Le fait de choisir un processeur avec plus de cœurs souvent ne se traduit pas par une augmentation des performances au même degré lors de l'utilisation de certains programmes. Pourquoi ce phénomène se produit-il et, par conséquent, quelles en sont les causes ? On vous l'explique en détail.
L'une des raisons d'utiliser de nouvelles versions de programmes au fil du temps est qu'elles sont conçues pour mieux tirer parti des processeurs avec un nombre de cœurs plus élevé. N'oublions pas qu'au fil du temps, leur nombre dans les processeurs augmente. Cependant, pourquoi les performances n'augmentent-elles pas dans les programmes au pair ?

Les programmes n'évoluent jamais avec le nombre de cœurs
Il est important de prendre en compte que les programmes qui sont exécutés n'ont pas la capacité de diviser leurs processus ou tâches actifs à un moment donné, en fonction du nombre de threads d'exécution que nous avons dans notre Processeur. Plus que tout en raison du fait que cette division est explicite dans le code du programme, c'est-à-dire qu'elle est le produit de l'habileté du programmeur et de la conception de l'application.
En fait, ce qui est pertinent lors du codage d'un programme n'est pas de l'optimiser pour utiliser le plus grand nombre de cœurs possible, mais plutôt pour la latence. Comprendre ce dernier comme le temps qu'il faut à un processeur pour accomplir une tâche mesurée en unités de temps. Et c'est que la performance d'un CPU consiste à accomplir le plus de tâches en un minimum de temps. Ce qui dépendra d'abord de votre architecture et de votre vitesse d'horloge ensuite.
Cependant, ce qui nous intéresse concernant la latence, c'est de savoir combien de tâches il peut terminer dans une période donnée, c'est-à-dire la charge de travail et cela dépendra de la situation et de la manière dont les programmes ont été écrits. En d'autres termes, les performances ne dépendent pas seulement du matériel, mais aussi de la qualité ou de la médiocrité de l'écriture du logiciel.

Division du travail en plusieurs noyaux
Maintenant, si nous augmentons le nombre de cœurs dans un système, il devient alors possible de diviser le travail en morceaux et de le terminer beaucoup plus facilement. C'est là qu'intervient la formule T/N, où T est le nombre de tâches à effectuer et N est le nombre de threads d'exécution que le système peut exécuter. Évidemment, nous pourrions charger le nombre maximum de travaux sur quelques cœurs et les forcer brutalement à les réparer. Le problème est que cette mesure est contre-productive car elle profite aux CPU les plus modernes, qui ont des performances plus élevées individuellement sur chaque cœur.
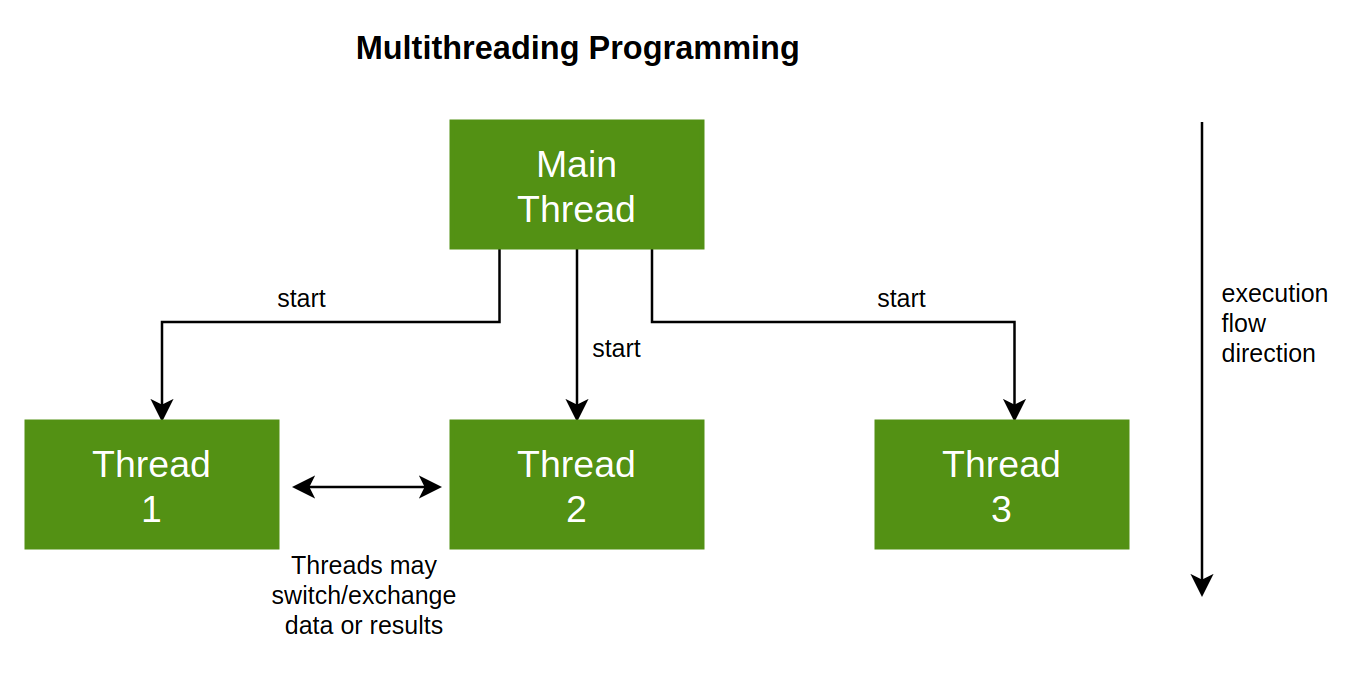
Cependant, répartir le travail entre différents noyaux est un travail supplémentaire qui est généralement confié à un noyau qui agit comme un conducteur et doit effectuer les tâches suivantes :
- Vous devez créer des processus et des listes de tâches et en avoir un bon contrôle à tout moment.
- Ils doivent savoir prédire à tout moment le début et la fin d'une tâche, y compris le temps qu'il faut pour en terminer une et en commencer une autre.
- Les différents noyaux doivent avoir la capacité d'envoyer un signal au noyau principal pour savoir quand un processus démarre et se termine.
Cette solution a été adoptée par SONY, Toshiba et IBM dans le Cell Broadband Engine, le processeur central de la PS3 où un cœur maître se chargeait de diriger le reste. Bien que beaucoup plus ancien, il a été adopté par l'Atari Jaguar. Pour PS4, SONY n'a plus répété ce modèle et personne ne l'a implémenté sur PC car c'est un cauchemar, cependant, c'est le moyen le plus efficace de diviser le travail.
Tout ne peut pas fonctionner sur plusieurs cœurs
Si nous nous demandons si nous pouvons diviser n'importe quelle tâche en sous-tâches à répartir indéfiniment dans un plus grand nombre de cœurs, la réponse est non. Plus précisément, nous devons classer les tâches en trois types différents :
- Ceux qui peuvent être totalement parallélisés et donc répartis entre les différents cœurs dont dispose le processeur central.
- Tâches pouvant être exécutées partiellement en parallèle.
- Parties du code qui ne peuvent pas être exécutées en parallèle.
Dans le premier cas, T/N est appliqué à 100%, dans le second cas, on entre déjà dans la loi dite d'Amdahl où l'accélération due à l'augmentation du nombre de cœurs est partielle et dans le troisième cas on a simplement besoin de tous les puissance d'un seul noyau pour cette tâche,
Ce qui différencie le CPU du GPU en multithreading
Nous arrivons ici à un point différentiel, chaque GPU ou la puce graphique a une unité de contrôle qui est chargée de lire les listes de commandes et de les répartir entre les différents cœurs GPU et même entre les différentes unités. Il s'agit d'une implémentation au niveau matériel du cas précédent et fonctionne parfaitement dans n'importe quelle configuration où vous souhaitez saturer, tant qu'il y a du travail, et donc garder autant de cœurs occupés que possible. Cependant, il faut bien comprendre que le concept de thread d'exécution dans un GPU correspond toujours à une donnée correspondante et sa liste d'instructions. C'est-à-dire un pixel, un sommet ou n'importe quelle donnée.

Ce qui les rend faciles à paralléliser. Autrement dit, si nous voulions faire frire un œuf, le processus dans le processeur serait de faire frire l'œuf, ce qui serait totalement séquentiel. En revanche, dans la puce graphique, une tâche consisterait simplement à chauffer de l'huile ou à ajouter un œuf dans la poêle. Tout cela n'accélérerait pas la cuisson d'un œuf, mais de plusieurs, c'est pourquoi les GPU sont meilleurs pour des tâches telles que le calcul de millions de polygones ou de pixels en même temps, mais pas pour des tâches séquentielles.
