Die heutige Gesellschaft braucht einen reichlichen Informationsaustausch für die Entwicklung der meisten Aktivitäten oder Arbeitsplätze. Zum Beispiel verteilen Unternehmen, insbesondere multinationale Unternehmen, ihre Projekte auf die vielen Hauptsitze, die sie auf der ganzen Welt haben. Dies bedeutet, dass zwischen den verschiedenen Veranstaltungsorten Kommunikation und Informationsaustausch stattfinden müssen, damit ihre Projekte ordnungsgemäß entwickelt werden können. Ein weiteres Beispiel sind Universitäten, die ein System benötigen, um Informationen mit Studenten auszutauschen, ihnen Notizen, Prüfungen usw. zur Verfügung zu stellen.
Aus diesem Grund entstand um 1996 die erste P2P-Anwendung aus den Händen von Adam Hinkley, Hotline Connect, die ein Werkzeug für Universitäten und Unternehmen zur Verteilung von Dateien sein sollte. Diese Anwendung verwendete eine dezentrale Struktur und es dauerte nicht lange, bis sie veraltet war (da sie von einem einzelnen Server abhing). und da es entworfen wurde für Mac Betriebssystem, es hat nicht viel Interesse bei den Benutzern hervorgerufen.

Bei Napster im Jahr 1999 erregte die Verwendung von P2P-Netzwerken bei den Benutzern Neugier. Dieses Musikaustauschsystem verwendete ein hybrides P2P-Netzwerkmodell, da es neben der Kommunikation zwischen Peers einen zentralen Server zur Organisation dieser Paare enthielt. Ihr Hauptproblem bestand darin, dass der Server Haltepunkte und eine hohe Wahrscheinlichkeit von Engpässen einführte.
Aus diesem Grund entstehen neue Topologien wie die dezentrale, deren Hauptmerkmal darin besteht, dass für die Organisation des Netzwerks kein zentraler Server erforderlich ist. Ein Beispiel für diese Topologie ist Gnutella. Ein anderer Typ sind strukturierte P2P-Netzwerke, die sich eher auf die Organisation von Inhalten als auf die Organisation von Benutzern konzentrieren. Als Beispiel heben wir JXTA hervor. Wir haben auch Netzwerke mit Distributed Hashes Table (DHT) wie Chord.
Als nächstes werden wir die oben genannten Arten von P2P-Netzwerken entwickeln.
Erste P2P-Systeme: ein hybrider Ansatz
Die ersten P2P-Systeme wie Napster oder SETI @ home waren die ersten, die die schwersten Aufgaben von den Servern auf die Computer der Benutzer verlagerten. Mithilfe des Internets, mit dem alle von den Benutzern bereitgestellten Ressourcen kombiniert werden können, gelang es ihnen, diese Systeme zu einer größeren Speicherkapazität und Rechenleistung als Server zu führen. Das Problem war jedoch, dass ohne eine Infrastruktur als Vermittler zwischen den Peer-Entitäten das System zum Chaos werden würde, da jeder Peer am Ende unabhängig agieren würde.
Die Lösung für das Problem der Störung besteht darin, einen zentralen Server einzuführen, der für die Koordination der Paare zuständig ist (die Koordination zwischen Paaren kann von System zu System sehr unterschiedlich sein). Diese Systemtypen werden als Hybridsysteme bezeichnet, da sie das Client-Server-Modell mit dem Modell von P2P-Netzwerken kombinieren. Viele Leute denken, dass dieser Ansatz nicht als echtes P2P-System beschrieben werden sollte, da er eine zentralisierte Komponente (Server) einführt. Trotzdem war und ist dieser Ansatz sehr erfolgreich.
Wenn bei dieser Art von System eine Entität eine Verbindung zum Netzwerk herstellt (mithilfe einer P2P-Anwendung), wird sie auf dem Server registriert, sodass der Server jederzeit die Anzahl der auf diesem Server registrierten Paare kontrolliert hat, sodass sie anbieten können Dienstleistungen für andere Peers. Normalerweise erfolgt die Peer-to-Peer-Kommunikation Punkt-zu-Punkt, da die Peers kein größeres Netzwerk bilden.
Das Hauptproblem bei diesem Entwurf besteht darin, dass ein Systembruchpunkt und eine hohe Wahrscheinlichkeit für das Auftreten eines sogenannten „Engpasses“ eingeführt werden (bei der Datenübertragung, wenn die Verarbeitungskapazität eines Geräts größer ist als die Kapazität, an die das Gerät angeschlossen ist ). Wenn das Netzwerk wächst, wächst auch die Serverlast, und wenn das System das Netzwerk nicht skalieren kann, bricht das Netzwerk zusammen. Und wenn der Server ausfällt, kann sich das Netzwerk nicht selbst neu organisieren.
Trotz allem gibt es immer noch viele Systeme, die dieses Modell verwenden. Dieser Ansatz ist nützlich für Systeme, die Inkonsistenzen nicht tolerieren können und keine großen Ressourcen für Koordinierungsaufgaben benötigen. Hier ist als Beispiel, wie Napster funktioniert. Napster entstand Ende 1999 durch Shawn Fanning und Sean Parke mit der Idee, Musikdateien zwischen Benutzern zu teilen.

Napster funktioniert so, dass Benutzer eine Verbindung zu einem zentralen Server herstellen müssen, der für die Verwaltung einer Liste der verbundenen Benutzer und der diesen Benutzern zur Verfügung stehenden Dateien verantwortlich ist. Wenn ein Benutzer eine Datei erhalten möchte, führt er eine Suche auf dem Server durch und der Server gibt ihm eine Liste aller Paare, die die gesuchte Datei haben. So sucht der Interessent nach dem Benutzer, der am besten liefern kann, was er benötigt (z. B. diejenigen mit der besten Übertragungsrate auswählen), und erhält seine Datei ohne Zwischenhändler direkt von ihm. Napster wurde bald zu einem sehr beliebten System bei den Nutzern und erreichte 26 2001 Millionen Nutzer, was bei Plattenfirmen und Musikern zu Unbehagen führte.
Aus diesem Grund reichten die RIAA (Recording Industry Association of America) und mehrere Plattenfirmen in einem Versuch, es zu beenden, eine Klage gegen das Unternehmen ein, was die Schließung seiner Server verursachte. Dies führte zu einem Netzwerkabsturz, da Benutzer ihre Musikdateien nicht herunterladen konnten. In der Folge wanderte ein großer Teil der Nutzer zu anderen Austauschsystemen wie Gnutella, Kazaa etc.
Später, um 2008, wurde Napster eine MP3-Musikvertriebsfirma mit einer großen Anzahl von Songs zum Herunterladen: free.napster.com.
Unstrukturierte P2P-Netzwerke
Eine andere Möglichkeit, Dateien gemeinsam zu nutzen, ist die Verwendung eines nicht zentralisierten Netzwerks, dh eines Netzwerks, in dem jegliche Art von Vermittler zwischen Benutzern eliminiert wird, sodass das Netzwerk selbst für die Organisation der Kommunikation zwischen Peers verantwortlich ist.
Wenn bei diesem Ansatz ein Benutzer bekannt ist, wird eine "Vereinigung" zwischen ihnen hergestellt, so dass sie ein "Netzwerk" bilden, dem mehrere Benutzer beitreten können. Um eine Datei zu finden, gibt ein Benutzer eine Abfrage aus, die das gesamte Netzwerk überflutet, um die maximale Anzahl von Benutzern zu ermitteln, die über diese Informationen verfügen.
Um beispielsweise eine Suche in Gnutella durchzuführen, sendet der interessierte Benutzer eine Suchanfrage an seine Nachbarn und diese an ihre. Um jedoch zu vermeiden, dass das Netzwerk mit einer kleinen Abfrage zusammenbricht, ist der Broadcast-Horizont auf eine bestimmte Entfernung vom ursprünglichen Host und auch auf die Lebensdauer der Anforderung beschränkt, da sich die Lebensdauer jedes Mal verringert, wenn die Nachricht an einen anderen Benutzer weitergeleitet wird.
Das Hauptproblem bei diesem Modell besteht darin, dass die Abfragenachricht nur wenige Benutzer erreicht, wenn das Netzwerk wächst. Wenn das, wonach wir suchen, etwas Bekanntes ist, wird es sicherlich jeder Wirt in unserem Diffusionshorizont haben, aber wenn das, was wir suchen, etwas ganz Besonderes ist, können wir es möglicherweise nicht finden, weil wir den Diffusionshorizont haben begrenzt, werden wir Hosts ausgelassen haben, die möglicherweise die Informationen enthielten, nach denen wir suchen.
Bis heute wurden reine nicht zentralisierte P2P-Netzwerke durch neue Technologien ersetzt, wie z Superknoten .
SUPERNODOS, eine Hierarchie in unstrukturierten Netzwerken
Die Hauptprobleme bei unstrukturierten Netzwerken waren der Diffusionshorizont und die Größe des Netzwerks. Wir haben zwei mögliche Lösungen: Entweder vergrößern wir den Sendehorizont oder wir verkleinern das Netzwerk. Wenn wir den Broadcast-Horizont vergrößern, erhöhen wir die Anzahl der Hosts, an die die Abfragenachricht exponentiell gesendet werden muss. Dies würde, wie wir bereits gesehen haben, Probleme im Netzwerk verursachen, wie z. B. den Zusammenbruch des Netzwerks. Im Gegenteil, wenn wir die Größe des Netzwerks reduzieren, können die Systeme mithilfe der Superknoten viel besser über das Netzwerk skalieren.
Die Hauptidee dieses Systems besteht darin, dass das Netzwerk zwischen zahlreichen Endknoten und einer kleinen Gruppe von Superknoten aufgeteilt ist, die gut miteinander verbunden sind und mit denen die Endknoten verbunden sind. Um ein Superknoten zu sein, ist es notwendig, anderen Benutzern genügend Ressourcen anbieten zu können, insbesondere Bandbreite. Dieses Netzwerk von Superknoten, zu denen nur wenige gehören können, ist dafür verantwortlich, dass die Größe des Netzwerks klein genug bleibt, um die Effizienz bei der Suche nicht zu verlieren.
Die Funktionsweise ähnelt der des Hybridmodells, da die Endknoten mit den Superknoten verbunden sind, die die Rolle von Servern übernehmen, sodass Benutzer nur mit anderen Benutzern eine Verbindung herstellen, um ausschließlich Downloads durchzuführen. Superknoten speichern Informationen darüber, was jeder Benutzer hat, so dass die Suchzeit verkürzt werden kann, und senden die Informationen an die Endknoten, die das haben, wonach wir suchen.
Diese Art von Struktur wird heute noch häufig verwendet, vor allem, weil sie sehr nützlich ist, um Informationen über beliebte Inhalte auszutauschen oder nach Schlüsselwörtern zu suchen. Da das Netzwerk der Superknoten reduziert wird, skalieren diese Systeme sehr gut über das Netzwerk und bieten keine Haltepunkte wie das Hybridmodell. Andererseits verringern sie die Robustheit gegenüber Angriffen und Netzwerkausfällen und verlieren aufgrund der Replikation über die Superknoten an Genauigkeit bei der Suche nach Ergebnissen. Wenn eine kleine Anzahl von Superknoten ausfällt, wird das Netzwerk in kleine Partitionen unterteilt.
Strukturierte P2P-Netzwerke
Dieser Ansatz wird parallel zu dem oben beschriebenen Superknotenansatz entwickelt. Das Hauptmerkmal ist, dass es sich nicht um die Organisation der Knoten kümmert, sondern um die Organisation von Inhalten, die Gruppierung ähnlicher Inhalte im Netzwerk und die Schaffung einer Infrastruktur, die unter anderem eine effiziente Suche ermöglicht.
Die Peers organisieren untereinander eine neue virtuelle Netzwerkschicht, ein „Overlay-Netzwerk“, das sich über dem grundlegenden P2P-Netzwerk befindet. In diesem Overlay-Netzwerk wird die Nähe zwischen Hosts in Abhängigkeit von den Inhalten angegeben, die sie gemeinsam nutzen: Je mehr Ressourcen sie gemeinsam bereitstellen, desto näher sind sie beieinander. Auf diese Weise garantieren wir, dass die Suche innerhalb eines nicht allzu weit entfernten Horizonts und ohne Reduzierung der Netzwerkgröße effizient durchgeführt wird. Zum Beispiel JXTA, bei dem Peers in einem virtuellen Netzwerk agieren und frei sind, Gruppen von Peers zu bilden und zu verlassen. Daher bleiben Suchnachrichten normalerweise im virtuellen Netzwerk und die Gruppe fungiert als Gruppierungsmechanismus, der Paare mit denselben oder ähnlichen Interessen kombiniert.
Dieser Ansatz bietet eine hohe Leistung und genaue Suche, wenn das virtuelle Netzwerk die Ähnlichkeit zwischen den Knoten in Bezug auf die Suche genau widerspiegelt. Es hat jedoch auch eine Reihe von Nachteilen: Es verursacht hohe Kosten für den Aufbau und die Wartung des virtuellen Netzwerks in Systemen, in denen Hosts sehr schnell ein- und ausgehen. Sie eignen sich nicht sehr für Suchvorgänge mit Booleschen Operatoren, da Knoten benötigt werden, die mit mehr als einem Begriff suchen können.
Eine Unterklasse innerhalb dieses Typs von P2P-Netzwerken sind verteilte Hash-Tabellen.
Verteilte Hash-Tabellen (DHT)
Das Hauptmerkmal von DHTs ist, dass sie das Overlay-Netzwerk nicht nach Inhalt oder Diensten organisieren. Diese Systeme teilen ihren gesamten Arbeitsbereich mithilfe von Kennungen auf, die den Peers zugewiesen werden, die dieses Netzwerk verwenden, sodass sie für einen kleinen Teil des gesamten Arbeitsbereichs verantwortlich sind. Diese Bezeichner können beispielsweise ganze Zahlen im Bereich [0, 2n-1] sein, wobei n eine feste Zahl ist.
Jedes Paar, das an diesem Netzwerk teilnimmt, fungiert als kleine Datenbank (die Menge aller Paare würde eine verteilte Datenbank bilden). Diese Datenbank organisiert Ihre Informationen paarweise (Schlüssel, Wert). Um jedoch zu wissen, welches Paar für das Speichern dieses Paares zuständig ist (Schlüssel, Wert), muss der Schlüssel eine Ganzzahl innerhalb desselben Bereichs sein, mit dem die teilnehmenden Paare des Netzwerks nummeriert sind. Da der Schlüssel möglicherweise nicht in den Ganzzahlen dargestellt wird, benötigen wir eine Funktion, die die Schlüssel in Ganzzahlen innerhalb desselben Bereichs konvertiert, mit dem die Paare nummeriert sind. Diese Funktion ist die Hash-Funktion. Diese Funktion hat die Eigenschaft, dass sie bei unterschiedlichen Eingaben den gleichen Ausgabewert liefern kann, jedoch mit sehr geringer Wahrscheinlichkeit. Aus diesem Grund sprechen wir nicht von einer „verteilten Datenbank“, sondern von der Distributed Hashes Table (DHT), da das, was jedes Paar des Paares (Schlüssel, Wert) tatsächlich speichert, nicht der Schlüssel als solcher ist, sondern der Hash des Schlüssel.
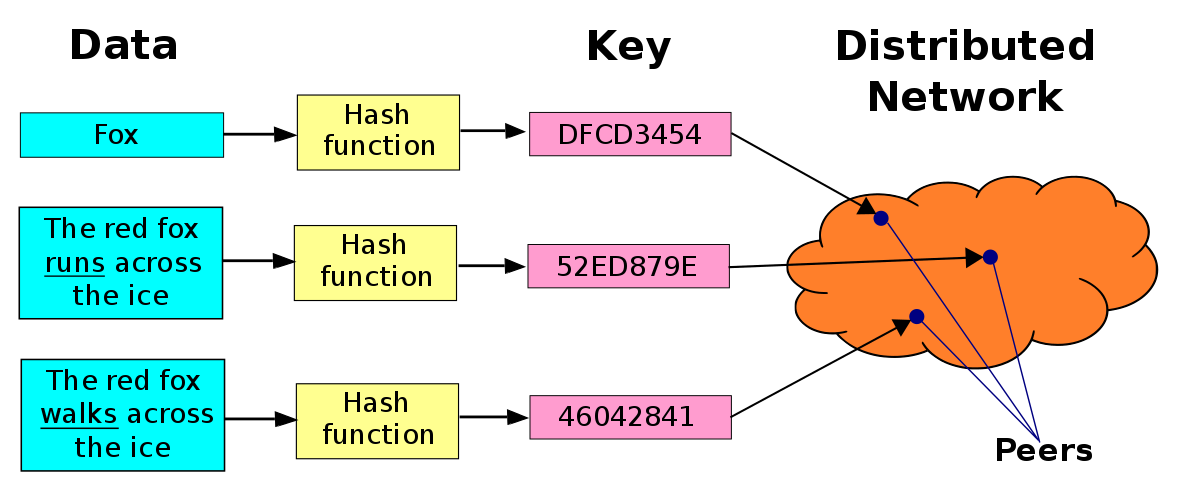
Wir haben bereits besprochen, dass jedes Paar für einen Teil des Netzwerkarbeitsbereichs verantwortlich ist. Aber wie ordnet man das Paar (Schlüssel, Wert) dem richtigen Paar zu? Hierzu wird eine Regel befolgt: Sobald der Hash des Schlüssels berechnet wurde, wird das Paar (Schlüssel, Wert) dem Paar zugewiesen, dessen Kennung dem berechneten Hash am nächsten kommt (der unmittelbare Nachfolger). Für den Fall, dass der berechnete Hash größer als die Bezeichner der Paare ist, wird die Modulo 2n-Konvention verwendet.
Sobald wir ein wenig über die grundlegende Funktionsweise von DHT gesprochen haben, werden wir ein Beispiel für dessen Implementierung über das CHORD-Protokoll sehen.
Verteiltes Suchprotokoll in P2P-Netzwerken: CHORD
Chord ist eines der beliebtesten verteilten Suchprotokolle in P2P-Netzwerken. Dieses Protokoll verwendet die SHA-1-Hash-Funktion, um sowohl den Paaren als auch den gespeicherten Informationen ihre Kennung zuzuweisen. Diese Bezeichner sind in einem Kreis angeordnet (wobei alle Werte modulo 2m angenommen werden), sodass jeder Knoten weiß, wer sein Vorfahr und sein unmittelbarster Nachfolger sind.
Um die Skalierbarkeit des Netzwerks aufrechtzuerhalten, werden beim Verlassen eines Netzwerks durch einen Knoten alle seine Schlüssel an seinen unmittelbaren Nachfolger übergeben, sodass das Netzwerk immer auf dem neuesten Stand gehalten wird, wodurch vermieden wird, dass Suchvorgänge fehlerhaft sind.
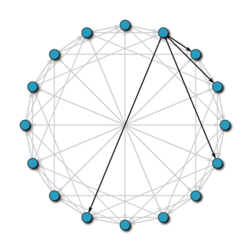
Um die verantwortliche Person zu finden, die einen Schlüssel speichert, senden die Knoten Nachrichten aneinander, bis sie ihn finden. Aufgrund der kreisförmigen Anordnung des Netzwerks kann eine Abfrage im schlimmsten Fall die Hälfte der Knoten abdecken, was die Wartung sehr teuer macht. Um dies zu vermeiden und damit die Kosten zu senken, ist in jedem Knoten eine Routing-Tabelle gespeichert, in der die Adresse der Knoten gespeichert ist, die einen bestimmten Abstand von ihm haben. Auf diese Weise durchsucht der Knoten seine Routing-Tabelle, um festzustellen, ob er die Adresse der für k verantwortlichen Person hat, wenn wir wissen möchten, wer für den Schlüssel k verantwortlich ist. Wenn dies der Fall ist, wird die Anfrage direkt an Sie gesendet. Wenn es nicht vorhanden ist, sendet es die Frage an den nächsten Knoten von k, dessen Kennung kleiner als k ist.
Mit dieser Verbesserung ist es uns gelungen, die Suchkosten von N / 2 auf Protokoll N zu senken, wobei N die Nummer des Netzwerkknotens ist.
Schlussfolgerungen.
Wie wir gesehen haben, gibt es viele Arten von P2P-Netzwerken, jedes mit seinen Stärken und Schwächen. Keiner sticht über dem anderen hervor, sodass beim Programmieren beispielsweise einer P2P-Anwendung mehrere Optionen mit jeweils eigenen Merkmalen verfügbar sind.
Beachten Sie, wie sich die Art und Weise des Informationsaustauschs entwickelt. Ende des letzten Jahrtausends gab es zahlreiche P2P-Netzwerke, und für die meisten Menschen war dies die einzige bekannte Möglichkeit, Informationen auszutauschen. Heute hat sich der Trend geändert. Die Leute ziehen es jetzt vor, Dateien über große Server auszutauschen, wo sie in einigen Fällen Benutzer dafür bezahlen, sie zu hosten.
Einige Fragen, die Ihnen in den Sinn kommen könnten, sind: Was ist die Zukunft von P2P-Netzwerken? Zu welchen Formen der Informationsorganisation haben wir uns entwickelt?
Eine der möglichen Entwicklungen ist der Sprung von P2P zu p4p. Was ist der P4P? Zusammenfassend werden wir sagen, dass P4P, auch als Hybrid-P2P bekannt, eine kleine Weiterentwicklung von P2P ist, deren Hauptmerkmal darin besteht, dass Dienstanbieter, ISPs, eine wesentliche Rolle innerhalb des Netzwerks spielen, da bei der Durchführung einer Suche zuerst gesucht wird unter den teilnehmenden Knoten, die zum gleichen ISP gehören.
