Multi-GPU จากชิปเล็ตอยู่ใกล้แค่เอื้อม และแม้ว่าในตอนแรกเราจะเห็นพวกมันเป็นการ์ด HPC และด้วยเหตุนี้นอกตลาดเกม เรารู้มานานแล้วว่าวิวัฒนาการไปสู่การสร้างกราฟิกการ์ดที่ใช้ Multi-GPU ต่อชิปเล็ต แต่สิ่งที่พวกเขานำมาเปรียบเทียบกับเสาหินทั่วไป GPU? การอ่านเพื่อหา.

สถาปัตยกรรมที่เราพูดถึงในบทความนี้ยังไม่มีวางจำหน่ายในท้องตลาด ยังไม่ได้นำเสนอ แต่เป็นผลิตภัณฑ์จากการวิเคราะห์ความก้าวหน้าที่เกิดขึ้นในช่วงไม่กี่ปีที่ผ่านมา ตลอดจนสิทธิบัตรต่างๆ ของ Multi-GPU Chiplets ที่ทั้ง เอเอ็มดี, NVIDIA และ อินเทล ได้รับการเผยแพร่ในช่วงสองปีที่ผ่านมา นั่นคือเหตุผลที่เราตัดสินใจนำข้อมูลนั้นมาสังเคราะห์ เพื่อให้คุณมีไอเดียว่า GPU ประเภทนี้ทำงานอย่างไร และปัญหาด้านกราฟิกที่จะแก้ไขคืออะไร
การเรนเดอร์ 3D แบบดั้งเดิมด้วย GPU หลายตัว

การใช้การ์ดกราฟิกหลายตัวเพื่อรวมพลังในการเรนเดอร์แต่ละเฟรมในวิดีโอเกม 3 มิติไม่ใช่เรื่องใหม่ เนื่องจาก Voodoo 2 โดย 3dfx เป็นไปได้ที่จะแบ่งงานการเรนเดอร์ทั้งหมดหรือบางส่วนระหว่างการ์ดกราฟิกหลายตัว วิธีทั่วไปในการทำคือ Alternate Frame Rendering โดยที่ ซีพียู ส่งรายการหน้าจอของแต่ละเฟรมสลับกันไปยัง GPU แต่ละตัว ตัวอย่างเช่น GPU 1 จัดการกับเฟรมที่ 1, 3, 5, 7 ในขณะที่ GPU 2 จัดการกับเฟรมที่ 2, 4, 6, 8 เป็นต้น
มีอีกวิธีหนึ่งในการแสดงฉากในแบบ 3 มิติ คือ Split Frame Rendering ซึ่งประกอบด้วย GPU หลายตัวที่เรนเดอร์ฉากเดียวและแบ่งงาน แต่มีความแตกต่างดังต่อไปนี้: GPU เป็น GPU หลักที่อ่านรายการหน้าจอและ จัดการส่วนที่เหลือ ขั้นตอนแรกของไปป์ไลน์ ก่อนการแรสเตอร์ จะดำเนินการเฉพาะใน GPU ตัวแรกเท่านั้น สำหรับ rasterization และขั้นตอนต่อมาจะดำเนินการอย่างเท่าเทียมกันใน GPU แต่ละตัว
Split Frame Rendering ดูเหมือนจะเป็นวิธีที่ยุติธรรมในการกระจายงาน แต่ตอนนี้เราจะมาดูกันว่าวิธีนี้มีปัญหาอะไรบ้างและมีข้อจำกัดอะไรบ้าง
ข้อจำกัดของ Split Frame Rendering และโซลูชันที่เป็นไปได้

GPU แต่ละตัวประกอบด้วยไดรฟ์ DMA 2 ชุด โดยคู่แรกสามารถอ่านหรือเขียนข้อมูลในระบบพร้อมกันได้ แรม ผ่านพอร์ต PCI Express แต่ในการ์ดกราฟิกหลายตัวที่รองรับ Crossfire หรือ SLI มีไดรฟ์ DMA อีกชุดหนึ่งซึ่งอนุญาตให้เข้าถึง VRAM ของกราฟอื่น ๆ แน่นอนที่ความเร็วของพอร์ต PCI Express ซึ่งเป็นคอขวดที่แท้จริง
ตามหลักการแล้ว GPU ทั้งหมดที่ทำงานร่วมกันจะมีหน่วยความจำ VRAM เหมือนกัน แต่ก็ไม่เป็นเช่นนั้น ดังนั้นข้อมูลจึงถูกทำซ้ำหลายครั้งตามจำนวนการ์ดกราฟิกที่เกี่ยวข้องกับการเรนเดอร์ ซึ่งไม่มีประสิทธิภาพอย่างมาก ในการนี้ เราต้องเพิ่มวิธีการทำงานของการ์ดกราฟิกเมื่อเรนเดอร์กราฟิก 3D แบบเรียลไทม์ ซึ่งทำให้การกำหนดค่าที่มีการ์ดกราฟิกหลายตัวไม่สามารถใช้งานได้อีกต่อไป
การแคชไทล์บน Multi-GPU โดย chiplets
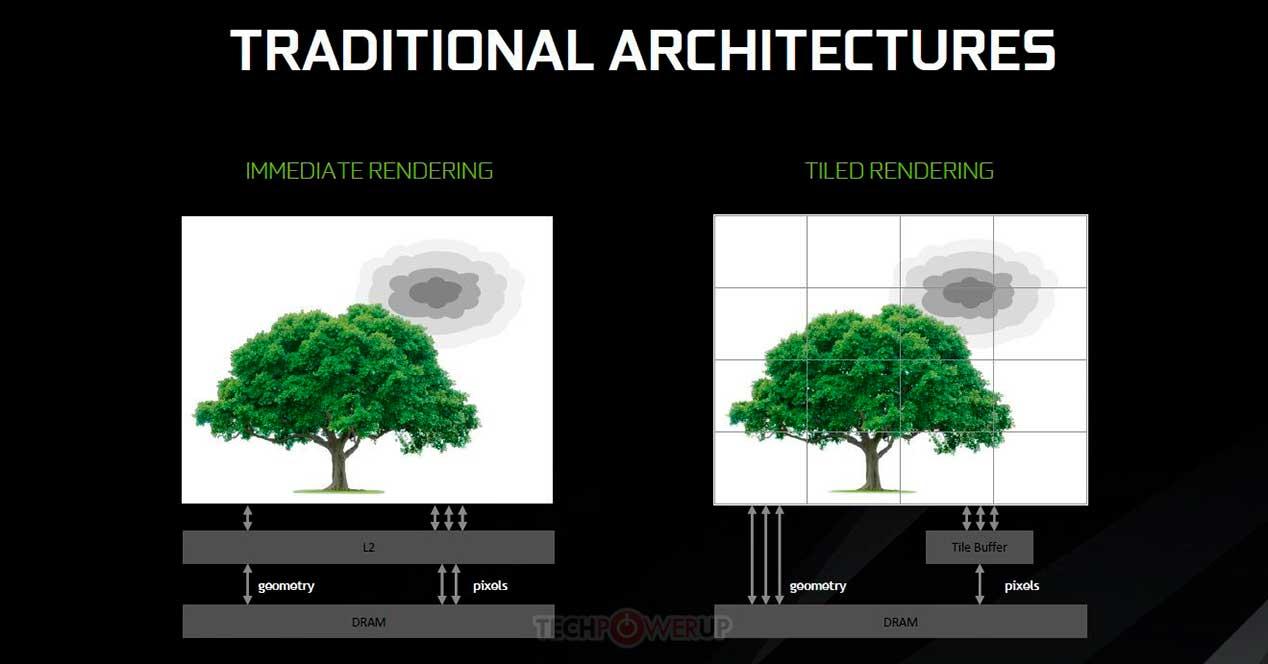
แนวคิด Tile Caching เริ่มใช้จากสถาปัตยกรรม Maxwell ของ NVIDIA และสถาปัตยกรรม Vega ของ AMD เป็นการนำแนวคิดบางอย่างจากการเรนเดอร์โดยไทล์ แต่มีความแตกต่างที่แทนที่จะแสดงแต่ละไทล์ในหน่วยความจำแยกกันและเขียนลงใน VRAM เท่านั้นเมื่อ มันเสร็จสิ้นในแคชระดับที่สอง ข้อดีของสิ่งนี้คือช่วยประหยัดค่าใช้จ่ายด้านพลังงานของการประมวลผลกราฟิกบางอย่าง แต่ข้อเสียคือขึ้นอยู่กับปริมาณแคชระดับบนสุดที่อยู่บน GPU
ปัญหาคือแคชไม่ทำงานเหมือนหน่วยความจำทั่วไป และเมื่อใดก็ตามและหากไม่มีการควบคุมโปรแกรม แคชไลน์ก็สามารถส่งไปยังลำดับชั้นของหน่วยความจำระดับถัดไปได้ จะเกิดอะไรขึ้นหากเราตัดสินใจที่จะใช้ฟังก์ชันเดียวกันกับ GPU ที่ใช้ชิปเล็ต นี่คือที่มาของระดับแคชเพิ่มเติม ภายใต้กระบวนทัศน์ใหม่ แคชระดับสุดท้ายของ GPU แต่ละตัวจะถูกละเว้นเป็นหน่วยความจำสำหรับไทล์แคช และตอนนี้ใช้แคชระดับสุดท้ายของ Multi-GPU ซึ่งจะพบใน ชิปแยกต่างหาก
LCC บน Multi-GPU โดย chiplets
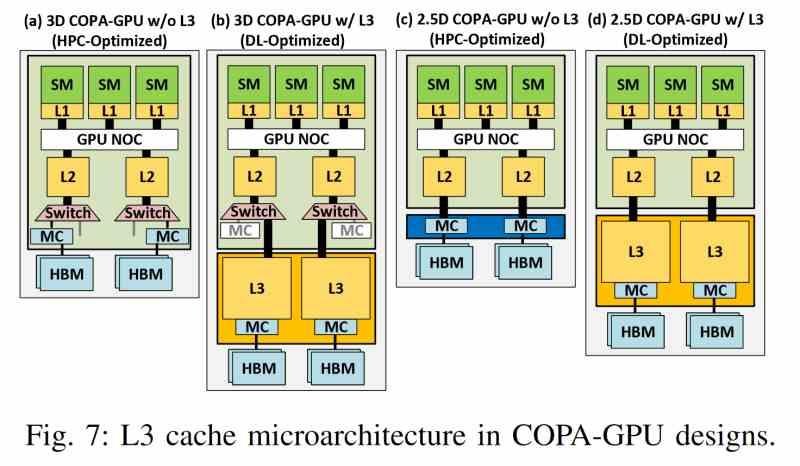
แคชระดับล่าสุดสำหรับ Multi-GPU ที่ใช้ชิปเล็ตเป็นการรวมคุณสมบัติทั่วไปหลายอย่างที่ไม่ขึ้นกับว่าใครเป็นผู้ผลิต ดังนั้นรายการคุณสมบัติต่อไปนี้จึงนำไปใช้กับ GPU ประเภทนี้ โดยไม่คำนึงถึงผู้ผลิต
- ไม่พบใน GPU ใด ๆ แต่อยู่ภายนอกและดังนั้นจึงอยู่ในชิปแยกต่างหาก
- มันใช้อินเตอร์โพเซอร์ที่มีอินเทอร์เฟซความเร็วสูงมาก เช่น ซิลิกอนบริดจ์หรือการเชื่อมต่อระหว่างกัน TSV เพื่อสื่อสารกับแคช L2 ของ GPU แต่ละตัว
- แบนด์วิดธ์สูงที่ต้องใช้ไม่อนุญาตให้มีการเชื่อมต่อระหว่างกัน ดังนั้นจึงเป็นไปได้ในการกำหนดค่า 2.5DIC เท่านั้น
- Chiplet ที่แคชระดับสุดท้ายตั้งอยู่ไม่เพียง แต่เก็บหน่วยความจำดังกล่าว แต่ยังเป็นที่ที่กลไกการเข้าถึง VRAM ทั้งหมดตั้งอยู่ซึ่งด้วยวิธีนี้จะแยกออกจากเอ็นจิ้นการเรนเดอร์
- แบนด์วิดท์ของมันนั้นสูงกว่าหน่วยความจำ HBM มาก ซึ่งเป็นสาเหตุที่ทำให้ใช้เทคโนโลยีการเชื่อมต่อโครงข่าย 3 มิติที่ล้ำหน้ากว่า ซึ่งช่วยให้แบนด์วิดธ์สูงขึ้นมาก
- นอกจากนี้ เช่นเดียวกับแคชระดับสุดท้าย มันสามารถให้ความสอดคล้องกับองค์ประกอบทั้งหมดที่เป็นไคลเอนต์ของมัน
ด้วยแคชนี้ GPU แต่ละตัวจึงถูกป้องกันไม่ให้มี VRAM ของตัวเองได้ดีเพื่อที่จะมีที่ใช้ร่วมกัน ซึ่งช่วยลดความซ้ำซ้อนของข้อมูลได้อย่างมาก และขจัดปัญหาคอขวดที่เกิดจากการสื่อสารใน multi-GPU แบบเดิม
GPU หลักและรอง
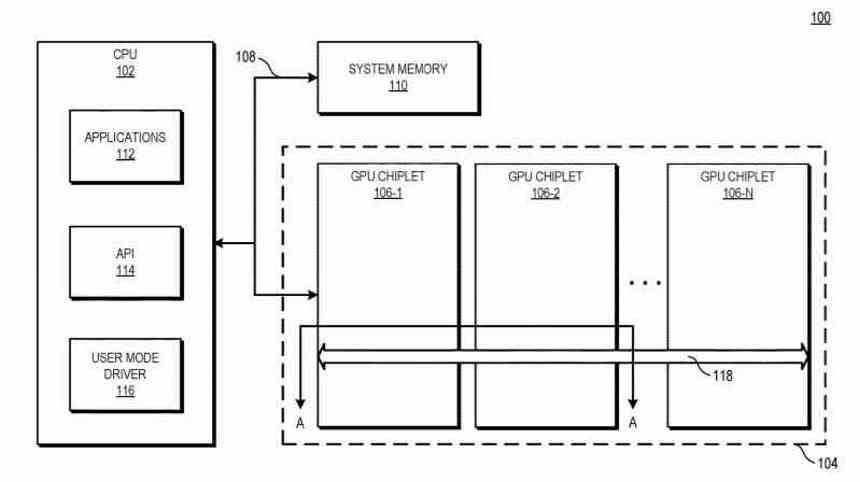
ในกราฟิกการ์ดที่ใช้ Multi-GPU โดยชิปเล็ต การกำหนดค่าเดียวกันยังคงมีอยู่ใน Multi-GPU ทั่วไปเมื่อสร้างรายการแสดงผล เมื่อมีการสร้างรายการเดียวซึ่งได้รับ GPU ตัวแรกที่รับผิดชอบในการจัดการส่วนที่เหลือของ GPU แต่ความแตกต่างใหญ่คือชิปเล็ต LLC ที่เราได้กล่าวถึงในส่วนก่อนหน้านี้ช่วยให้ GPU ตัวแรกสามารถประสานงานและส่งงานไปยัง หน่วยประมวลผล multi-GPU ที่เหลือต่อชิปเล็ต
อีกทางเลือกหนึ่งคือชิปเล็ตทั้งหมดของ Multi-GPU จะขาดตัวประมวลผลคำสั่งอย่างสมบูรณ์ และอยู่ในวงจรเดียวกันกับที่ชิปเล็ต LCC นั้นตั้งอยู่เป็นตัวนำของวงออเคสตรา และใช้ประโยชน์จากโครงสร้างพื้นฐานการสื่อสารที่มีอยู่ทั้งหมดเพื่อส่งคำสั่งที่แตกต่างกัน เธรดไปยังส่วนต่างๆ ของ GPU
ในกรณีที่สองเราจะไม่มี GPU หลักและส่วนที่เหลือเป็นผู้ใต้บังคับบัญชา แต่วงจรรวม 2.5D ทั้งหมดจะเป็น GPU เดียว แต่แทนที่จะเป็นเสาหินจะประกอบด้วยชิปหลายตัว
ความสำคัญของ Ray Tracing

จุดสำคัญที่สุดประการหนึ่งสำหรับอนาคตคือ Ray Tracing ซึ่งในการทำงานต้องใช้ระบบในการสร้างโครงสร้างข้อมูลเชิงพื้นที่บนข้อมูลของวัตถุเพื่อเป็นตัวแทนของการขนส่งแสง แสดงให้เห็นว่าหากโครงสร้างดังกล่าวอยู่ใกล้กับโปรเซสเซอร์ การเร่งความเร็วที่ได้รับผลกระทบจาก Ray Tracing นั้นมีความสำคัญ
แน่นอนว่าโครงสร้างนี้ซับซ้อนและใช้หน่วยความจำมาก นี่คือเหตุผลที่การมีแคช LLC ขนาดใหญ่จึงมีความสำคัญอย่างยิ่งในอนาคต และนี่คือเหตุผลที่แคช LLC จะอยู่ในชิปเล็ตแยกต่างหาก เพื่อให้มีความจุสูงสุดและทำให้โครงสร้างข้อมูลนั้นใกล้เคียงกับ GPU มากที่สุด
ทุกวันนี้ความช้าใน Ray Tracing ส่วนใหญ่เกิดจากข้อเท็จจริงที่ว่าข้อมูลส่วนใหญ่อยู่ใน VRAM และมีเวลาแฝงมหาศาลในการเข้าถึง โปรดทราบว่าแคช LLC ใน Multi-GPU จะมีข้อดีไม่เพียงแต่ในแบนด์วิดท์ แต่ยังอยู่ในเวลาแฝงของแคชด้วย นอกจากนี้ ขนาดที่ใหญ่และเทคนิคการบีบอัดข้อมูลที่กำลังพัฒนาขึ้นในห้องปฏิบัติการของ Intel, AMD และ NVIDIA จะทำให้โครงสร้าง BVH ใช้สำหรับเร่งความเร็วเพื่อเก็บไว้ในหน่วยความจำ "ภายใน" ของ GPU