Shader programs first arrived on GPUs starting with the NVIDIA GeForce 3, but it wasn’t until the later release of the GeForce 8800 by NVIDIA and the AMD Radeon R600 that we got to see the first Compute Units o Contemporary SMs, which are still used today.
Shader units are extremely important, as they run the different shader programs that run at different stages of the graphics pipeline, as well as programs used in high-performance computing when the GPU is not used to render graphics. So they have become a fundamental piece in any graphic architecture whatever its use.

Compute Units or SMs elements
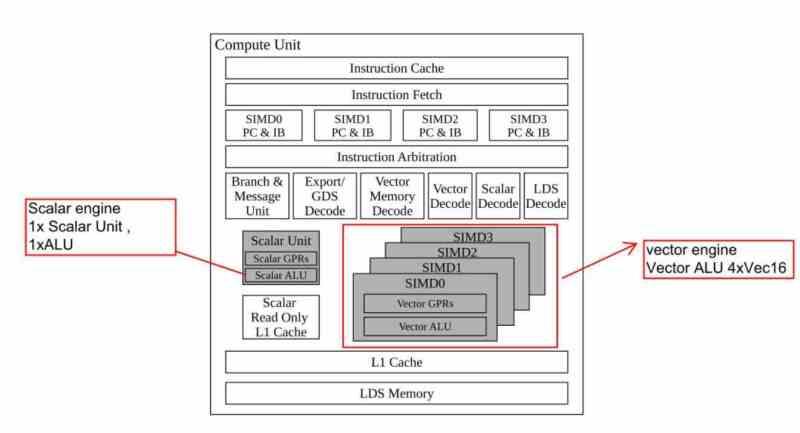
All Compute Units have the following elements in common:
- Instruction cache
- Data cache, where the data is stored that will later be copied into the registers, also called texture cache.
- Planner, which controls which instructions are executed and in what order, this unit is in charge of moving the instructions that have not been executed on time to the queue.
- SIMD units: in charge of executing the different instructions, due to their large number, SIMD units can only execute simple arithmetic instructions such as addition, subtraction and multiplication.
- SFU units: In charge of executing more complex arithmetic instructions, they are much less than SIMD units due to their complexity and they are in charge of arithmetic operations such as powers, roots, logarithms. Which are not very common, but which would be very slow to execute by SIMD units.
- Registers: This is where the data and instructions to be executed by the SIMD and SFU units are stored. That is, the waves or warps are stored in this part.
- Texture filtering units
- Local Memory: A memory space that is used to communicate several waves with each other.
How do Compute Units work?
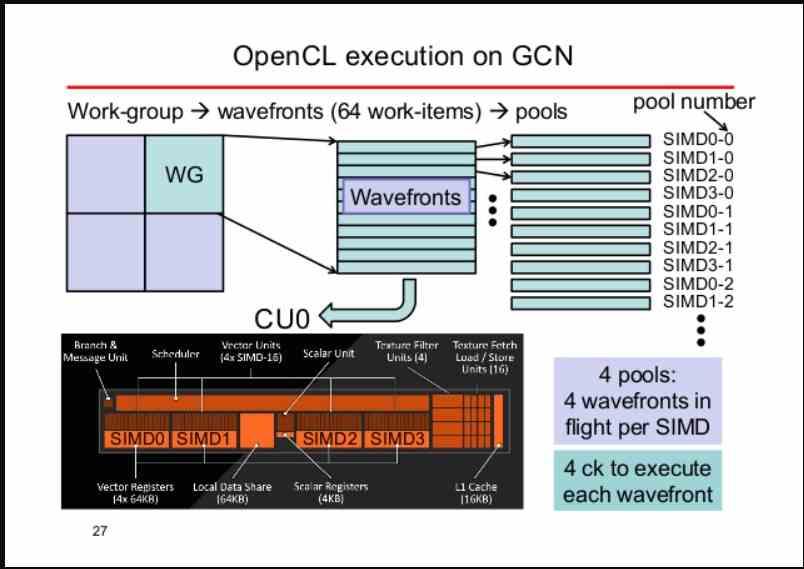
Shader units do not execute shader programs in the same way that a CPU executes its programs, since while the CPU has a fetch phase from memory, in the case of shader units, this process is not active but passive. That is, it is the groups of instructions and data in the different threads of execution that go to these units. This is called Stream Processing, which in Spanish would be translated as flow processing.
Flow processing supposes that the instructions are executed as they arrive at the registers of the shader unit, where the different units are executing the instructions found in said registers in a sequential manner, which do not have to belong to all of them. same shader program.

Each type of instruction has an average time to execute depending on its type, for example in GCN architectures the instructions were divided into three different types:
- Simple: They are solved in a single instruction cycle.
- Complex: They are solved in four instruction cycles
- Jump: They are solved in sixteen instruction cycles
In a shader unit there are no direct memory access instructions, so the data must be next to the instruction to be executed. When the instruction takes time to execute due to lack of data, it is delayed in its execution and the next one is advanced. This is called Round-Robin execution and it is used so that each of the Compute Units does not stop running dry.
What is a Wave or Warp?

A wave or Warp is what we call a set of kernels of variable size, each kernel being a simple instruction with its corresponding data. Because in graphical processing the same instruction is applied for several graphical primitives at the same time, SIMD units are used to execute the different waves.
Depending on each architecture, a wave can have one size or another, the standard sizes being 32 and 64 elements. If, for example, we have a wave of 64 elements and a SIMD unit of 16 ALUs, then we can assign one element to each ALU per clock cycle. Then depending on the type of instruction this may take more or less to resolve the wave.
The number of waves a Compute Unit or SM can withstand depends on how large its registers are. As long as there are waves and therefore kernels to execute, said Compute Unit will continue executing the different waves and will remain busy. That is why the central part of the GPU must be able to feed a sufficient number of waves to each Compute Unit or SM.
Use of ALUs and registry occupancy

One of the problems that existed in the Compute Units of the first generation AMD GCN and RDNA units was that per SIMD unit the GPU scheduler was designed to execute up to 40 waves of 64 elements each per SIMD unit. Which taking into account the running time, this was about 40 clock cycles.
The problem? If you wanted to occupy most of the ALUs of the SIMD unit, then dead cycles were created, since there was no longer anything to calculate. If you wanted to take advantage of all the cycles then the ALUs then found that all the SIMD units were not busy. The solution? AMD in RDNA 2 decided to reduce the capacity of the scheduler from 40 to 32 elements in order to achieve the highest occupancy in the different units of its Compute Units.