OCR technology has been around for a long time and has been key to facilitating the work of many people since it is the ability to convert the characters that are an integral part of an image into characters that can be manipulated, which avoids the tedious task of transcribing the text . But what is behind it all?
OCR is used around the clock today and not only to digitize texts but also for things like real-time translations of text written in other languages, and we can even convert our handwritten text into printed text.

OCR and pattern recognition
We understand as a pattern a model that serves to get something else like it; While our eyes and brain identify what each letter is through its spelling, a computer does not have that capacity for abstraction and needs to be able to make a comparison, which is always the result of a subtraction between two elements: if the subtraction gives 0 so this means that the comparison is positive.
In 1960, Lawrence (Larry) Roberts, an MIT researcher who, paradoxically, later became one of the inventors of what would eventually become the Internet, created a character recognition system and an associated typeface, designed to be able to digitize bank checks and so on. sensitive information that needed to be stored by early computers. This source was called OCR-A.

If we think about it, for a computer a letter like any other type of data is nothing more than a set of bits, so all we need is to have it stored in the system in charge of comparing what the font is in its different sizes as a comparative font.
Character recognition via OCR
The first thing the OCR system will do is read the document to locate the text and eliminate, for later analysis, anything that is not useful for optical character recognition.
Once you have only the characters, what you will do is go through what is left of the image taking blocks of it and digitize them for a later comparison with the information in memory. In other words, what the character detection system does is traverse the image by reading it in blocks of a regular number of pixels and making continuous comparisons with the shapes it has stored in its memory.

If it finds a match, what it will do is mark it in a file that it will then show and / or store as a conclusion; said file will be a text file with the text itself extracted through the recognition process.
This means that our character recognition system must have in memory the font in which the text has been written on paper or in the image from which we want to extract it as long as it can make the comparison. But what happens in special cases like handwriting or special fonts?
Curling the curl, beyond OCR
Going back to how our brain works, it identifies things because it has learned a pattern that allows it to identify them. Our brain knows perfectly well through a learned pattern that all the letters in the following image are the letter A.

But a computer, in general, does not know it directly and needs the reference system that we have commented above to know if the comparison is positive or not, which has led that, when reading the handwriting -which is different for each person- has had to go through a long effort of several years.
As a historical curiosity, when Apple launched what could be considered the world’s first “handheld” computer, the Apple Newton, they promised that it would have a handwriting recognition system that would convert user-typed texts to print in time. real.

The result? A disaster, as I did not recognize the way most people write and the device was a complete failure.
The reason for this was not that the Newton and later systems were bad but because a lot of computing power was required to perform pattern recognition, which was not available and has not been available for a long time. Even handwriting recognition systems support huge data and processing centers with which they communicate over the Internet.
Artificial intelligence to the rescue of character recognition
Artificial intelligence systems are actually systems trained to recognize specific patterns and can be trained to learn to recognize characters, not from a comparative element but through applying patterns. For example, we can identify the letter A with a simple pattern like the following:
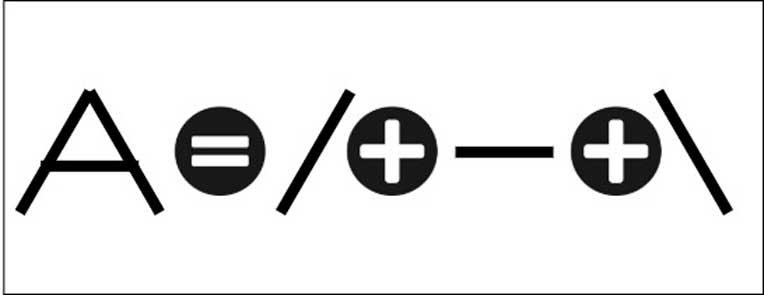
But the idea is to train the machine so that it knows how to recognize the pattern without having to do the comparison and it is at this point where artificial intelligence comes in. In the same way that we can train an artificial intelligence to recognize traffic signs so that it can drive in automatic mode, we can also teach it to learn to identify characters. How? Well, through a neural network that has been previously trained for it.
The most widely used in these cases are the so-called convolutional neural networks, which are a type of artificial neuron that has a similar structure to the neurons of the primary visual cortex of a biological brain and are excellent for the classification and segmentation of images and other applications of computer vision.
What these neural networks do is copy the functioning of the biological systems in charge of detecting the patterns that allow us to identify what each letter is.
At the same time, each time an identification is positive and confirmed several times, that example is saved in the database to be used as a pattern later. In fact, the systems in that case work first if there is a correspondence in the database that has been created and only when it does not find it is when the mechanisms for identifying patterns via artificial intelligence are activated.