Chiplet-based GPUs have been around for a long time, especially since one of the problems both NVIDIA and AMD have faced in recent years is scaling their GPUs beyond physical limits. . What will they be like and what is the motivation for this new way of designing GPUs?
If we make an observation of the GPUs launched in recent times both by AMD, but especially by NVIDIA, we can see that the area they occupy is increasing and if a few years ago a GPU of more than 400 mm2 was seen as something large, now we have them above 600 mm2.

This tendency means that there is a danger that the limit of the grid is reached at a certain moment, said limit is the limit area that a chip can have in a given manufacturing node and in a dangerous way, and things get complicated if we indiscriminately increase the number of cores that make up a GPU.
The simile of stations and trains

Suppose we have a railway network with several train stations, each of them is a processor and the trains are the data packets that are sent.
Obviously, if our railway network includes an increasing number of stations, then we will need more and more tracks and a more complex infrastructure. Well, in the case of a processor it is the same since increasing the number of elements means increasing the number of communication channels between the different elements.
The problem is that these additional train tracks are also going to increase energy consumption, so whoever is dedicated to designing the railway network not only has to take into account how many tracks can be placed in the infrastructure but also the energy consumption of the same.
Moore’s Law doesn’t scale as much as you think
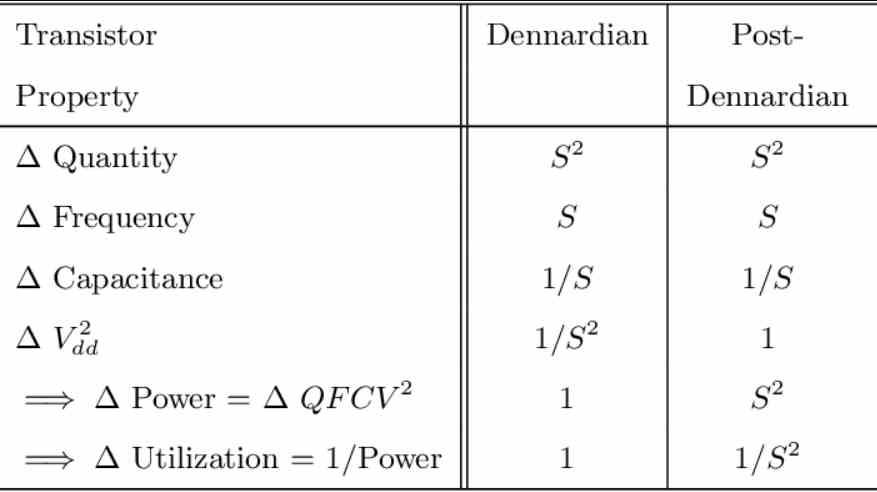
According to Moore’s Law, the density in number of transistors per area doubled every x time on a regular basis, this was accompanied by the Dennard scale, which told us what clock speed they can scale with each new manufacturing node. The original Dennard scale changed its metric from the 65 nm node onwards.
The problem comes when we increase the number of elements / trains and communication routes, we can place twice as many elements but what we cannot do is make sure we have the necessary bandwidth to communicate all those elements at the same time under the same consumption. given, which is impossible and this limits the number of cores, in the case of GPUs the number of Compute Units.

The solution that has always been taken? Instead of adding more elements, what has been done is to make these increasingly complex, for example in the case of GPUs it is the path that NVIDIA took from Turing, instead of increasing the number of SMs compared to Pascal. What he did was add elements such as RT Cores, Tensor Cores and make profound changes in the units, since increasing the number of cores means increasing the number of interconnections.
So we find ourselves with the problem of the energy cost of data transmission / trains, with each new manufacturing node we can increase the number of elements on a chip but we find that the transfer speed we need is increasingly high , which increases energy consumption, causing a large part of the energy power that we give to the processor increasingly goes to data transfer instead of data processing.
Building a GPU with chiplets from a known one
The idea of a construction of a GPU by chiplets is to be able to build a GPU that cannot be manufactured from a monolithic construction and therefore based on a single chip, so the area of a GPU built with chiplets has to be larger that which would allow the limit of the reticle, since then a GPU of this type would not make sense.
This means that the GPUs composed of chiplets will be reserved exclusively for the highest ranges and it is possible that initially we will see them only in the market for GPUs for high-performance computing, HPC, while in the home we are a few more years with GPUs a lot simpler in configuration and therefore monolithic.
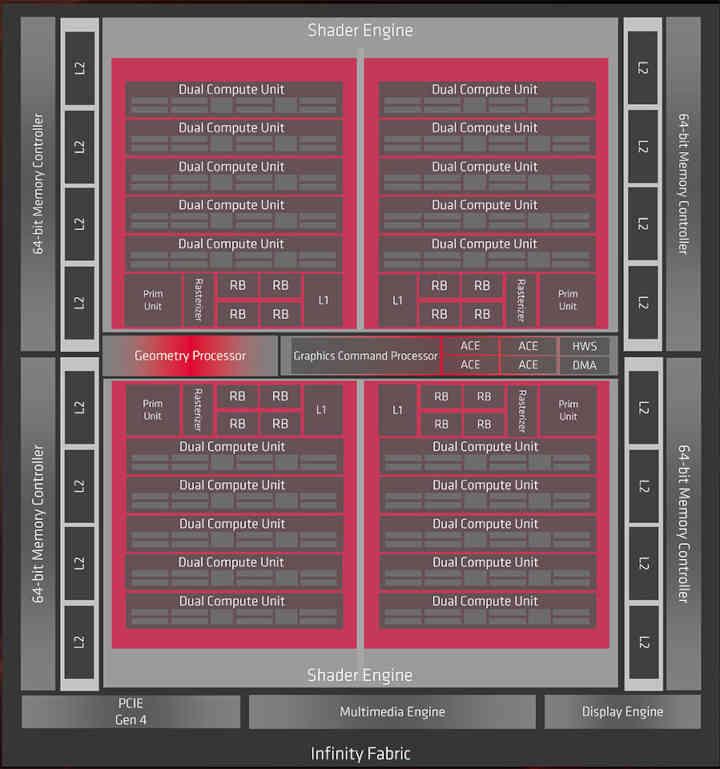
However, we have decided to take the Navi 10 chip, with first-generation RDNA architecture as an example to deconstruct it and create our GPU composed of chiplets, mostly because it is of the latest-generation GPUs that we have the most data on the table. The GPUs that AMD and / or NVIDIA build will have much more complexity than this example, which is indicative so that you have a mental image of how a GPU of this type would be built.
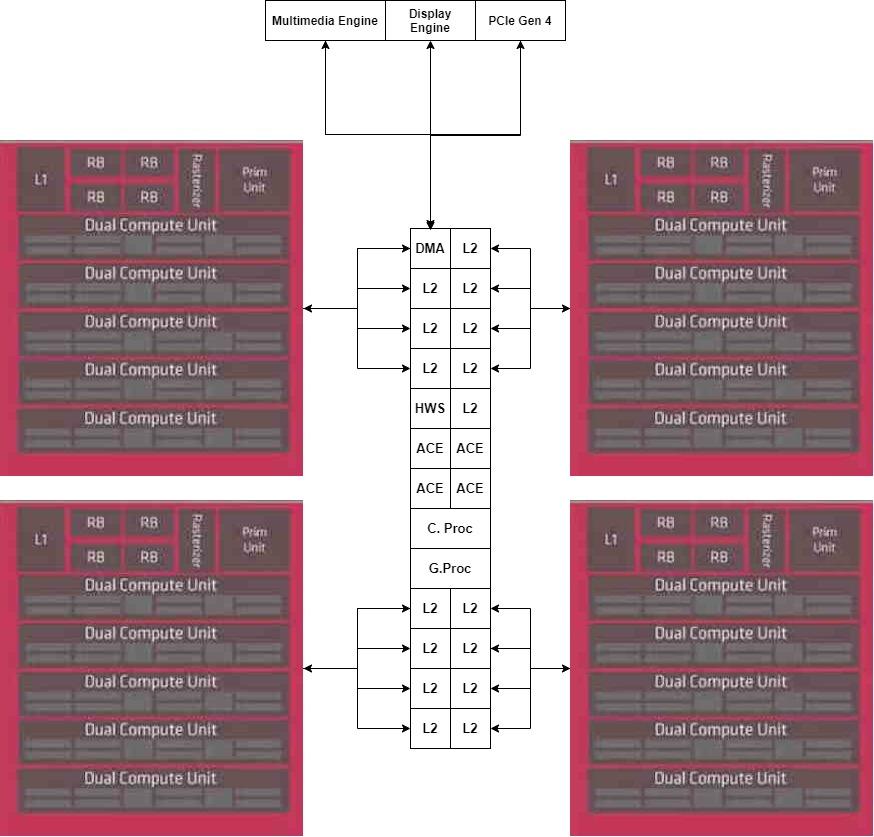
The first idea is that each chiplet is a Shader Array, which are the sets of elements that are on the pink boxes, which are connected to the L1 cache, while we are going to leave the L2 Cache in a separate central chip.
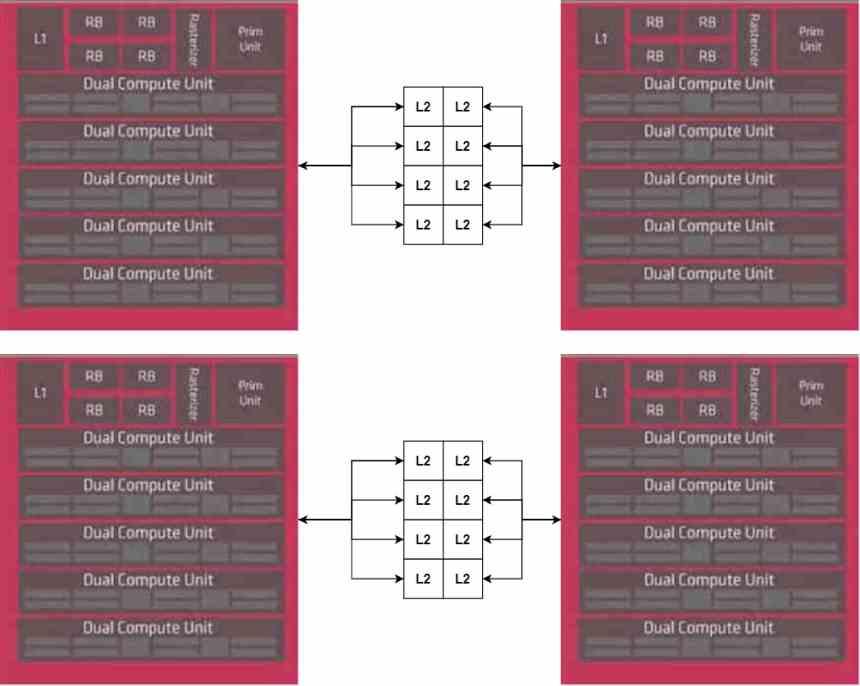
But we do not have the complete GPU, since we lack the central part of it, which is the command processor, which being a single part we will not duplicate, so we will place it in the central part of the MCM.
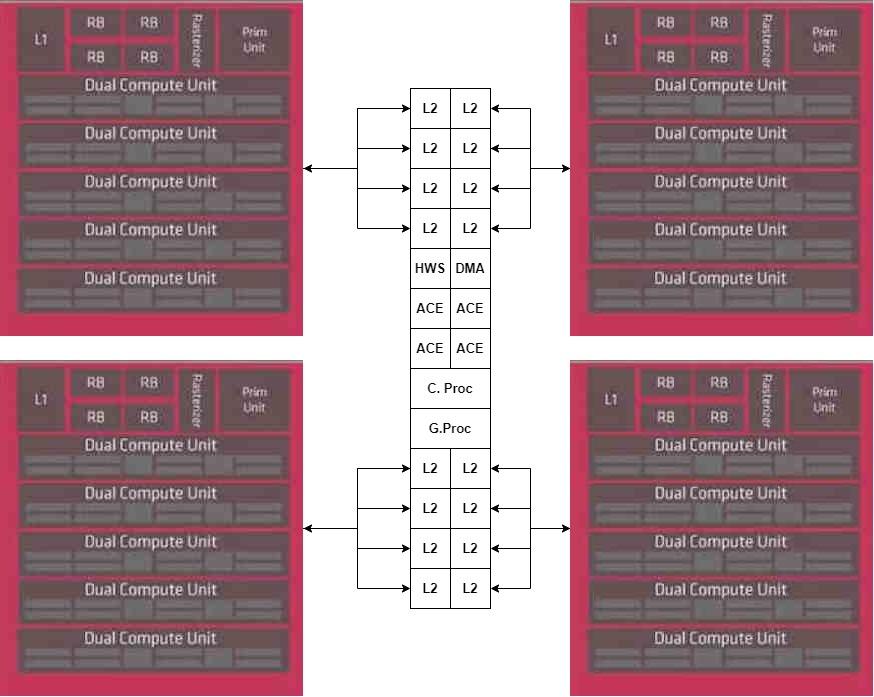
As for the accelerators, we will place them in another chiplet, connected directly to the DMA unit of the central chiplet.
Once we have the GPU broken down into several parts, what interests us now is the communication with the external memory, this will be done by the Interposer, which will have the memory controller integrated inside. Since Navi 10 uses a 256-bit, 8-chip GDDR6 interface, we have decided to keep that configuration in our example.
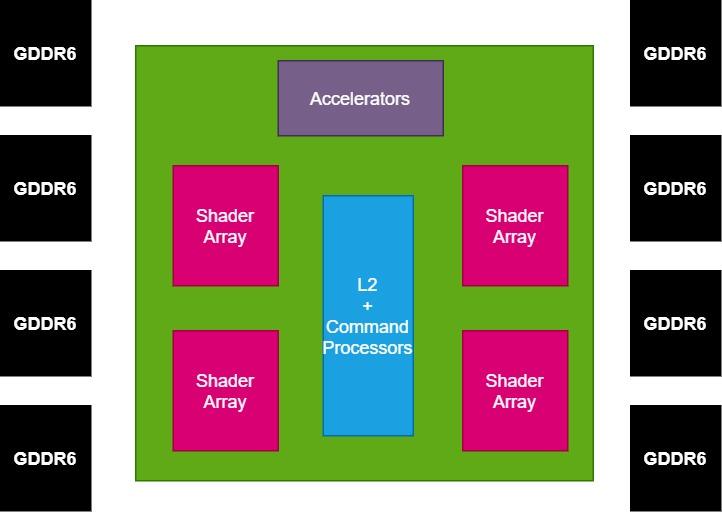
GPU based on chiplets and power consumption
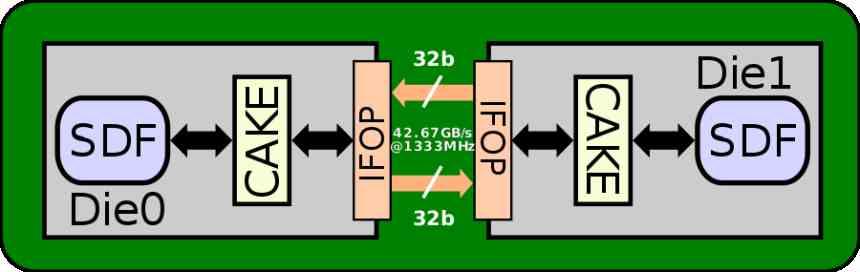
The interface used to communicate elements of the different chiplets is the AMD MCM is the IFOP interface, which has an energy consumption of 2 pJ / bit, if we look at the technical specifications we will see that the L2 cache has a bandwidth of 1.95 TB / It’s at 1905 MHz speed, which is about 1024 bytes, which works out for 16 interfaces of 64 bytes / cycle, 32B / cycle per address.
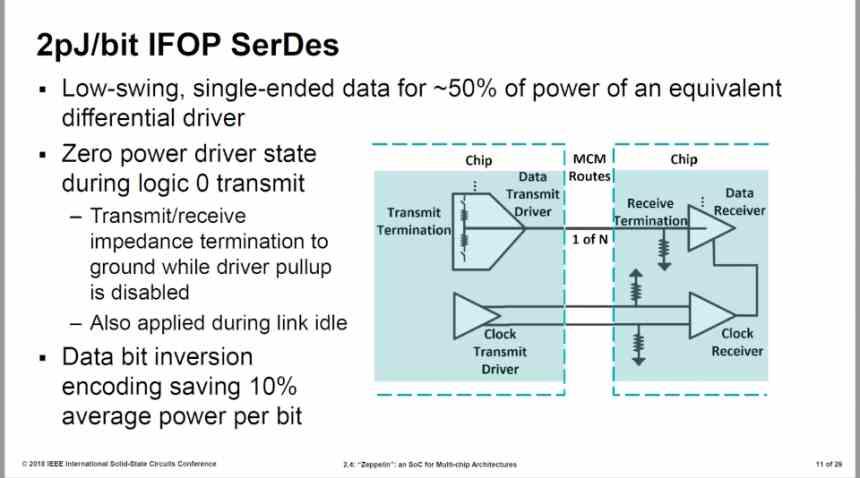
The first version of the Infinity Fabric made use of interfaces of 32B / cycle with a consumption of 2 pJ / bit, however AMD improved by 27%
The IFOP interface has an energy consumption of 1.47 pJ / bit, at a speed of 1333 MHz. If the interface were at 1905 MHz then the energy consumption would be much higher since it would not only increase the clock speed but also the voltage, but let’s assume that our chiplet version of the Navi 10 runs at those 1333 MHz speeds.
(1.33 * 10 ^ 12) * 8 bits per byte * 1.47 pJ per bit = 1.56 * 10 ^ 13 pJ = 15.6 W
Although the 15.6 W may seem a low figure to us, keep in mind that this is only the consumption of transmitting the data of the peripheral chiplets with the central chiplet at a speed of 1333 MHz and that the energy consumption increases quadratically with the clock speed. and the voltage also increases with this.
This means that a good part of the power consumption goes directly to the power consumption of the communication between chiplets, which means that both AMD and NVIDIA have to solve this problem before deploying their chiplet-based GPUs.
AMD’s EHP as an example of a chiplet-based GPU
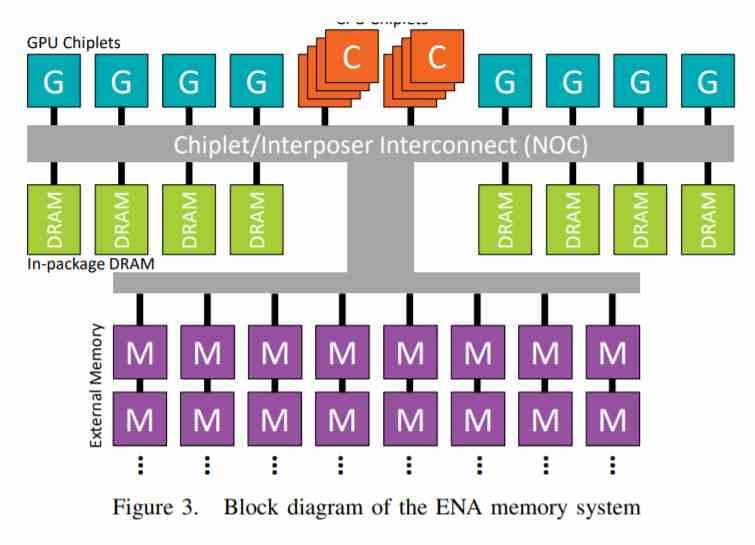
A few years ago, AMD released a paper in which it described a chiplet-based processor with an extremely complex GPU, where they talked about configurations of for example 320 Compute Units in 8 chiplets, which translates into 40 Compute Units per chiplet, the equivalent to a full Navi 10.
In other words, we are talking about a configuration 8 times more complex, so imagine a configuration with 8 chiplets, each one being like a Navi 10 / RDNA and running at speeds above 2 GHz with enormous energy consumption.

This is the reason why AMD and NVIDIA have developed technologies such as X3D and GRS, which are communication interfaces that have an energy consumption per transmitted bit 10 times lower than that of the current Infinity Fabric or NVLink since without a kind of communication interface of that kind is not possible the future of chiplet-based GPUs.