
The Zen 3 architecture, which is used by the AMD Ryzen 5000, both on the desktop and in some processors in the notebook range, is currently the most powerful and advanced CPU architecture on the market. But what secrets does it hide inside to achieve that performance?
Regardless of whether we are talking about a chiplet-based CPU or a monolithic processor, the changes that we are going to describe are general for all AMD processors based on Zen 3.
The cores of the AMD Zen 3 architecture

In order to understand the reason for the changes in performance regarding Zen 2 compared to Zen 3, we must understand in advance that the 19% increase in the IPC is the product of placing both processors under a test or several performance tests and take an average of the performance of both architectures.
At first glance Zen 3 may seem like a slightly improved version of Zen 2, since the changes are in parts of the processor that are usually invisible when talking about the performance of a processor, these changes have been made especially in the unit of control or front-end of the processor.
Front-end improvements for Zen 3 cores
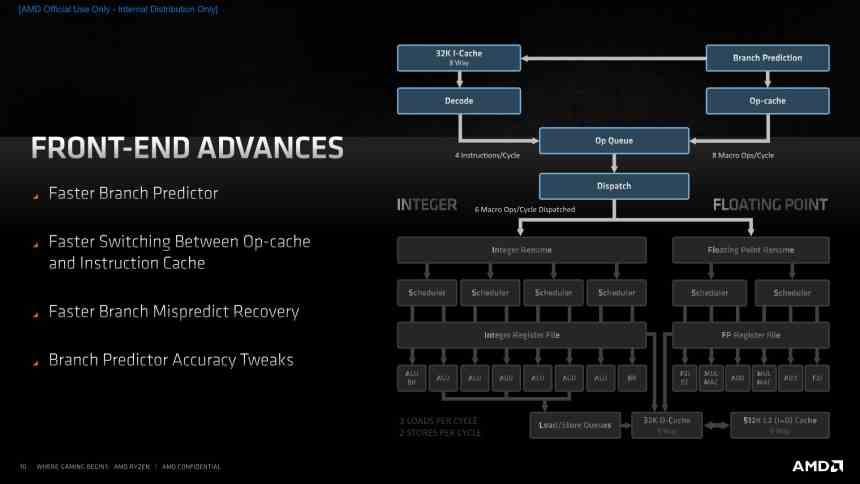
Among the novelties in the Front-End of the processor, the component that stands out the most is the new jump prediction unit, Branch predictor, which has been improved so that it can predict more branches per clock cycle. series of changes in the processor, such as a redesign of the Branch Prediction Buffer BTB, which is located both in the L1 cache, since the number of entries has increased from 512 to 1024, and in the L2 cache it has decreased from the 7K to the 6.5K entries compared to Zen 2.
The new jump prediction unit reduces the number of cycles lost when the processor makes a failed prediction, thus preventing cores from sitting for much longer when the jump prediction unit fails.
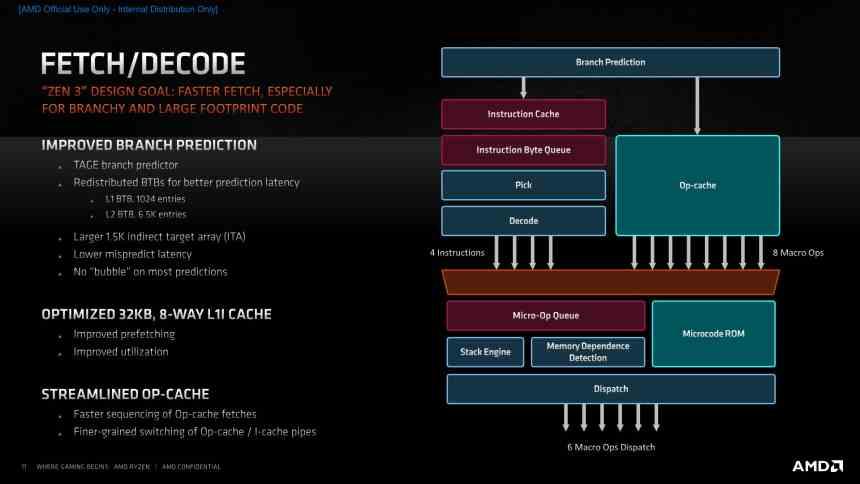
On the other hand. We cannot forget that processors with Zen 3 architecture use the x86-64 set of registers and instructions, which means that we are dealing with a CISC-type ISA. One of the advantages of CISC register and instruction sets is that they bundle several simple instructions into a single complex one, which saves on code space and energy when reading from RAM.
Unfortunately they have the disadvantage that they are very difficult to segment in order to create a pipeline, that is why complex instructions have to be decoded into simpler internal instructions called uops or micro-operations, that is, it is necessary to decode the x86- instructions. 64 in a simpler type of instructions in order to allow segmenting them more easily and being able to implement a pipeline.

In RISC processors the number of bytes per instruction is always the same, but in an ISA such as the x86-64 they are of different sizes, which makes it extremely complex to decode the different instructions and in some instructions specifically the amount number of cycles to decode an instruction is too high. That is why it is necessary to implement a type of cache that allows faster acceleration work, the so-called uop cache, which also reduces the energy consumed during the instruction decoding stage.
We do not know to what degree AMD has improved the uop cache and its communication, but it is one of the key pieces in order to improve performance in x86-64 processors and one of the points that AMD mentions that it has improved compared to Zen 2.
Execution Units in Zen 3
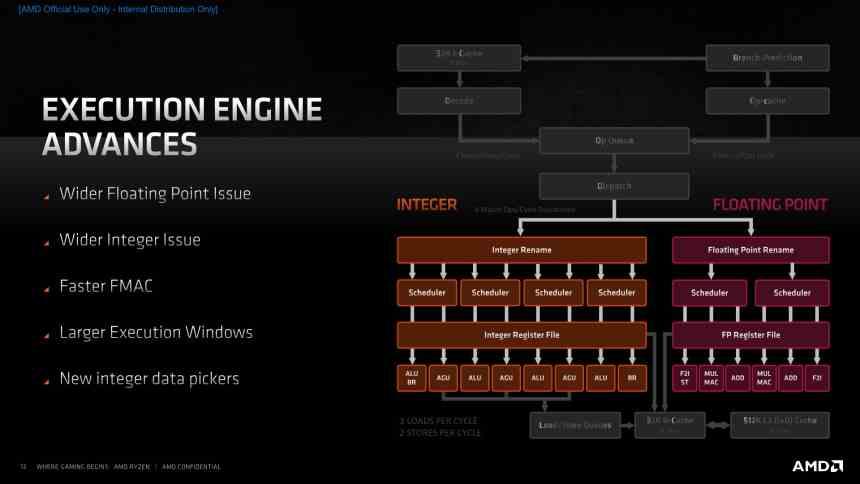
When it comes to sending instructions, Zen 3 still has a Dispatch unit that sends 6 Macro-Ops per cycle to the execution units, so the maximum CPI per core remains at 6 and in theory has not increased. As a curiosity, the Front-End of the processor is equipped to send 8 instructions simultaneously, which suggests that it is possible that in a future iteration of the Zen architecture we could see an increase in performance through increasing the number of units of execution, but in Zen 3 it is used to
But increasing the number of execution units is not the only way to increase the number of simultaneous instructions per cycle that a processor can execute. Since one of the problems faced by architects in charge of designing a processor is the amount of resources available to build the entire architecture, this often leads to different instructions that share the same path when it comes to run.
If two instructions that are working in parallel use the same path until they are resolved, then a contention occurs where one of the instructions ends up slowing down the execution of the other, due to the fact that there is a part in the pipeline that is shared by others. which ends up negatively affecting the amount of instructions per cycle and with it the performance of the processor.
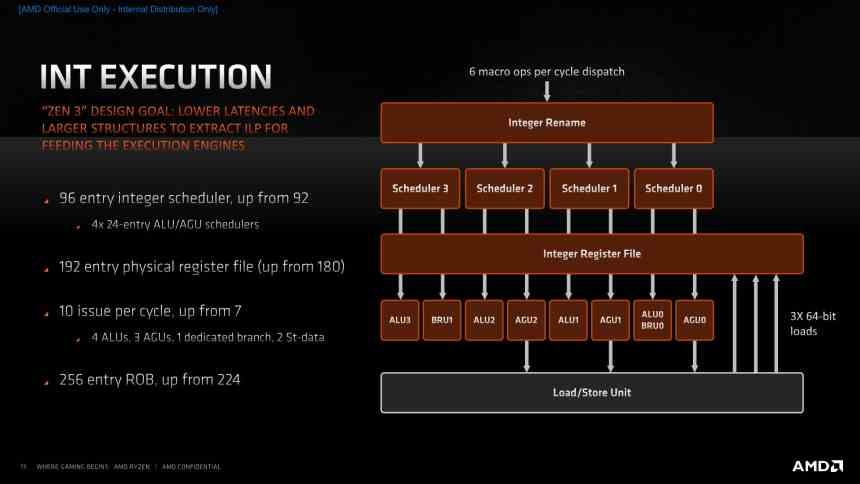
The idea of adding new paths so that there are no conflicts when executing certain instructions is important in order to increase the real IPC of an architecture. This is the case of the units of integers in Zen 3 where the number of paths that can be followed by instructions that make use of the unit of integers from 7 to 10 have been expanded in order to avoid contention between instructions.

Other possible changes are the fact of redesigning the internal operation of certain instructions, making them take fewer cycles to execute, as is the case of the FMAC instruction in floating point units, which has gone from having a latency of 5 clock cycles to only 4 clock cycles.
The other type of unit that AMD has improved in Zen 3 are the so-called Load / Store, in charge of loading and storing data from and to the processor. Load units can load up to 3 data or instructions simultaneously each, so there has been a 50% increase over Zen 2, while storage units have gone from 1 to 2 with 64 storage slots.
The new 8-core CCX

AMD has completely reorganized the CCX for the first time in Zen architectures, instead of being built around 4 cores, it is now around 8 cores, which involve changes, especially in the L3 cache, which is now unified and shared not by 4 but by 8 cores.
The L3 Cache in Zen architectures is a Victim Cache, this means that it adopts the cache lines discarded by the L2 cache inside, this means that the L3 cache does not participate in the demand and capture of data and instructions from memory. So the advantage when using 8 cores is to communicate cores that were previously in different CCXs, communication in that aspect has improved.
Keep in mind that we can find several threads of execution that interoperate with each other, if the communication distance between the different cores that execute the same instruction increases, then the execution time also. It does not matter if one core is faster than the other since the slower one will slow down the faster one. That is why AMD has unified the 8 cores in a single CCX, in order to avoid latencies due to interoperability between cores.
Few changes to the processor Northbridge

Compared to Zen 2, the changes from the Northbridge, or Scalable Data Fabric according to AMD jargon, are few.
- In the case of the Ryzen 5000 for desktop, based on chiplets, the changes with respect to the IOD of the Ryzen 3000 are almost nil, except in the support of faster DDR4 memories than those supported by Zen 2, as well as better optimization in the matter. to energy consumption.
- The same can be said for monolithic SoCs based on Zen 3, except for the new CCX, the rest of the processor is the same as those based on Zen 2.
Actually, we should see a new SDF or IOD with the arrival of DDR5 memory and new I / O standards such as PCIe 5.0, but this should arrive at the same time that AMD launches the Zen 4 architecture or we may find ourselves with a Ryzen 6000 series with a new IOD, but using Zen 3 cores, but that can only be told by AMD.