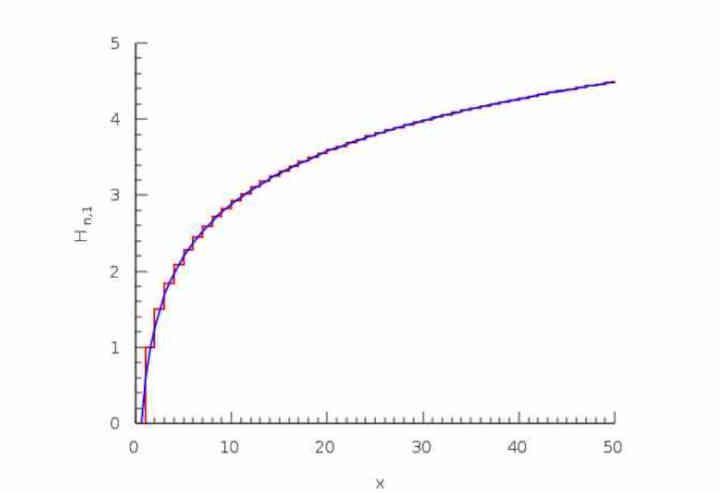
La logique derrière l'overdraw est que le premier pixel dans une position (x, y) sera dessiné dans le tampon d'image oui ou oui, le second sous la même position aura 50% de chances d'avoir une valeur Z supérieure ou 50 % de chance d'avoir un plus petit et donc il sera écrit dans le tampon final, le troisième a 1/3 des possibilités d'exister, le quatrième de 1/4.
C'est ce qu'on appelle la série harmonique:
H (n) = 1 + 1/2 + 1/3 + 1/4… 1 / n
Pourquoi est-ce important? Eh bien, en raison du fait que même si les pixels rejetés par le sur-dessin sont vraiment grands, il atteint le point où un sur-dessin massif ne se traduit pas par un nombre énorme de pixels dessinés dans le tampon de couleur, car si la valeur z de ce pixel déjà texturé est supérieur à celui trouvé dans le tampon d'image, il est donc rejeté et ne compte pas dans la bande passante du tampon de couleur, même s'il a été préalablement texturé.
Bande passante VRAM: mécanismes de compression

Ces dernières années, les soi-disant Delta Color Compression ou DCC sont apparus, nous vous recommandons de chercher l'article que nous avons fait à ce sujet. Ces techniques sont basées sur la compression de la taille du tampon de couleur de manière à ce qu'il occupe beaucoup moins et pour ce faire, ce qu'elles font est d'indiquer au GPU que chaque pixel a une valeur de + n bits, où n est la différence entre le l'image actuelle et la précédente.
Un autre élément est la compression de texture, qui est différente de DCC et qui est utilisée lors de la génération d'un tampon de couleur que nous voulons récupérer plus tard pour effectuer des effets de post-traitement. Le problème est que l'image qui utilise la compression de texture n'est pas comprise par l'unité qui lit l'image finale et l'envoie à l'écran.
Bande passante et VRAM: rendu de tuiles
Dans le rendu en mosaïque, le tampon de couleur et le tampon de profondeur sont traités en interne sur la puce, de sorte que ces bandes passantes ne sont pas prises en compte. Par conséquent, les GPU qui utilisent cette technique, tels que ceux utilisés dans les smartphones, ne nécessitent pas autant de bande passante et peuvent fonctionner avec des mémoires de bande passante beaucoup plus faible.
Cependant, les moteurs de rendu de tuiles ont une série de revers qui les font avoir moins de puissance brute que les GPUS qui n'utilisent pas cette façon de rendre la scène.
Conclusions

Il est difficile de deviner la bande passante utilisée par chacun des jeux, il existe donc des outils tels que NVIDIANSight et MicrosoftLe PIX, qui mesure non seulement le niveau de charge de calcul dans chacune des parties du GPU mais également le débit de la bande passante, permet aux développeurs d'optimiser l'utilisation de la VRAM.
La raison en est que dans le cas de scènes en surimpression, ils ne peuvent pas prédire quelle sera la charge de chacun des pixels dans une image. Pour les architectes de matériel et les ingénieurs en logiciel, il est préférable de ne pas se compliquer la vie et de mettre la VRAM la plus rapide dans les coûts stipulés.
Ce qui est pris en compte, c'est le rapport entre la bande passante et le taux de remplissage théorique, qui consiste à diviser la bande passante par la précision par pixel et à la comparer avec le taux de remplissage théorique du GPU, mais c'est un facteur qui est de moins en moins pris en compte, d'autant plus que les GPU ne dessinent plus les pixels déjà texturés directement dans la VRAM mais les écrivent à la place dans le cache L2 du GPU lui-même, réduisant ainsi l'impact sur la VRAM.
