
Si vous avez lu les spécifications complètes de certaines des dernières Intel CPU, vous allez ont vu apparaître de mystérieux acronymes: GNA. En réalité c'est un petit processeur ou plutôt un coprocesseur qui est chargé d'accélérer certains L'apprentissage en profondeur algorithmes et qui, par conséquent, sont fortement liés à la mise en œuvre de l'intelligence artificielle. Nous expliquons en quoi consiste ce coprocesseur et quelles sont ses fonctionnalités.
Des processeurs dédiés à l'accélération de certaines tâches quotidiennes, utilisant des modèles développés via l'intelligence artificielle, ont fait leur apparition ces dernières années dans toutes les configurations et toutes les tailles et il n'est pas étonnant qu'Intel n'ait pas voulu être laissé pour compte.
Qu'est-ce que l'Intel GNA?
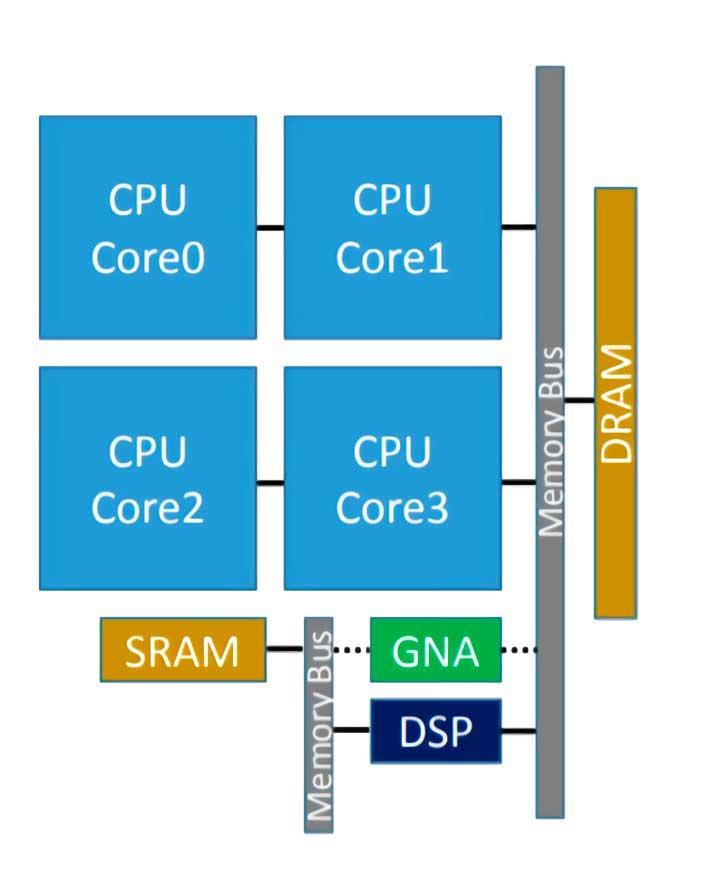
L'Intel GNA est le coprocesseur que certains processeurs Intel ont intégré et qui sert à accélérer l'exécution de certains algorithmes d'inférence. Cela dit, beaucoup d'entre vous savent déjà que nous sommes donc confrontés à un processeur de type neuronal, qui dans ce cas a été introduit pour la première fois dans Intel Ice Lake, et son acronyme signifie Accélérateur neuronal gaussien ( GNA ), et son intégration dans son propre processeur fonctionne à très faible consommation.
Il est destiné à être utilisé pour des tâches telles que la transcription audio en temps réel ou la suppression du bruit photo, qui sont typiques de l'IA, mais ne nécessitent pas d'accélérateur de haute puissance.
Il a été récemment amélioré à Tiger Lake, où la version 2.0 du GNA a été mise en œuvre, qui est également destinée à être utilisée pour annuler le bruit ambiant et réduire le bruit sur les photographies. Avec cela, nous pouvons en déduire que le GNA est conçu pour les environnements d'entreprise collaboratifs, en particulier ceux basés sur le télétravail dans lesquels la transcription de texte et la communication sont effectuées sans bruit d'aucune sorte sont très importants.
Comment cela fonctionne ?
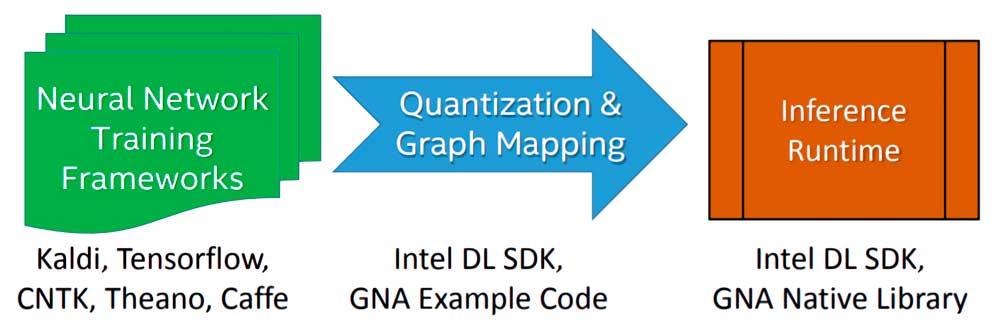
Intel GNA n'est pas une unité d'exécution du Processeur on a donc affaire à un processeur au sein d'un autre et il sert à accélérer certaines tâches pour son invité. Cela signifie qu'il doit être explicitement invoqué dans le code via une API, dans ce cas l'API Intel dédiée.
L'implémentation d'un algorithme ou d'un modèle Deep Learning à exécuter par l'Intel GNA lors de la phase d'inférence se fait en trois étapes:
- Nous commençons par entraîner l'algorithme à l'aide d'un réseau de neurones à virgule flottante avec un cadre de choix libre.
- Le modèle résultant de la formation est importé à l'aide de l'outil de déploiement du SDK Intel Deep Learning qui permet d'importer n'importe quel modèle généré par les frameworks Deep Learning les plus connus et les plus utilisés.
- Il est lié au moteur d'inférence Intel Deep Learning SDK ou aux bibliothèques GNA natives, dont il existe deux: une pour Intel Quark et l'autre pour Intel Atom et Intel Core.
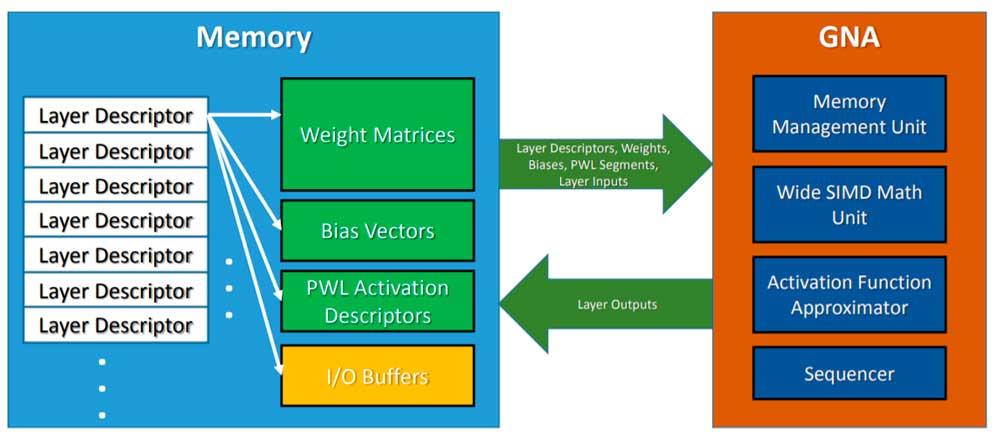
Pour invoquer le GNA, le CPU laisse le modèle d'inférence en mémoire, et le GNA est invoqué pour adopter ledit algorithme et l'exécuter en parallèle au travail du processeur dont il est l'hôte. Il faut également tenir compte du fait qu'il s'agit d'une unité de faible puissance, nous ne pouvons donc pas nous attendre aux mêmes résultats que l'utilisation d'un réseau de neurones haute performance ou d'un FPGA configuré comme tel, mais il est suffisant pour des tâches simples au quotidien .
Intel GNA en dehors des processeurs Intel

Bien que le GNA soit lui-même un processeur intégré dans les processeurs x86, il peut être déployé en dehors du processeur si vous le souhaitez, le cas le plus connu étant le Kit de développement Intel Speech Enabling , qui est utilisé en particulier pour l'inférence des commandes vocales pour les applications pour Alexa d'Amazon dispositifs.
