現在、グラフィックス カードは、ゲーム用に設計されたものと、より価値の高い他のアプリケーションに使用されるものの 3 種類に分けられます。 つまり、科学的および軍事的シミュレーションなどに使用されます。 しかし、最初の XNUMXD カードの成功以来、私たちと一緒にいるユニットがあり、 消える可能性のあるラスター単位 また、将来の GPU の構成またはアーキテクチャも同様です。 結果は? ゲーム専用モデルとそれ以外の分野で使用されるモデルの分離の終焉。
今日、リアルタイム 3D ゲームはゲームの 99% を占めていますが、コンピューターでは、当時人気のあった Voodoo Graphics と、共通の機能を担当するチップを搭載したおかげで、これらのゲームが登場しました。 今日、すべてのグラフィックス チップに見られるラスター ユニットについて話していますが、時間の経過とともに消えていきます。 これは、将来のハードウェアにどのような影響を与えるでしょうか?

GPU は変化している
GPU は特殊なグラフィックス プロセッサであり、汎用的に機能する機能を備えています。 これは、彼らのコアが一般的なタスクに使用される特殊なタスク用ではなくなって久しいためです。 そのため、今日、世界の優れたスーパーコンピューターの多くは、大規模な科学的および軍事的シミュレーションや、人工知能などの急成長中のアプリケーションにそれらを使用しています。
ただし、特定のタスクを実行する一連のユニットがまだありますが、これらはグラフィックスを生成できるようにするために必要です。 彼らの仕事は、主要な核をそれらから解放するだけでなく、並行して作業することです. その最大の利点は、固定または特定のタスクを実行することで、構築に必要なトランジスタが少なくて済むため、メインコアにタスクを任せるよりもコストがかからず、消費量が少ないことです。
ただし、他のアイテムのパフォーマンスの進歩に追いついていないか、理想的とは言えない方法で動作するため、専用のハードウェアが時代遅れになることがあります。 グラフィックス カードのメイン チップで、特定のタイプのユニットが出現し、別のタイプのユニットが消えていることがわかりました。

ラスターユニットともお別れ
グラフィックス カードの仕様を見ると、「XNUMX 秒あたりの三角形数」について言及しているカードほど重要性が低くなることがわかります。 多くの人は、画面に表示されているのはこれらの量であると考えており、他の人は計算された量であると信じています. これは実行中のアプリケーションに依存するため、どちらも誤りです。 さらに、これは固定レートであり、気づいたら常にラスター ユニット数のクロック速度です。 少なくとも今日。
これらのユニットは、三角形をラスタライズするのに数クロック サイクルを必要とすることから、現在の速度でそれを実行することまで、パフォーマンスが向上していましたが、3 年間進化していません。 彼の仕事? 頂点で計算された 2D ワールドを、後で色が計算されるピクセルで構成される 3D サーフェス (スクリーン) に投影します。 したがって、XNUMXD シーンを作成すると、すべての三角形が最終的にピクセルになるため、これは不可欠な単位です。 ただし、ユニットはすぐに別れを告げることができると述べました。
理由? あなたの限界
ラスター単位の問題は、非常に小さな三角形、つまり数ピクセルでラスター化された三角形で機能するように設計されていないことです。 さらに、オブジェクトが数ピクセルだけで構成されている場合、ラスタライザーはオブジェクトが遠すぎると判断し、削除のマークを付けます。 もちろん、深度バッファーを使用してカメラまでの距離をチェックしてシーンから除外する前に、計算する必要はありません。 これは、大きなオブジェクトの背後にあるオブジェクトでも行われます。これは、最前面のオブジェクトがある程度透明である場合に問題を引き起こします。 これは問題を引き起こしますが、それはまったく別の問題です。
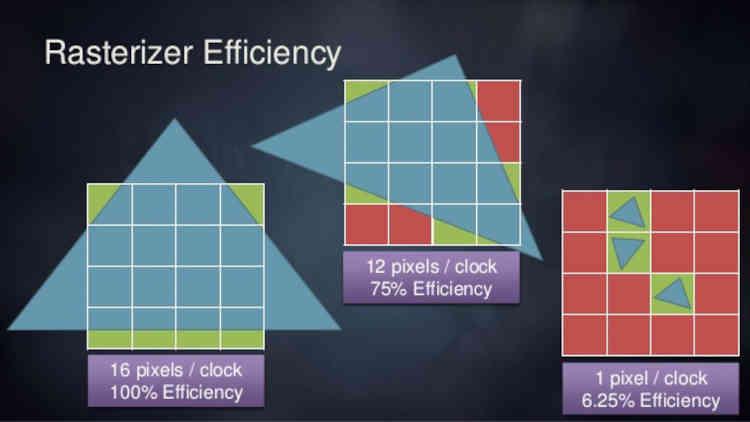
問題? 私たちは、キャラクター、オブジェクト、および設定を詳細化するためにジオメトリが極端なレベルで使用されている世界に移行しています. これは、現在のラスター ユニットがサポートできないトライアングル レートを意味します。 これはボトルネックですが、小さな三角形ではうまく機能しないという問題があります。 100 ピクセルの三角形が 50 個ある場合、これは 200 ピクセルの 25 個にはなりません。 そのため、使用するポリゴンが小さくなるほど効率が低下します。
解決策は何ですか?
Unreal Engine 5 の作成に直面したエピック ゲームズの人々は、コンピューター シェーダーを使用してラスター ユニットを作成しなければならなかったほどです。 つまり、 GPU 特殊な機能ユニットの仕事をはるかにうまくやっているコア。 それはその将来を危険にさらします。 現時点では除外されていませんが、すでにダモクレスの剣と、テッセレーションまたはサーフェス細分割ユニットが搭載されています。
 2020 年 XNUMX 月に行われた Brian Karis へのインタビューで 、グラフィックス プログラマーは、Unreal Engine 5 用に XNUMX 種類のソフトウェア トライアングル ラスタライザーを開発したと述べました。 つまり、GPU コアの XNUMX つを交換して、これらの各ユニットを交換し、パフォーマンスを向上させます。
2020 年 XNUMX 月に行われた Brian Karis へのインタビューで 、グラフィックス プログラマーは、Unreal Engine 5 用に XNUMX 種類のソフトウェア トライアングル ラスタライザーを開発したと述べました。 つまり、GPU コアの XNUMX つを交換して、これらの各ユニットを交換し、パフォーマンスを向上させます。
三角形の大部分は、高度に専門化されたコンピューター シェーダーを使用してソフトウェアによってラスタライズされます。 その結果、ハードウェア ラスタライザーをこの特定のタスクに任せることができました。 ソフトウェアのラスタライゼーションは、Nanite の主要な要素であり、Nanite が行うことを可能にします。 すべてのケースでハードウェア ラスタライザーを打ち負かすことはできないため、最速のパスであると判断した場合はそれらを使用します。
白くてボトルに入っていると読めます。 それらはトランジスタであるという事実のために消えます NVIDIA, インテル & AMD 将来さらに重要になる他のことに利用することができます。
グラフィックス カードの編成が変わるのはなぜですか?
GPU の図を見ると、コアがラスタライザーの周りのブロックに配置されていることがわかります。 これは、話している 3D パイプラインのステージに応じて、これらのユニットに両方のデータを送信し、受信するためです。 したがって、それを削除することは再編成です。 現在、ラスター ユニットの効率を 100% にするための理想的なサイズは、NVIDIA では 48 ピクセル、AMD では 64 ピクセルです。 これにより、ゲーム用に設計されたモデルのコア数も制限されます。 緑色のブランドの場合、ハイ パフォーマンス コンピューティングとゲーム用のチップを比較するとわかります。

ご覧のように、H100 GPC にはラスター エンジンがないため、そのような固定された組織を持たず、したがって制限があります。 この変更により、NVIDIA と AMD は、HPC とゲーム用に 2 つの異なる設計を設計する必要がなくなり、代わりに、設計に関してユニバーサル ベース モデルから引き出せるようになります。 そこから反復できます。 今日、私たちが話しているのが中央処理装置であるかグラフィックス処理装置であるかに関係なく、相互通信はチップ全体の 3/3 から 4/XNUMX の間であり、XNUMX つの異なるチップで作業しなければならないという事実は気が遠くなるようなものです。
それぞれの新しいノードはより多くのトランジスタであることを忘れないでください.これはより多くの部品とより多くのエンジニアを雇うことです. XNUMX つの異なるモデルを作成しても利益が得られず、ラスター ユニットの排除が鍵となるため、科学研究用に提供されているのと同じグラフィックス カードがゲーム用のハイエンドになるポイントに到達します。この開発プロセス全体で。 統一。