Le plus gros point faible du RX 6000 par rapport au RTX 30 est sa performance face au Ray Tracing. Il s'agit simplement de l'activer dans les jeux et de voir comment le différentiel augmente en faveur de NVIDIA cartes. Cela a mené AMD apporter des modifications à la Architecture RDNA 3 pour le lancer de rayons . Tout indique donc que ce sera la partie la plus avantageuse de toutes pour la prochaine génération du RX 7000.
L'un des points faibles que l'architecture RDNA avait à ses débuts, composée de la gamme RX 5000, était son manque d'unités analogues aux cœurs NVIDIA RT, qui sont chargés d'exécuter deux tâches courantes dans Ray Tracing. Le premier d'entre eux est le calcul de l'intersection rayon-objet, qui se produit plusieurs milliards de fois par seconde et consomme une grande quantité de ressources. La seconde est la traversée de la structure de données qui représente la scène. AMD a décidé d'opter pour une solution mixte. Où l'intersection est calculée à travers ses unités d'accélérateur de rayons, mais elles ne calculent pas la structure de données. Une solution qui n'a finalement pas été la plus efficace.

Modifications des unités de calcul RDNA 3 pour le lancer de rayons
Lors de sa dernière conférence publique destinée aux investisseurs et actionnaires, AMD a fait un rapide aperçu de ce que nous pouvons voir dans le futur RX 7000. Certains changements nous étaient déjà connus, comme le fait que certains modèles de la gamme ont été désagrégés en plusieurs puces différentes. , tout comme le bureau Ryzen, et l'utilisation du nœud 5 nm de TSMC. Cependant, ce n'est pas le seul changement que nous verrons et il semble que l'engagement d'AMD envers le Ray Tracing dans RDNA 3 sera plus important que jamais. Eh bien, qu'est-ce que rendu hybride pour, qui est ce que les jeux utilisent, combinant le pixellisation de pipeline 3D typique avec lancer de rayons pour le calcul de l'éclairage indirect en tout ou en partie.


N'oublions pas que les unités de calcul sont le véritable cœur de la puce graphique car elles disposent de toutes les pièces pour réaliser les différentes étapes du cycle de chaque instruction et le fait qu'AMD annonce officiellement qu'il va changer son organisation est significatif . La dernière fois qu'il l'a fait, c'était avec le passage du RX Vega au RX 5000 et cela lui a suffi pour commencer à parler d'une nouvelle architecture. Bien que la première chose que nous espérons est une meilleure unité d'accélération de rayons qui exécute sa tâche plus efficacement et qui est au moins au niveau de celles qui existent dans le RTX 30. Et oui, les unités d'intersection se trouvent au sein de chaque unité de calcul.
Double FLOPS par unité de calcul
L'autre amélioration attendue est de doubler la capacité de calcul en virgule flottante, de la même manière que NVIDIA l'a fait dans son RTX 30. La façon de le faire sera pour placer deux fois plus d'unités à virgule flottante 32 bits par rapport à la génération précédente. Nous ne le savons pas officiellement via le marketing AMD, mais nous le savons grâce à des informations suffisamment officielles telles que ses propres brevets et les pilotes graphiques.
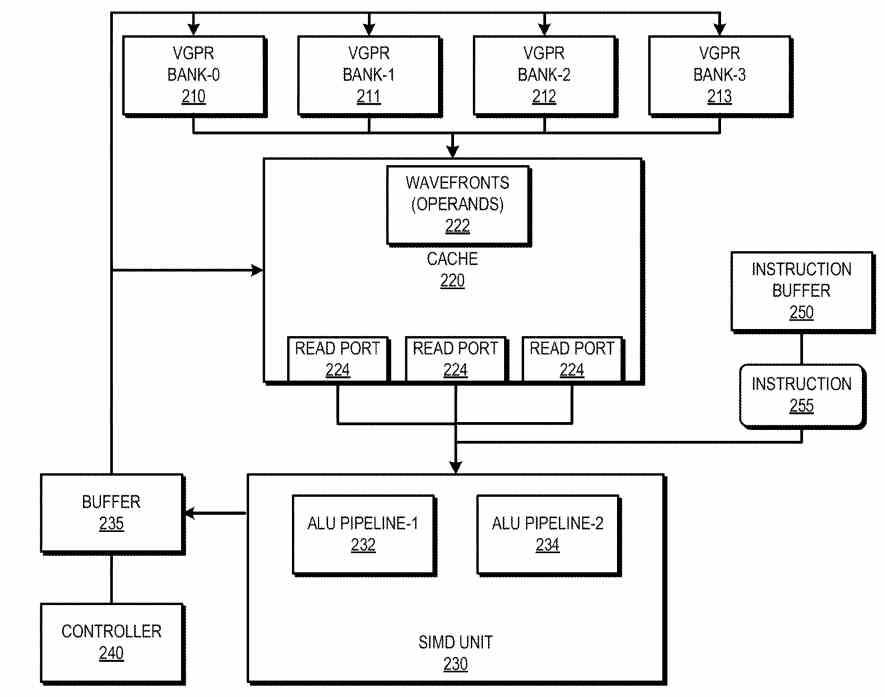
Dans les deux cas, nous avons pu apprendre que des instructions doubles peuvent être envoyées aux unités de calcul. Par conséquent, chaque unité SIMD au sein de l'unité de calcul et qui englobe les différentes unités à virgule flottante 32 bits passera de 32 éléments en RDNA 2 à 64 éléments en RDNA 3 . Lesdites instructions ou threads peuvent être exécutés sous la forme de 32 instructions doubles ou de threads 32 bits ou de 64 instructions ou threads simples.