Eines der Schlüsselkonzepte zum Verständnis der Architektur und Leistung von Strom Intel und AMD CPUs ist das Konzept von Mikrooperationen sowie von Einheiten wie ihrem Cache. In diesem Artikel erklären wir Ihnen auf verständliche Weise, was sie sind und warum die heutigen Prozessoren ihren gesamten Betrieb darauf stützen, um die maximal mögliche Leistung zu erzielen.
A CPU kann heute eine Vielzahl unterschiedlicher Befehle ausführen, und zwar mit bis zu 5,000-mal höherer Frequenz als bei frühen Personal Computern. Wir neigen zu der völlig falschen Annahme, dass der höhere MHz- oder GHz-Anteil auf die neuen Hersteller zurückzuführen ist. Die Realität sieht ganz anders aus, und hier kommen Mikrooperationen ins Spiel, die der Schlüssel zum Erreichen der enormen Rechenleistung heutiger Mikroprozessoren sind.

Was sind Mikrooperationen?
Einer der Vergleiche mit der Realität, die normalerweise verwendet werden, um zu erklären, was ein Programm ist, ist der Vergleich mit einem Kochrezept. Darin sehen wir in einem Verb eine Reihe von Handlungen zugeordnet, die wir ausführen müssen. Zum Beispiel kann ich ein Rezept einfügen, dass Sie ein Stück Fleisch in der Pfanne braten, aber für Sie stellt sich heraus, dass Sie nach der Pfanne suchen müssen, dasselbe mit dem Öl tun, letzteres in die Pfanne geben und warten müssen heiß werden lassen und das Fleischstück hineinlegen. Wie Sie sehen können, haben wir etwas, das im Prinzip durch ein einzelnes Verb definiert ist, in eine Reihe von Aktionen umgewandelt.
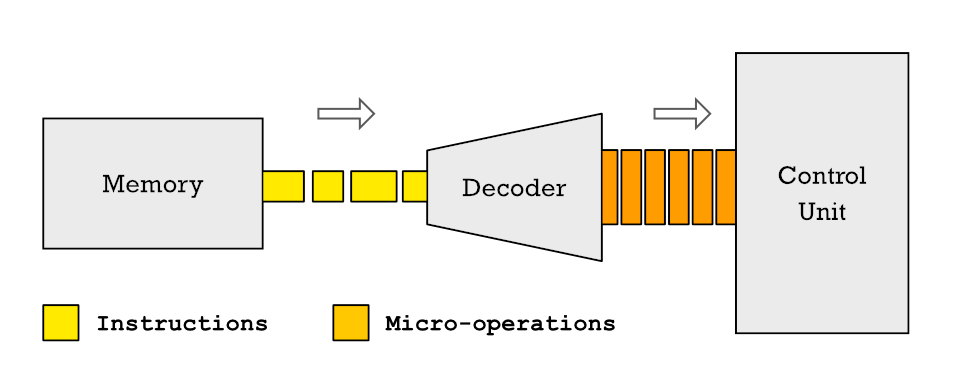
Nun, die Anweisungen einer CPU können in kleinere unterteilt werden, die wir Mikrooperationen nennen. Und warum keine Mikrobefehle? Nun, aufgrund der Tatsache, dass eine Anweisung, nur indem sie für ihre Ausführung in mehrere Zyklen unterteilt wird, mehrere Taktzyklen benötigt, um aufgelöst zu werden. Andererseits dauert eine Mikrooperation einen einzigen Taktzyklus.
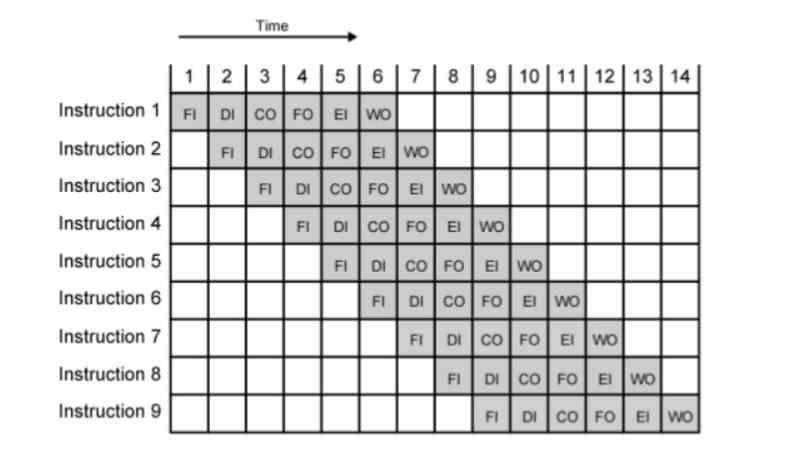
Eine Möglichkeit, die meisten MHz oder GHz zu erreichen, ist Pipelining, bei dem jeder Befehl in mehreren Stufen ausgeführt wird, die jeweils einen Taktzyklus dauern. Da die Frequenz das Inverse der Zeit ist, müssen wir die Zeit verkürzen, um mehr Frequenz zu erhalten. Das Problem besteht darin, dass ab dem Punkt, an dem ein Befehl nicht mehr zerlegt werden kann, die Anzahl der Stufen in der Pipeline kurz und damit die erreichbare Taktrate gering wird.
Tatsächlich wurden diese mit dem Erscheinen der Out-of-Order-Ausführung der Intel P6-Architektur und ihrer abgeleiteten CPUs wie Pentium II und III geboren. Der Grund dafür ist, dass die Segmentierung des P5 oder Pentium nur knapp über 200 MHz erlaubte. Mit den Mikrooperationen, indem sie die Anzahl der Stufen jeder Anweisung noch mehr verlängerten, übertrafen sie mit dem Pentium 3 die GHz-Grenze und konnten mit dem Pentium 16 4-mal höhere Taktraten erzielen. Seitdem werden sie in allen CPUs mit verwendet Out-of-Order-Ausführung, unabhängig von Marke und Register und Befehlssatz.
Ihre CPUs sind weder x86 noch RISC-V oder ARM
In gegenwärtigen CPUs werden Befehle, wenn sie an der CPU-Steuereinheit ankommen, um dekodiert und der Steuereinheit zugewiesen zu werden, zuerst in mehrere unterschiedliche Mikrooperationen zerlegt. Dies bedeutet, dass jede Anweisung, die der Prozessor ausführt, aus einer Reihe grundlegender Mikrooperationen besteht und der Satz von ihnen in einem geordneten Fluss als Mikrocode bezeichnet wird.

Die Zerlegung von Anweisungen in Mikrooperationen und die Transformation von darin gespeicherten Programmen RAM in Microcode findet sich heute in allen Prozessoren. Also, wenn Ihr Telefon ISA ist ARM Die CPU oder die x86-CPU Ihres PCs führt Programme aus, ihre Ausführungseinheiten lösen keine Anweisungen mit diesen Sätzen von Registern und Anweisungen auf.
Dieses Verfahren hat nicht nur die Vorteile, die wir im vorherigen Abschnitt erläutert haben, sondern wir können auch Anweisungen finden, die selbst innerhalb derselben Architektur und unter demselben Satz von Registern und Anweisungen unterschiedlich aufgeteilt sind und die Programme vollständig kompatibel sind. Die Idee besteht oft darin, die Anzahl der erforderlichen Taktzyklen zu reduzieren, aber meistens geht es darum, die Konkurrenz zu vermeiden, die auftritt, wenn es mehrere Anforderungen an dieselbe Ressource innerhalb des Prozessors gibt.
Was ist der Micro-Op-Cache?
Das andere wichtige Element, um die maximal mögliche Leistung zu erreichen, ist der Micro-Operations-Cache, der später als die Micro-Operations und daher zeitlich näher liegt. Sein Ursprung liegt im Trace-Cache, den Intel im Pentium 4 implementiert hat. Er ist eine Erweiterung des First-Level-Cache für Instruktionen, der die Korrelation zwischen den verschiedenen Instruktionen und den Mikrooperationen speichert, in die sie zuvor vom Steuergerät zerlegt wurden .

Allerdings hatte die x86-ISA schon immer ein Problem mit dem RISC-Typ, während letztere eine feste Befehlslänge im Code haben, kann bei x86 jeder zwischen 1 und 15 Bytes messen. Wir müssen bedenken, dass jede Anweisung in mehreren Mikrooperationen abgerufen und decodiert wird. Dazu wird schon heute ein hochkomplexes Steuergerät benötigt, das ohne die notwendigen Optimierungen bis zu einem Drittel seiner Energieleistung verbrauchen kann.
Der Micro-Operation-Cache ist somit eine Weiterentwicklung des Trace-Cache, aber er ist kein Teil des Instruktions-Cache, sondern eine hardwareunabhängige Einheit. In einem Mikrooperations-Cache ist die Größe jedes von ihnen in Bezug auf die Anzahl der Bytes festgelegt, sodass beispielsweise eine CPU mit ISA x86 so nah wie möglich an einem RISC-Typ arbeiten und die Komplexität der Steuereinheit und damit reduzieren kann Verbrauch. Der Unterschied zum Pentium 4-Plot-Cache besteht darin, dass der aktuelle Micro-Op-Cache alle Micro-Ops, die zu einer Anweisung gehören, in einer einzigen Zeile speichert.
Wie funktioniert es?
Was der Mikrooperations-Cache tut, ist, die Arbeit des Decodierens der Anweisungen zu vermeiden, so dass, wenn der Decoder gerade diese Aufgabe ausgeführt hat, das Ergebnis seiner Arbeit in dem Cache gespeichert wird. Auf diese Weise wird, wenn es erforderlich ist, den folgenden Befehl zu decodieren, gesucht, ob die Mikrooperationen, die ihn bilden, in dem Cache vorhanden sind. Die Motivation dafür ist nichts anderes als die Tatsache, dass es weniger Zeit in Anspruch nimmt, den Cache zu konsultieren, als eine komplexe Anweisung nicht zu zerlegen.
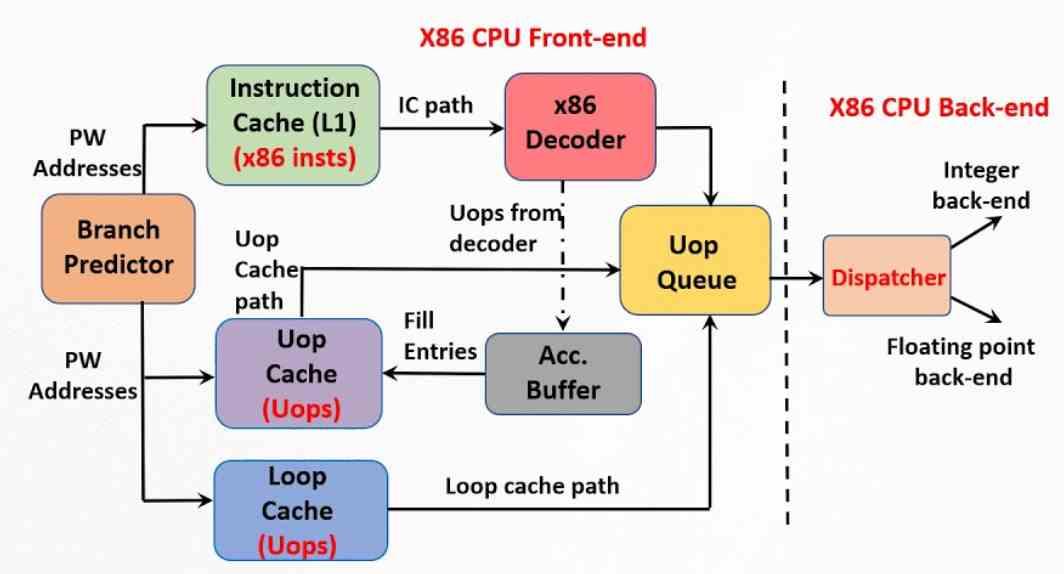
Es funktioniert jedoch wie ein Cache und sein Inhalt wird im Laufe der Zeit verschoben, wenn neue Anweisungen eintreffen. Wenn es eine neue Anweisung im Anweisungs-Cache der ersten Ebene gibt, wird der Mikrooperations-Cache durchsucht, wenn er bereits decodiert ist. Wenn nicht, fahren Sie wie gewohnt fort.
Die gebräuchlichsten Anweisungen sind nach der Zerlegung normalerweise Teil des Mikrooperations-Cache. Was jedoch dazu führt, dass weniger verworfen werden, ist, dass diejenigen, die sporadisch verwendet werden, häufiger verworfen werden, um Raum für neue Anweisungen zu lassen. Im Idealfall sollte die Größe des Microoperation-Cache groß genug sein, um alle zu speichern, aber klein genug, damit die Suche darin nicht die Leistung der CPU beeinträchtigt.