Although the BIG Navi with RDNA2 architecture and its Navi 2x chips have not yet come onto the market as such, the truth is that AMD (and to a lesser extent NVIDIA) are already working on implementing the successor of this (which will not be HBM2E ): HBM3 . Although we do not know too much about it today, a series of comparative data has been leaked against HBM2 that is quite interesting and can tip the balance of performance between the two companies, how much is the improvement?
As we know, HBM2 and HBM2E are two types of VRAM with a number of important limitations to its implementation and development for GPU chips. They have many advantages from the point of view of performance and consumption, they are the present out of necessity, but they will not be the future as such.
For this, HBM3 arrives, which within the little we know about it, will end the problems of its two previous versions. Until today, we did not know its performance, and above all, how much improvement we can talk about compared to the version it replaces.

HBM2 vs HBM3: the first comparatives and performance simulations arrive
As we say, the first data is already here, except that, as usually happens in these cases, they are not offered by way of bandwidth, FPS or any other common metric within the gaming sector.
As a high-performance TOP memory, the business world is interested in learning about improvements over HBM2 in an Exascale server environment, which are ultimately the world dominators for their tremendous power. Therefore, the data we are going to see reflects this situation and focuses on drawing conclusions for organization, bandwidth, latency, capacity, and power.
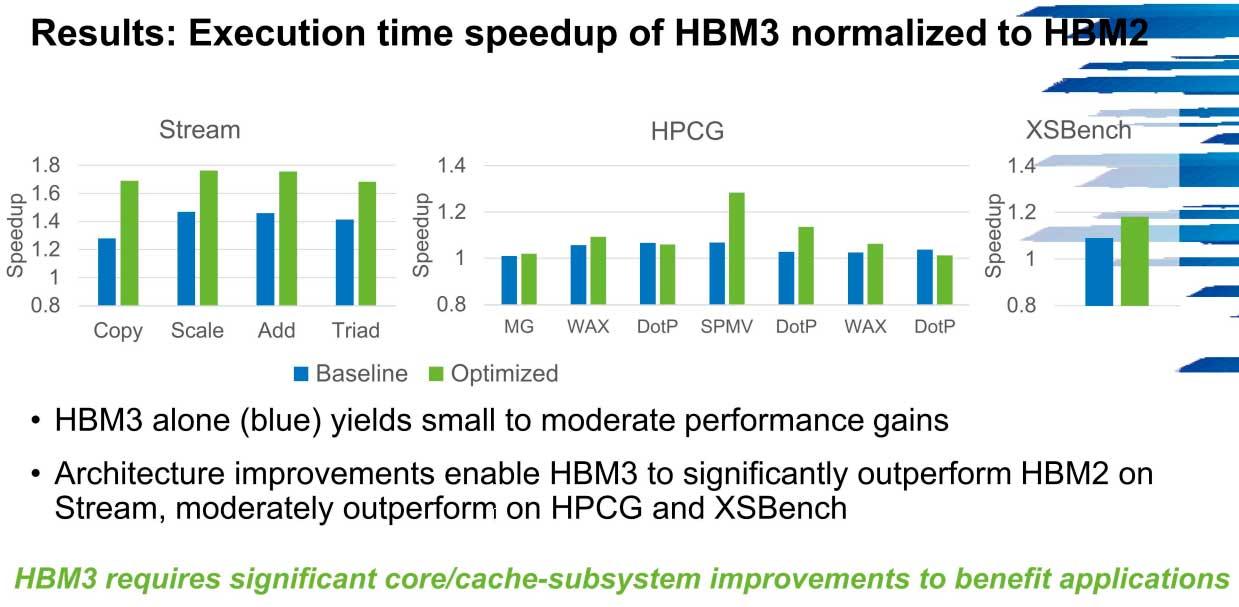
The question is clear and key: to what extent will future PCs benefit from HBM3 vs. HBM2? The data is pretty clear.
As we can see, the optimization of the HBM3 is going to be a more than important pillar in Exascale systems, and that is that it is possible to achieve up to a 1.7x increase in speed in systems over HBM2 with little more than the number of cores and subsystem caches measure up.
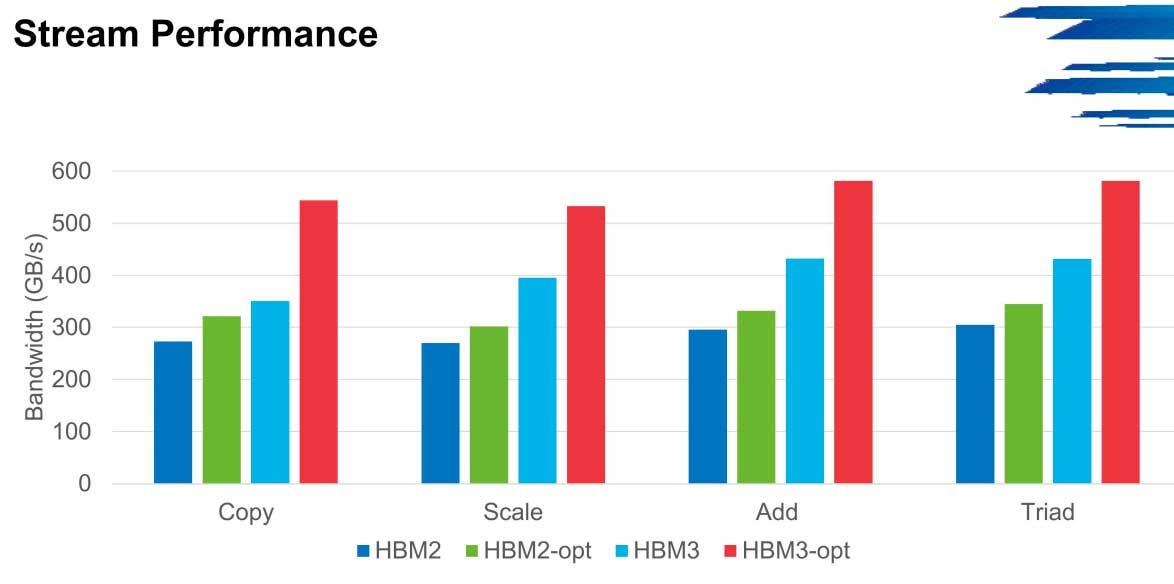
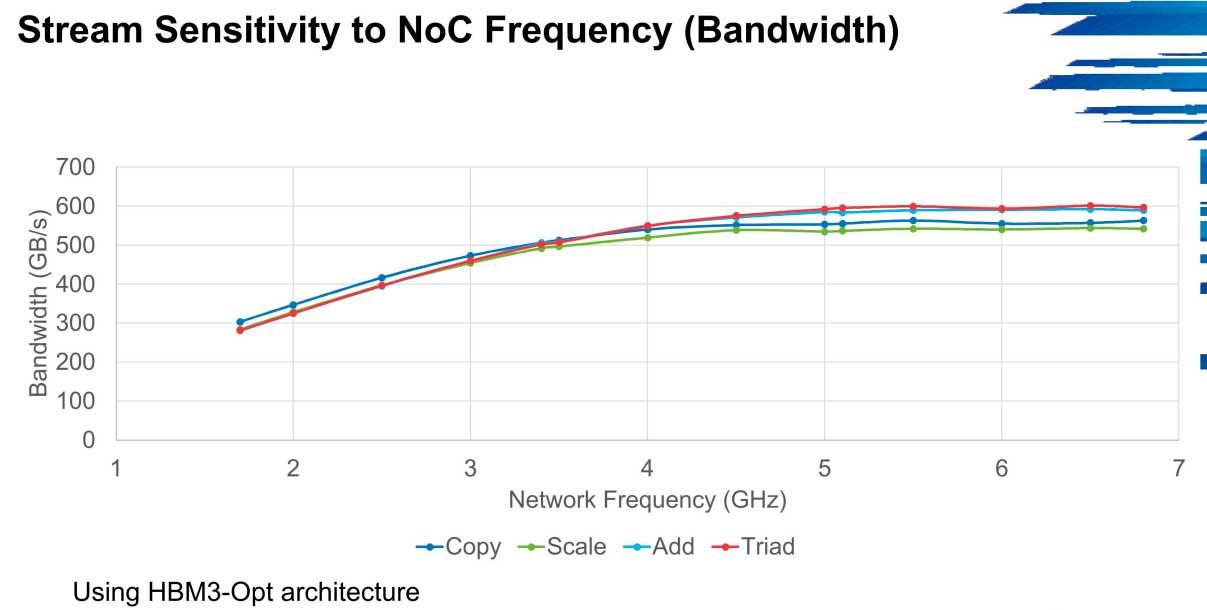
In HPCG the performance in bandwidth can shoot up to 600 GB / s in these environments from the 300 GB / s from which the first versions start at low speeds, a scenario that is repeated in Stream for example.
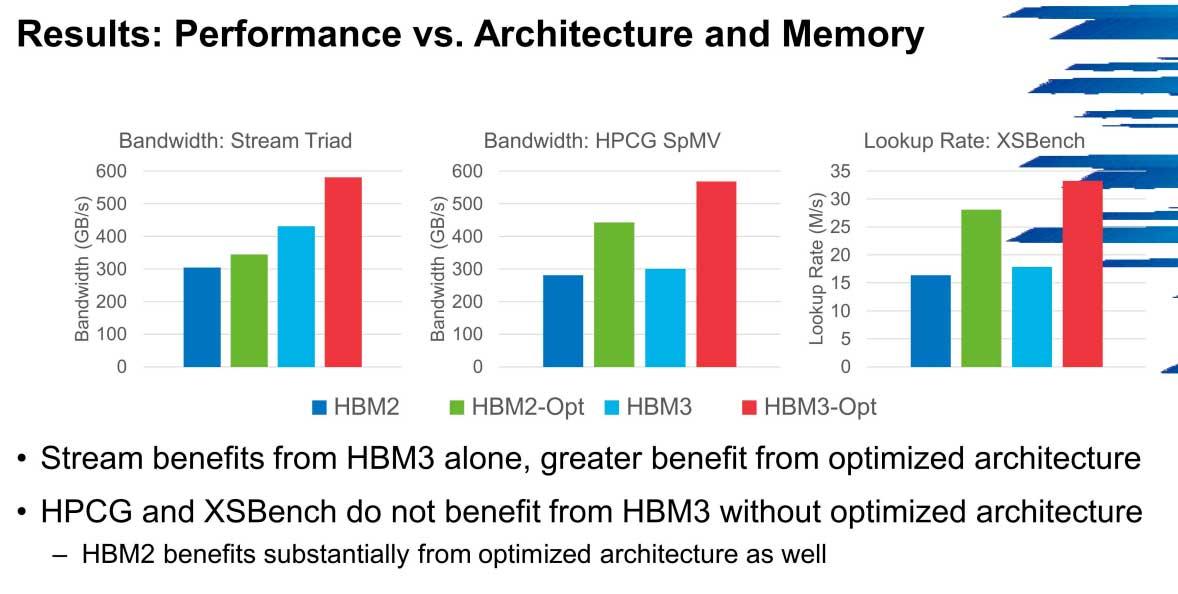
The main problem that HBM3 is going to drag is precisely the NoC networks, in which the bandwidth is a bottleneck. The clusters will have a slight improvement in these cases as long as there is no such bottleneck, but it is not a type of memory that seems to be too optimal for systems that are not precisely optimized.
The number of threads, types and sizes of cache as well as directories are key
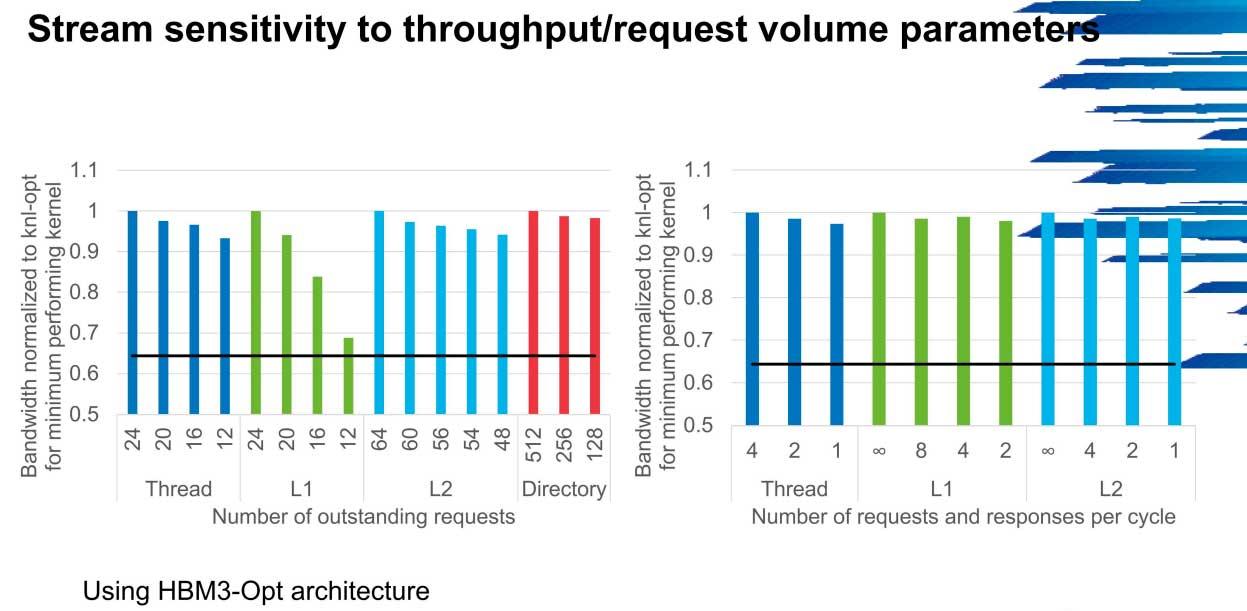
The frequency and number of cores also have a lot to say, since the increase in bandwidth goes from 1 to 2 GHz in 300 GB / s to 600 GB / s if the network frequency is 5 GHz, something that right now is out of reach of almost all servers in the world.
The most realistic scenario is a 4 GHz frequency, where there is a slight drop in operational bandwidth, especially in scale and copy, but it is acceptable considering the current power.
The number of threads, size of L1 and L2 caches, as well as the number of directories are also essential, especially in L1 cache. Scalability is almost 80% when going from 12 to 24, something that is not reflected in the other parameters but indicates the importance that future architectures will have at this point, something that AMD has been working on for some time and that Intel took itself seriously just over a year ago.
In short, HBM3 for servers is tremendously dependent on NoC resources, a maximum optimization will be needed to take full advantage of it in terms of bandwidth (much more when they increase their final speed in the JEDEC) and ultimately it is a type memory highly dependent on scalability and resources.
In gaming it will again be a very expensive memory with zero benefits, where it has already been on multiple occasions that does not provide any benefit at high resolutions and hertz. It will, however, surely be used by AMD in its high-end GPU when consumptions skyrocket and GDDR6 is not an option due to its voltage, where we only have the hope that RDNA 2 will be more efficient and thus avoid its implementation and costs on Lisa Su’s equipment.
On the other hand, NVIDIA has no overtones of use out of your GPU Tesla and will focus on the GDDR6 memories 18 Gbps to increase bandwidth while maintaining the overall consumption of their cards, especially taking advantage of new nodes 7 nm and 8 nm from TSMC and Samsung.