
The technology known as X3D is one of the most important for AMD for the future if not the most important, since it is with which the different elements of its processors will communicate with each other. Its importance lies in the fact that it is going to replace the Infinity Fabric technology and although it is still on a horizon that seems far away, every day we have it closer.
Facing the development of the Exascale Heterogenous Processor, which has been key for AMD to win the El Capitan construction contract, they have had to create a new type of interface so that communication between the CPU and the GPU can be done in a environment where both share the same memory well, this has forced AMD to develop a new type of communication interface, which comes to solve a problem that until now AMD had not been able to solve.
Why haven’t we seen a chiplet-based GPU yet?

The reason we haven’t seen dedicated GPUs in an MCM that shares memory access with the CPU is because the bandwidth provided by the IOD is not large enough to power a GPU. In the case of an MCM with the unified memory system we are talking about applying the Infinity Cache of the GPU as L4 of the system.
Why is the Infinity Fabric not enough? Well, due to the fact that it gives us an interface of 32 or 64 bytes / cycle depending on the version
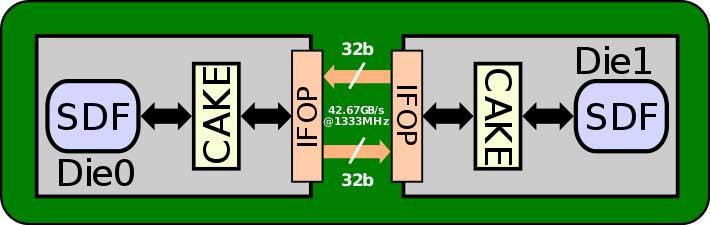
Now imagine that we want to connect a Navi 21 (RX 6800, RX 6800 XT and RX 6900 XT), we must bear in mind that between the L2 cache inside the GPU and the Infinity Cache we have 16 partitions of L2 Cache with a bandwidth 64 bytes / cycle each, this is about 1024 bytes / cycle in total and therefore an 8192-bit interface, which forces AMD engineers to develop a communication interface much more complex than the Infinity Fabric in order to be able to communicate a GPU using the same memory pool.
The problem with the Infinity Fabric when it comes to externally communicating several chips with each other is that being a horizontal 2D connection it has a limited number of pins that we can place without greatly increasing the perimeter of the chip. The other option if we want to increase the bandwidth is to increase the clock speed of each of the pins, but this would greatly increase energy consumption, which would cause it to go out of budget.
X3D, the replacement to the Infinity Fabric
 The problem with the Infinity Fabric is that it does not serve to communicate the chips vertically , so it does not take advantage of the excellent relationship between bandwidth and energy consumption of the vertical interfaces that use the paths through silicon and it is with this problem on top of the table with which AMD has finished developing for the future the complete replacement of the Infinity Fabric.
The problem with the Infinity Fabric is that it does not serve to communicate the chips vertically , so it does not take advantage of the excellent relationship between bandwidth and energy consumption of the vertical interfaces that use the paths through silicon and it is with this problem on top of the table with which AMD has finished developing for the future the complete replacement of the Infinity Fabric.
When AMD announced the X3D, many thought that it was a type of packaging, it really is not like that, but rather it would be a new type of interconnection such as the Infinity Fabric , only that it would work vertically on an interposer, in a configuration very similar to that used in chips accompanied by HBM memory.
The idea is to have a communication interface with an energy consumption close to 0.2 pJ / bit, which allows a bandwidth ten times higher under the same energy consumption as the Infinity Fabric.
Actually AMD is lagging compared to Intel
 The technology that AMD is developing is a response to Intel Foveros, where Intel has already managed to develop a type of interconnection of the same type under a consumption of 0.15 pJ / bit , so it can be said that Lisa Su’s are lagging behind and Like Intel, they are aware that the chips of the future depend on the use of new types of interconnections, which are making the design of the different processors result in a paradigm shift.
The technology that AMD is developing is a response to Intel Foveros, where Intel has already managed to develop a type of interconnection of the same type under a consumption of 0.15 pJ / bit , so it can be said that Lisa Su’s are lagging behind and Like Intel, they are aware that the chips of the future depend on the use of new types of interconnections, which are making the design of the different processors result in a paradigm shift.
But, the reason behind these technologies is in the development of supercomputers with the ability to reach the rate of 1 ExaFLOPS , which is easy from the point of view of executing the instructions, but almost impossible if we talk about the energy cost of the memory. For this we have to introduce a concept which is that of arithmetic intensity .
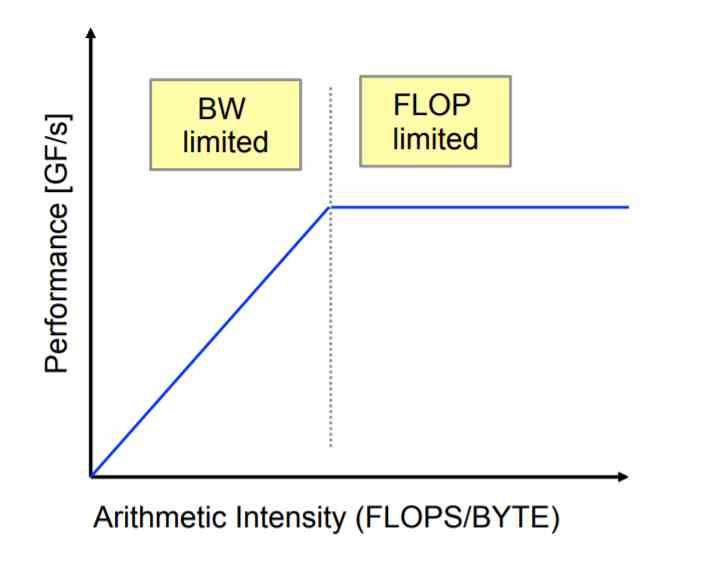
The idea is that an architecture can be as limited by the number of operations it performs as by the bandwidth required by those operations . Of course, if we greatly increase the processing capacity then we also have to do it with the memory. But is the memory we have adequate enough to scale in processing?
The evolution of RAM has been very monotonous, every x time a new manufacturing node appears, which allows reducing energy consumption in data transfer, but the speed at which RAM evolves is not fast enough to do facing the challenges that processor manufacturers such as Intel and AMD face, leading them to fix the problem themselves.
The need for a new kind of RAM
 We have been waiting for the HBM Next Gen or HBM3 for a long time , its specification has been frozen for a long time and the reason for this is that each of the major processor manufacturers (AMD, Intel and NVIDIA) are developing their own “HBM3” memory . In the case of AMD, they would be basing the development of this type of memory on the creation of a 3D DRAM with a communication interface based on the X3D interface, which they will apply for the first time in the El Capitan supercomputer.
We have been waiting for the HBM Next Gen or HBM3 for a long time , its specification has been frozen for a long time and the reason for this is that each of the major processor manufacturers (AMD, Intel and NVIDIA) are developing their own “HBM3” memory . In the case of AMD, they would be basing the development of this type of memory on the creation of a 3D DRAM with a communication interface based on the X3D interface, which they will apply for the first time in the El Capitan supercomputer.
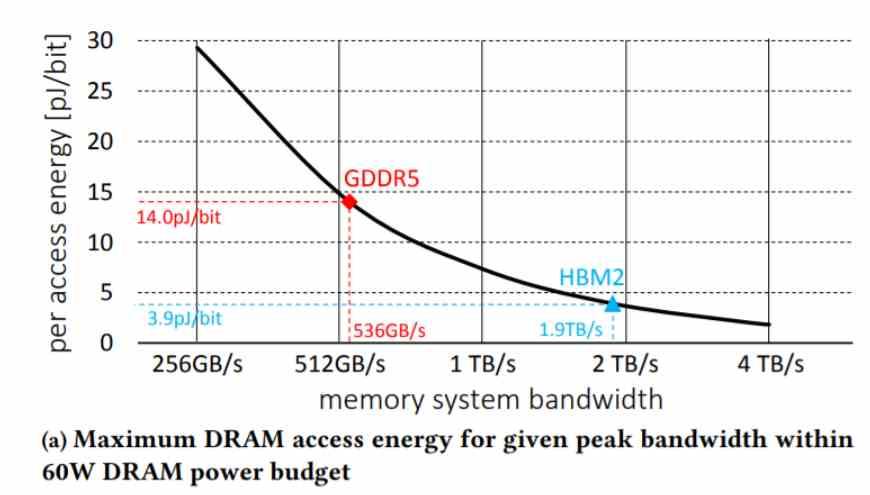
The problem is that every system has a bandwidth limited by the energy consumption assigned to the system, and no matter how much we increase the bandwidth, we reach the point where we cannot increase it more due to the fact that the energy consumption of the memory is too high, hence memories with a lower and lower pJ / bit number are continually being developed.
But what is it that consumes the most energy? The communication interfaces that are used to move the data, the idea is to reach a figure of pJ / bit low enough not only to communicate the GPU chiplets without problems but also to be able to create memories with high bandwidth without increasing considerably consumption.
X3D DRAM memory?

If you’ve seen AMD’s packaging roadmap, you might think from the outset that the memory stacked in the X3D concept is a type of HBM memory, but it really isn’t.
It is a type of memory created as a replacement to the current HBM2e that AMD has developed internally in the development of the EHP for the creation of the “El Capitan” supercomputer. The peculiarities of this type of memory? We know very little, but the little we do know is the following:
- It uses the X3D interface to communicate externally, this saves AMD having to add conversion parts from one interface type to another.
- AMD would be experimenting with the use of cooling systems such as peltier cells on top of this memory, in order to achieve higher clock speeds.
- AMD is considering the inclusion of accelerators or coprocessors in the logic of this type of memory.
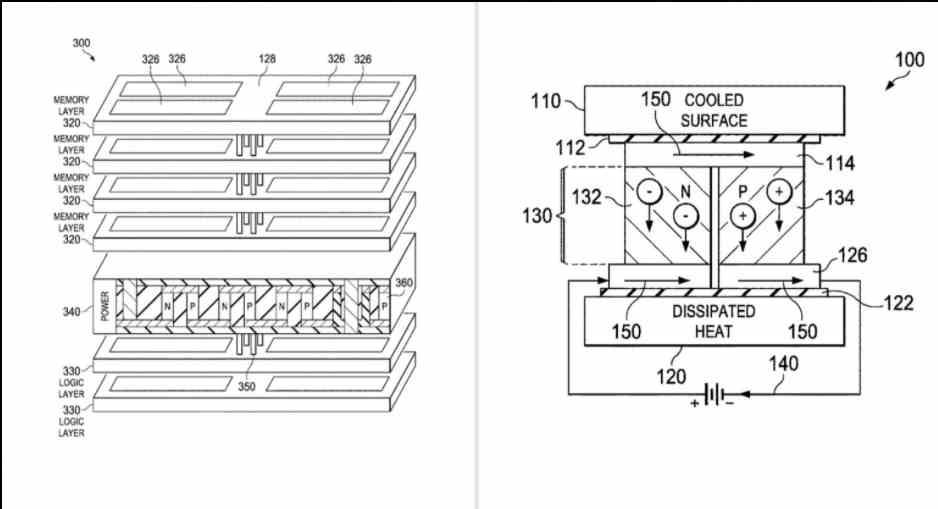
We do not know if AMD is going to sell this in the home market in the future, but we will most likely see a reduced version of this technology. Will we see AMD brand MCMs in which CPU + Memory + GPU + Accelerators are part of a whole? Who knows, but there is no doubt that AMD will make use of this technology also at the domestic level, for the creation of new chips.
Are we finally going to see high-end CPUs and GPUs working together in an MCM? Very likely, as that is what AMD is aiming for.