Today’s society needs an abundant exchange of information for the development of most activities or jobs. For example, companies, especially multinationals, distribute their projects among the many headquarters they have around the world; This means that there must be communication and information exchange between the different venues for the proper development of their projects. Another example is universities, which need a system to exchange information with students, to provide them with notes, exams, etc.
That is why around 1996, the first P2P application emerged from the hands of Adam Hinkley, Hotline Connect, which was intended to be a tool for universities and companies for the distribution of files. This application used a decentralized structure and it did not take long to become obsolete (because it depended on a single server); and since it was designed for Mac OS, it did not produce much interest from users.

It is with Napster, in 1999, when the use of P2P networks aroused curiosity among users. This music exchange system used a hybrid P2P network model, since apart from communication between peers, it included a central server to organize these pairs. Their main problem was that the server introduced breakpoints and a high possibility of bottlenecks.
This is why new topologies such as decentralized are emerging, whose main characteristic is that it does not need a central server to organize the network; an example of this topology is Gnutella. Another type is structured P2P networks, which focus on organizing content rather than organizing users; as an example we highlight JXTA. We also have the networks with Distributed Hashes Table (DHT), such as Chord.
Next, we will develop the types of P2P networks mentioned above.
First P2P systems: a hybrid approach
The first P2P systems, such as Napster or SETI @ home, were the first to move the heaviest tasks from servers to users’ computers. With the help of the Internet, which allows combining all the resources that users provide, they managed to make these systems reach a greater storage capacity and greater computing power than servers. But the problem was that without an infrastructure to act as an intermediary between the peer entities, the system would become chaos, as each peer would end up acting independently.
The solution to the problem of disorder is to introduce a central server, which will be in charge of coordinating the pairs (coordination between pairs can vary greatly from one system to another). These types of systems are called hybrid systems, since they combine the client-server model with the model of P2P networks. Many people think that this approach should not be described as a real P2P system, as it introduces a centralized component (server), but despite this, this approach has been and continues to be very successful.
In this type of systems, when an entity connects to the network (using a P2P application), it is registered on the server, so that the server has controlled at all times the number of pairs that are registered on that server, allowing them offer services to other peers. Normally, peer-to-peer communication is point-to-point, since the peers do not form any major network.
The main problem with this design is that it introduces a system break point and a high probability of a so-called “bottleneck” occurring (In data transfer, when the processing capacity of a device is greater than the capacity to which the device is connected). If the network grows, the server load will also grow and if the system is not able to scale the network, the network will collapse. And if the server fails, the network would not be able to reorganize itself.
But despite everything, there are still many systems that use this model. This approach is useful for systems that cannot tolerate inconsistencies and do not require large amounts of resources for coordination tasks. As an example, here’s how Napster works. Napster emerged at the end of 1999, by the hand of Shawn Fanning and Sean Parke, with the idea of sharing music files between users.

The way Napster works is that users must connect to a central server, which is responsible for maintaining a list of connected users and the files available to those users. When a user wants to get a file, they do a search on the server and the server gives them a list of all the pairs that have the file they are looking for. Thus, the interested party looks for the user who can best provide what he needs (selecting those with the best transfer rate, for example) and obtains his file directly from him, without intermediaries. Napster soon became a very popular system among users, reaching 26 million users in 2001, causing discomfort among record companies and musicians.
That is why the RIAA (Recording Industry Association of America) and several record companies, in an attempt to end it, filed a lawsuit against the company, which caused the closure of its servers. This caused a network crash as users were unable to download their music files. As a consequence, a large part of users migrated to other exchange systems such as Gnutella, Kazaa, etc.
Later, around 2008, Napster became an MP3 music sales company, with a large number of songs to download: free.napster.com.
Unstructured P2P networks
Another way of sharing files is using a non-centralized network, that is, a network where any type of intermediary between users is eliminated so that the network itself is in charge of organizing communication between peers.
In this approach, if a user is known, a “union” is established between them, so that they form a “network”, which can be joined by more users. To find a file, a user issues a query, which floods the entire network, in order to find the maximum number of users who have that information.
For example, to perform a search in Gnutella, the interested user issues a search request to his neighbors, and these to theirs. But to avoid collapsing the network with a small query, the broadcast horizon is limited to a certain distance from the original host and also the lifetime of the request, because each time the message is forwarded to another user, its time of life decreases.
The main problem with this model is that if the network grows, the query message will only reach a few users. If what we are looking for is something well known, surely any host within our diffusion horizon will have it, but on the other hand, if what we are looking for is something very special, we may not find it because by having the diffusion horizon limited, we will have left out to hosts that perhaps contained the information we are looking for.
To this day, pure non-centralized P2P networks have been replaced by new technologies, such as Supernodes .
SUPERNODOS, a hierarchy in unstructured networks
The main problems with unstructured networks were the diffusion horizon and the size of the network. We have two possible solutions: either we increase the broadcast horizon, or we decrease the size of the network. If we choose to increase the broadcast horizon, we increase the number of hosts to which we must send the query message exponentially. This would cause, as we have already seen, problems in the network, such as the collapse of it. On the contrary, if we choose to reduce the size of the network, the systems are able to scale much better over the network, using the supernodes.
The main idea of this system is that the network is divided between numerous terminal nodes and a small group of supernodes well connected between them, to which the terminal nodes are connected. In order to be a supernode, it is necessary to be able to offer enough resources to other users, especially bandwidth. This network of supernodes, to which only a few can become part, is responsible for keeping the size of the network small enough not to lose efficiency in searches.
Its operation is similar to that of the hybrid model, since the terminal nodes are connected to the super nodes, which take the role of servers, so that users only connect with other users to exclusively perform downloads. Supernodes store information about what each user has, so that it can reduce the time of a search, sending the information to the terminal nodes that have what we are looking for.
This type of structure is still widely used today, mainly because it is very useful for exchanging information on popular content or for searching for keywords. As the network of supernodes is reduced, these systems scale very well over the network and do not offer breakpoints like the hybrid model. On the other hand, they decrease the robustness against attacks and network drops and lose precision in the search for results, due to the replication through the supernodes. If a small number of supernodes fail, the network is divided into small partitions.
Structured P2P networks
This approach is developed in parallel with the supernode approach described above. Its main characteristic is that instead of taking care of organizing the nodes, it focuses on the organization of content, grouping similar content on the network and creating an infrastructure that allows efficient search, among other things.
The peers organize among themselves a new virtual network layer, “an overlay network”, which is situated on top of the basic P2P network. In this overlay network, the proximity between hosts is given as a function of the content they share: they will be closer to each other the more resources they provide in common. This way we guarantee that the search is carried out efficiently within a not too distant horizon and without reducing the size of the network. As an example, JXTA, where peers act in a virtual network and are free to form and leave groups of peers. Thus, search messages normally stay within the virtual network and the group acts as a grouping mechanism, combining pairs with the same or similar interests.
This approach offers high performance and accurate searches, if the virtual network accurately reflects the similarity between the nodes with respect to searches. But it also has a series of drawbacks: it has a high cost of establishing and maintaining the virtual network in systems where hosts enter and leave very quickly; they are not very suitable for searches that include Boolean operators, since nodes that are capable of searching with more than one term would be needed.
A subclass within this type of P2P networks are distributed hash tables.
Distributed Hash Tables (DHT)
The main characteristic of DHTs is that they do not organize the overlay network by its content or its services. These systems divide their entire workspace by means of identifiers, which are assigned to the peers that use this network, making them responsible for a small part of the total workspace. These identifiers can be, for example, integers in the range [0, 2n-1], where n is a fixed number.
Each pair that participates in this network acts as a small database (the set of all pairs would form a distributed database). This database organizes your information in pairs (key, value). But to know which pair is in charge of saving that pair (key, value), we need the key to be an integer within the same range with which the participating pairs of the network are numbered. Since the key may not be represented in the integers, we need a function that converts the keys to integers within the same range with which the pairs are numbered. This function is the hash function. This function has the characteristic that when faced with different inputs, it can give the same output value, but with a very low probability. That is why instead of talking about a “distributed database”, we talk about Distributed Hashes Table (DHT), because what each pair of the pair (key, value) actually stores, is not the key as such, but the hash of the key.
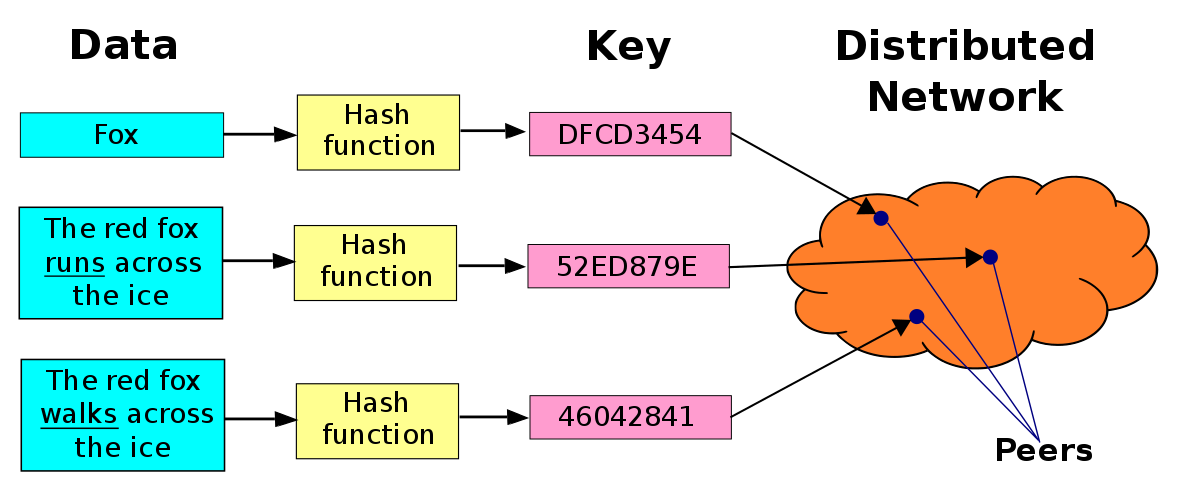
We have already discussed that each pair is responsible for a portion of the network workspace. But how do you map the pair (key, value) to the proper pair? For this, a rule is followed: once the hash of the key has been calculated, the pair (key, value) is assigned to the pair whose identifier is the closest (the immediate successor) to the calculated hash. In the case that the calculated hash is greater than the identifiers of the pairs, the modulo 2n convention is used.
Once we have talked a bit about the basic operation of DHT, we are going to see an example of its implementation, through the CHORD protocol.
Distributed search protocol in P2P networks: CHORD
Chord is one of the most popular distributed search protocols on P2P networks. This protocol uses the SHA-1 hash function to assign, both to the pairs and to the stored information, their identifier. These identifiers are arranged in a circle (taking all the values modulo 2m), so that each node knows who its ancestor and its most immediate successor are.
In order to maintain the scalability of the network, when a node leaves the network, all its keys pass to its immediate successor, in such a way that the network is always kept up to date, thus avoiding that searches could be erroneous.
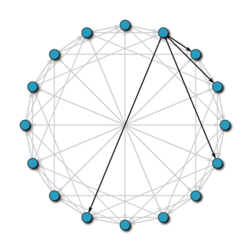
In order to find the person in charge that stores a key, the nodes are sending messages to each other until they find it. But, due to the circular arrangement of the network, in the worst case, a query can cover half of the nodes, making it very expensive to maintain it. To avoid this, and thus reduce cost, each node has a routing table stored, in which the address of nodes that are a certain distance from it is stored. In this way, when we want to know who is in charge of the key k, the node searches its routing table to see if it has the address of the person in charge of k; if it does, it sends you the request directly; if it does not have it, it sends the question to the nearest node of k, whose identifier is less than k.
With this improvement, we have managed to lower the cost of searches from N / 2 to log N, where N is the number of the network node.
Conclusions.
As we have seen, there are many types of P2P networks, each with its strengths and weaknesses. None stands out above the other, which allows, when programming, for example, a P2P application, to have several options, each with its own characteristics.
One thing to keep in mind is how the way of sharing information is evolving. At the end of the last millennium, the use of P2P networks was abundant and, for most people, it was the only known way to share information. Today the trend has changed. People now prefer to exchange files through large servers where in some cases they pay users to host them.
Some questions that may come to mind are: What is the future of P2P networks? Towards what forms of organizing information have we evolved?
One of the possible evolutions is the jump from P2P to p4p. What is the P4P? As a summary we will say that P4P, also known as hybrid P2P, is a small evolution of P2P whose main characteristic is that service providers, ISPs, form an essential role within the network, since when it comes to doing A search will first search among the participating nodes that belong to the same ISP.