Le concept SWAR semblera étrange à beaucoup, mais que se passe-t-il si nous vous disons que les unités SIMD de vos CPU, GPU de vos systèmes sont pour la plupart de type SWAR? Ces types d'unités diffèrent des unités SIMD conventionnelles et trouvent leur origine dans les extensions multimédias de la fin des années 90. Quels sont-ils et à quoi servent-ils aujourd'hui?
Les performances d'un processeur peuvent être mesurées de deux manières, d'une part, à quelle vitesse il exécute les instructions en série et que par conséquent elles ne peuvent pas être parallélisées, puisqu'elles n'affectent que des données unitaires. En revanche, celles qui fonctionnent avec plusieurs données et peuvent être parallélisées. La manière traditionnelle de le faire sur les processeurs et les GPU? Les unités SIMD, dont il existe un sous-type très utilisé dans les CPU et les GPU, les unités SWAR.

ALU et leur complexité
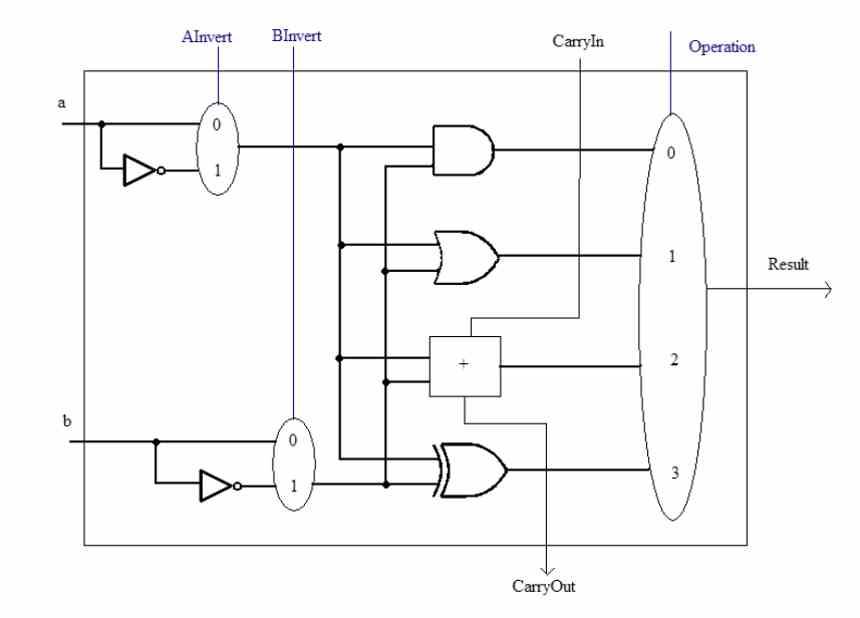
Avant de parler du concept SWAR, nous devons garder à l'esprit que les ALU sont les unités d'un Processeur chargés d'effectuer des calculs arithmétiques et logiques avec les différents nombres. Celles-ci peuvent devenir complexes de deux manières, l'une en raison de la complexité de l'instruction à exécuter. Le circuit interne d'une ALU qui peut effectuer, par exemple, le calcul d'une racine carrée n'est pas le même que celui d'une simple somme.
L'autre est la précision avec laquelle ils travaillent, c'est-à-dire le nombre de bits qu'ils manipulent simultanément à chaque fois. Une ALU peut toujours gérer des données égales ou inférieures au nombre de bits pour lequel elle est conçue. Par exemple, nous ne pouvons pas faire calculer un nombre 32 bits par une ALU 16 bits, mais nous pouvons faire le contraire.
Mais que se passe-t-il lorsque nous avons plusieurs données de moindre précision? Normalement, ils vont fonctionner à la même vitesse que la précision totale, mais il existe un moyen de les accélérer, et c'est le SIMD de sur-registre. Ce qui est également un moyen d'économiser des transistors dans un processeur.
Quel est le concept SWAR?
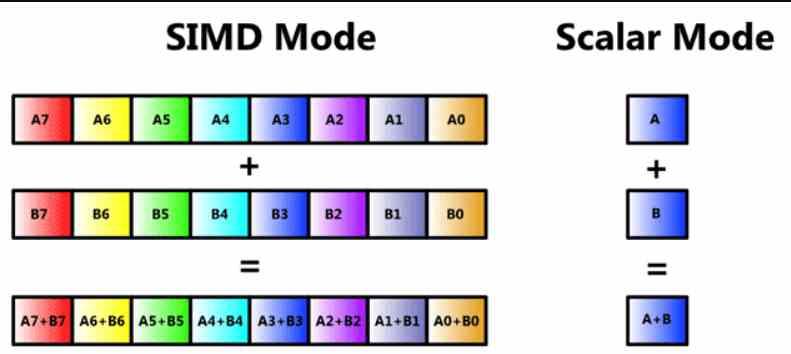
À présent, de nombreux lecteurs sauront qu'il s'agit d'une unité SIMD, mais nous allons l'examiner pour que personne ne perde le fil de cet article depuis le début. Une unité SIMD est un type d'ALU où plusieurs données sont manipulées à travers une seule instruction en même temps, et donc il y a plusieurs ALU qui partagent la partie captive de ce qu'est l'instruction elle-même et de son décodage, mais où dans chacune d'elles est différente une information est traitée.
Les unités SIMD sont généralement constituées de plusieurs ALU, mais il y a des cas où les ALU sont subdivisées en plus simples, ainsi que le registre d'accumulation où elles stockent temporairement leurs données pour les calculer. Cela s'appelle SIMD sur un registre ou par son acronyme en anglais SWAR, ce qui signifie SIMD dans un registre ou SIMD sur un registre.
Ce type d'unité SIMD est très utilisé et permet à une ALU de précision à n bits d'exécuter la même instruction mais en utilisant des données avec moins de précision. Généralement avec une précision d'un demi ou d'un quart. Par exemple, nous pouvons faire en sorte qu'une ALU 64 bits agisse comme deux ALU 32 bits en exécutant ladite instruction en parallèle, ou quatre 16 bits.
Approfondir le concept SWAR?
Ce concept est déjà vieux de plusieurs décennies, mais la première fois qu'ils sont apparus sur PC, c'était à la fin des années 90 avec l'apparition d'unités SIMD dans les différents types de processeurs qui existaient. Les vétérans de l'endroit se souviendront de concepts comme MMX, AMD 3D Now!, SSE et autres étaient des unités SIMD construites selon le concept SWAR.
Supposons que nous voulions construire une unité SIMD de 128 bits
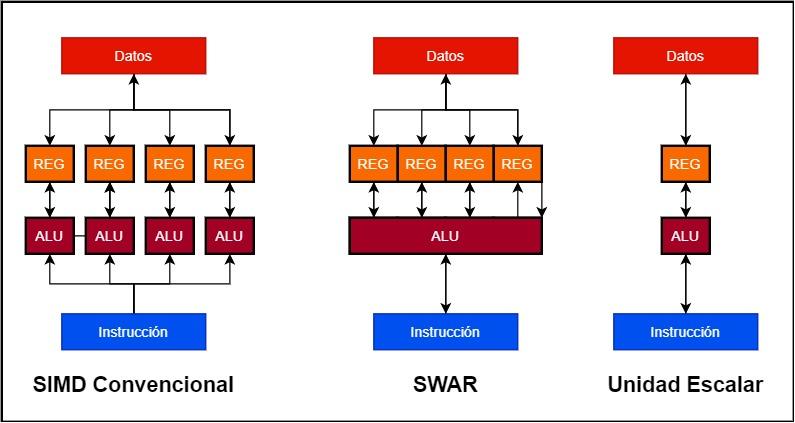
- Dans les unités SIMD conventionnelles, nous avons plusieurs ALU fonctionnant en parallèle et chacune d'elles possède son propre registre ou accumulateur de données. Ainsi, une unité SIMD 128 bits peut être constituée de 4 ALU 32 bits et de 4 registres 32 bits.
- Au lieu de cela, une unité SWAR est une seule ALU qui peut fonctionner avec une très haute précision ainsi que son registre d'accumulateur. Cela nous permet de construire l'unité SIMD en utilisant une seule ALU 128 bits avec prise en charge SWAR.
L'avantage de la mise en œuvre d'une unité de type SWAR par rapport à une unité scalaire est simple à comprendre, si une ALU ne contient pas le mécanisme SWAR qui lui permet de fonctionner comme une unité SIMD avec moins de données de précision, elle les exécutera en même temps. la vitesse. que les données de la plus haute précision. Qu'est-ce que ça veut dire? Une unité 32 bits sans prise en charge SWAR, au cas où elle doit exécuter la même instruction sur des données 16 bits, le fera à la même vitesse qu'une unité 32 bits. En revanche, si l'ALU prend en charge SWAR, il pourra exécuter deux instructions 16 bits dans le même cycle, dans le cas où les deux se succèdent.
SWAR comme patch pour l'IA

Les algorithmes d'intelligence artificielle ont une particularité, ils ont tendance à travailler avec des données de très faible précision et aujourd'hui la plupart des ALU fonctionnent avec une précision de 32 bits. Cela signifie ajouter des ALU de précision 16, 8 et même 4 bits à un processeur pour accélérer ces algorithmes. Ce qui complique le processeur, mais les ingénieurs ne sont pas tombés dans cette erreur et ont commencé à extraire le SIMD du registre d'une manière particulière, en particulier sur les GPU.
Est-il possible de combiner un ALU SIMD conventionnel avec un design SWAR? Eh bien oui, et c'est ce que fait, par exemple, AMD dans ses GPU où chacun des ALU 32 bits qui composent les unités SIMD de ses GPU RDNA prend en charge SIMD sur registre et peut donc être subdivisé en deux 16 bits, 4 de 8 bits ou 8 de 4 bits.
Dans le cas d' NVIDIA, ils ont donné la charge d'accélérer les algorithmes pour l'IA aux Tensor Cores, ce sont des tableaux systoliques composés d'ALU à virgule flottante de 16 bits interconnectés les uns avec les autres dans une matrice à trois axes, d'où le nom de l'unité. Tenseur. Ce ne sont pas des unités SIMD, mais chacune de leurs ALU prend en charge SIMD sur registre en étant capable d'effectuer deux fois plus d'opérations avec une précision de 8 bits et quatre fois avec une précision de 4 bits. Dans tous les cas, les unités Tensor sont importantes car elles sont conçues pour accélérer les opérations de matrice à matrice à une vitesse beaucoup plus élevée qu'avec une unité SIMD.
