One of the details that has attracted the most attention after the presentations of the NVIDIA RTX 3000 has been the fact of its performance in FP32. Until now, the progression in NVIDIA’s so-called TFLOPS Shaders had been scalable to a greater or lesser extent, but with Ampere those numbers have doubled, and have raised the alarms of many users who continue with the idea that FP32 performance is synonymous with veracity to compare architectures. Why is this happening?
The explanation has a lot to do with one of the fundamental changes in the architecture and what NVIDIA has called 1/2 FP32 rate. This name does not come from now, but from the Turing architecture and its SMs, where, as we well know, integers were separated from floats and this resulted in the ability to include three different engines, but with some drawbacks.

The FP32 Shaders TFLOPS rate is directly related to the CUDA count
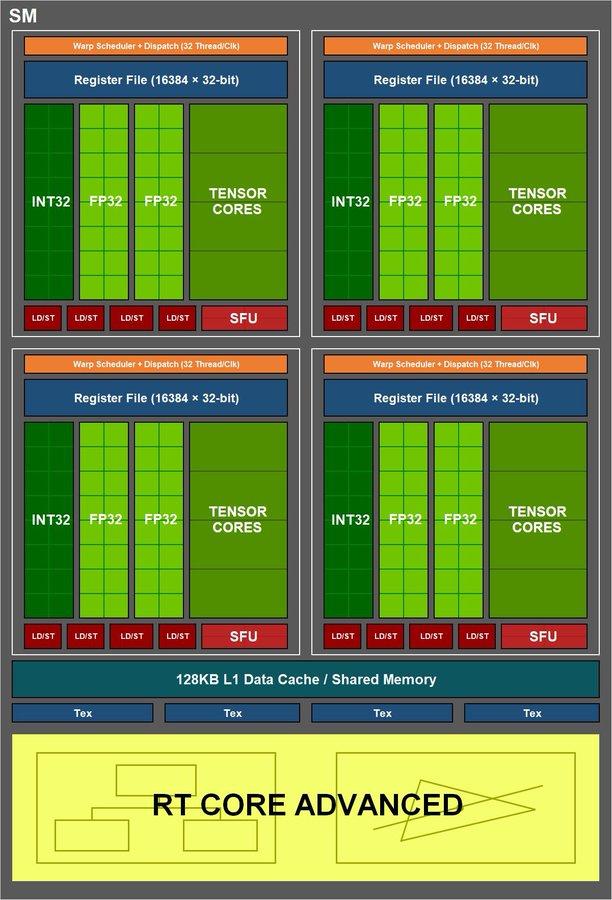
“Magically” (note the irony) NVIDIA has unilaterally decided to double the Shader count on its Ampere graphics cards. A marketing action that still has a small foundation that inexorably links to the performance data in Shaders TFLOPS.
To understand everything, we have to start from the base of Volta as an architecture, since it was the pioneer in the 1/2 FP32 that NVIDIA talks about and that dragged Turing to the same task. In both architectures, each SM was capable of executing 1 package of 32 instructions per clock, which had to be divided into 16 operations for FP32 and 16 operations for INT32 , or what is the same, 16 instructions for floating point and 16 for numbers. integers for each clock cycle.
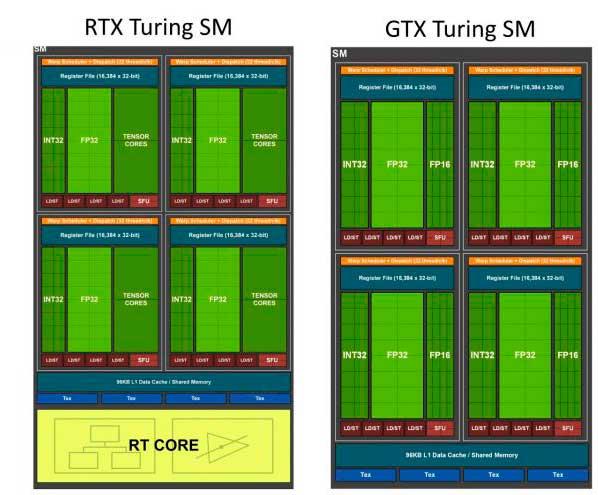
Why do it like this? Well, because in the first place NVIDIA rented as a general architecture the fact that there were fewer FP32 operations if in exchange it divided the rendering of each frame into the three engines mentioned above to be able to work with Ray Tracing or DLSS.
In other words, it sacrificed FP32 capacity for INT32 in exchange for the biggest leap in architecture in 10 years, knowing that this change had a slight performance advantage for each SM and in part gave it the ability to work with BVH and AI algorithms to the games.
Ampere puts things back in their place
With the RTX 3000 and the Ampere architecture, NVIDIA breaks with that 1/2 FP32 and re-executes 32 FP32 operations for each clock within the SM (we could speak of 4 engines instead of three, at least theoretically), for what under the magnifying glass and optics of the company this is “magically” doubling the number of total Shaders in the specifications, but the reality is that this does not really work like that, far from it, since NVIDIA has only doubled a part of the engines, leaving the rest intact, so performance will not be the equivalent of doubling the number of shaders.
- RTX 3090 -> 10496/2 = 5248
- RTX 3080 -> 8704/2 = 4352
- RTX 3070 -> 5888/2 = 2944
The actual number of Shaders of the three NVIDIA reference cards today is just half and this influences the logical calculation of their theoretical performance in FP32. We focus on theoretical, since we have already seen the farce that this value represents when comparing performance in specifications against real performance.
So with that being said, let’s explain how NVIDIA could have doubled its performance so magically.
From doubling its performance in FP32, to only being able to mark a “small” margin

If we look at the official NVIDIA specs, the RTX 3090 gets an FP32 performance of 35.58 TFLOPS , or as they call it: Shader TFLOPS. This figure is very easy to calculate and shows the terrible error of comparing TFLOPS as a standard measure between any hardware component:
Shaders x frequency x 2 operations per cycle x 1 GPU
In the case of the RTX 3090, we will get 10,496 x 1,700 x 2 x 1 -> 35,686,400 FLOPS or 35,686 TFLOPS (assuming 100% efficiency in the architecture, something impossible on any chip). Logically, this value is totally unrealistic for what has been commented above, and it does not reflect a superiority compared to an RTX 2080 Ti of almost three times its performance.
The correct number in TFLOPS would be 17,843 TFLOPS , or 32.66% more floating point performance than an RTX 2080 Ti. But this difference only refers to FP32 and leaves out performance in INT32 for example.
What we have seen so far is that the difference in performance is between 24% and 29% approximately and depending on the resolution chosen, but as we see it is very far from the marketing that the company has tried to establish and that unfortunately will end up imposing itself. with its TFLOPS Shaders.